The world's cloud computing service giant chose Apache Doris + Apache Iceberg to upgrade its data platform into a flexible, efficient data lakehouse with low costs. This solution handles reporting and BI, federated analysis, log storage and analysis, and high-concurrency analysis. With Apache Doris, this company has successfully launched 20+ projects with 50+ clusters, 3000+ nodes, and over 15 petabytes of data.
How Apache Doris Addressed Challenges?
Previously, this company adopted a separated data warehouse and data lake architecture, which led to data silos, poor query performance, and severe operational complexity.
Powered by Apache Doris and Apache Iceberg, a flexible, efficient data lakehouse was established:
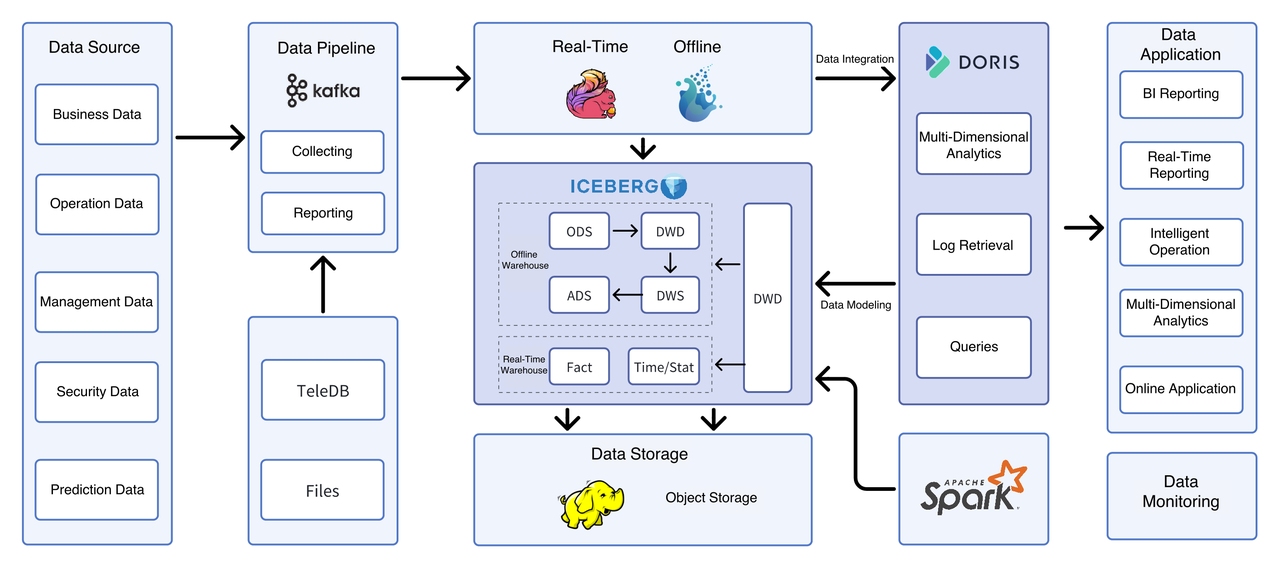
Doris mainly delivered:
Efficient lakehouse queries: Doris could easily connect and efficiently access data in the data lake for query acceleration, and results could be written back to Iceberg, eliminating data silos for higher query efficiency.
Real-time queries: Real-time data streams could be imported directly into Doris tables, ideal for sub-second analysis and queries.
Apache Doris's Applications in Core Scenarios
Real-Time Reporting & Multi-Dimensional Analytics
Doris supports real-time data analytics and ad-hoc queries:
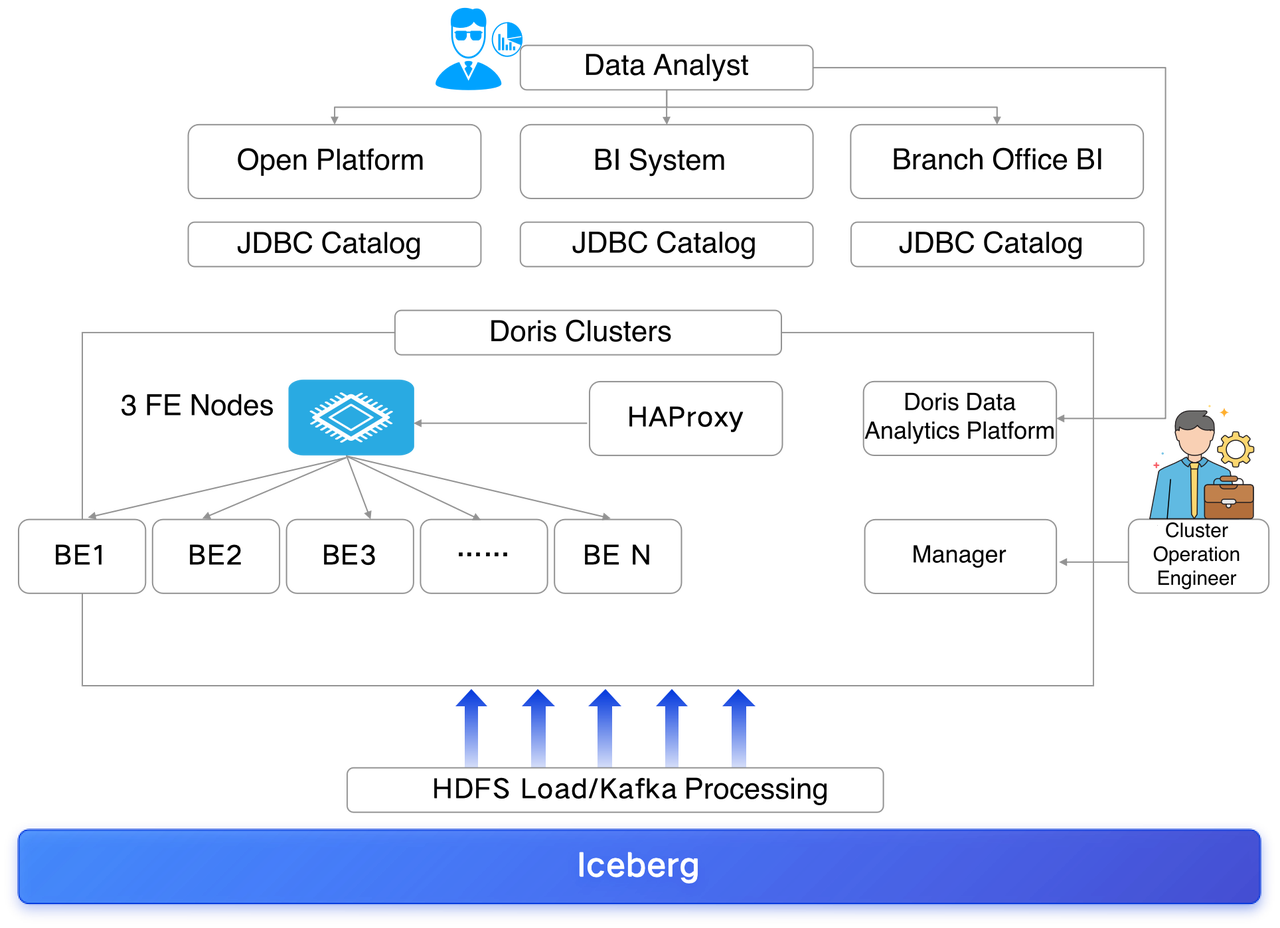
- Higher reporting efficiency: Doris solves instability and insufficient scalability led by the original Impala+Redis architecture, enhancing reporting and data processing efficiency.
- Sub-second queries: Doris improves data retrieval and query performance by replacing the Oracle database and PostgreSQL in the BI system, enabling real-time data analytics for business decision-making.
- Unified technology stack: consolidating multiple technical components into Doris simplifies the architecture, reducing operational complexity.
Lakehouse Federated Analysis
Doris lakehouse architecture:
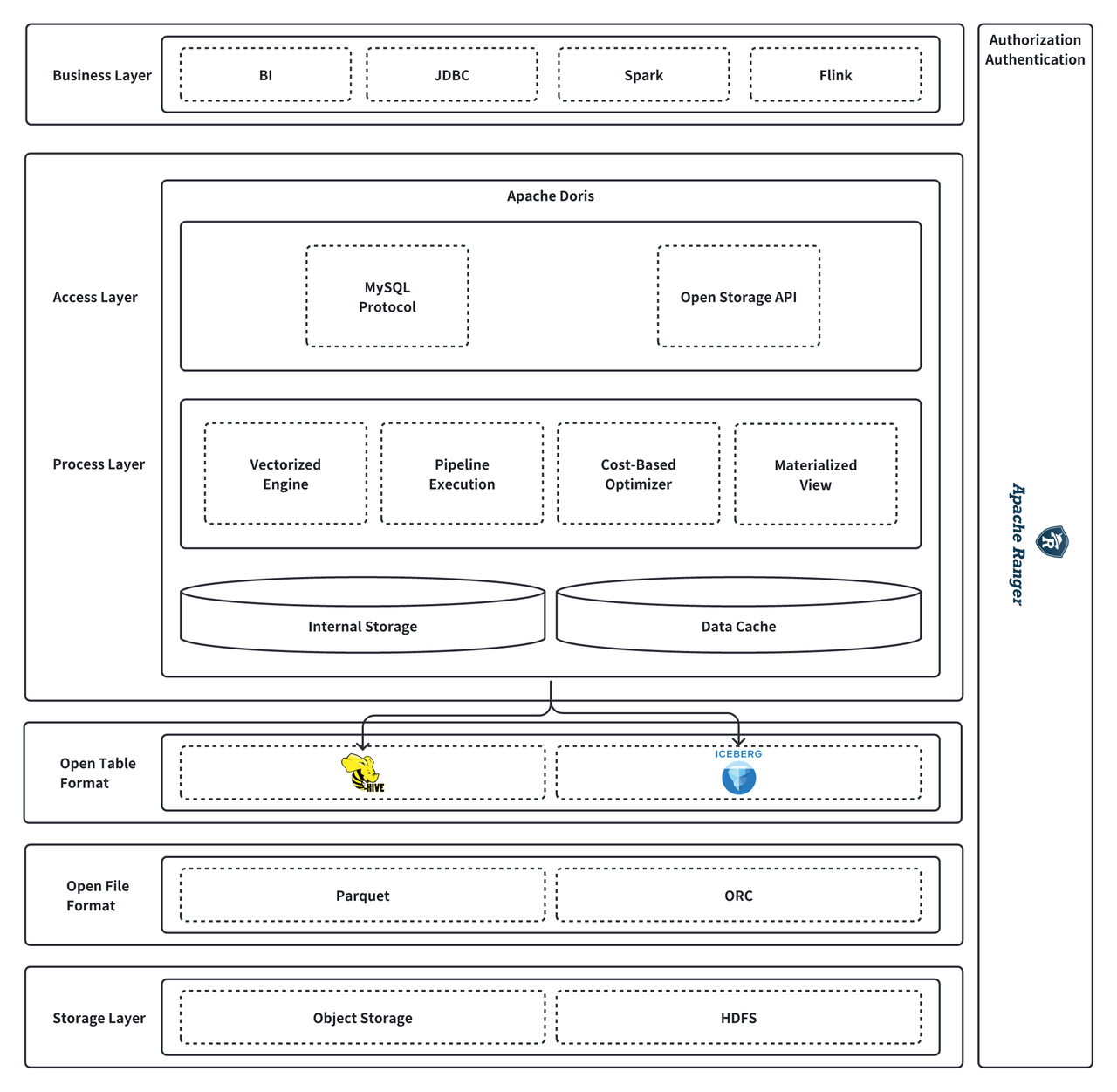
Doris directly accesses data in Iceberg tables for real-time queries, leveraging data cache and materialized views and transparent acceleration for higher query performance. With Apache Ranger's unified management of multiple components, including Doris, Spark, Hive, and Iceberg, and Doris's cross-source federated query capabilities, this data lakehouse delivers consistent, high-performance real-time analytics.
Specifically, Doris enables query performance tuning and data write-back to Iceberg:
Query performance tuning:
Doris supports the lazy materialization of complex types such as Array, Map, and Struct. Lazy materialization allows reading condition columns before filtering, reducing network IO from hundreds of GB to hundreds of MB for faster queries.
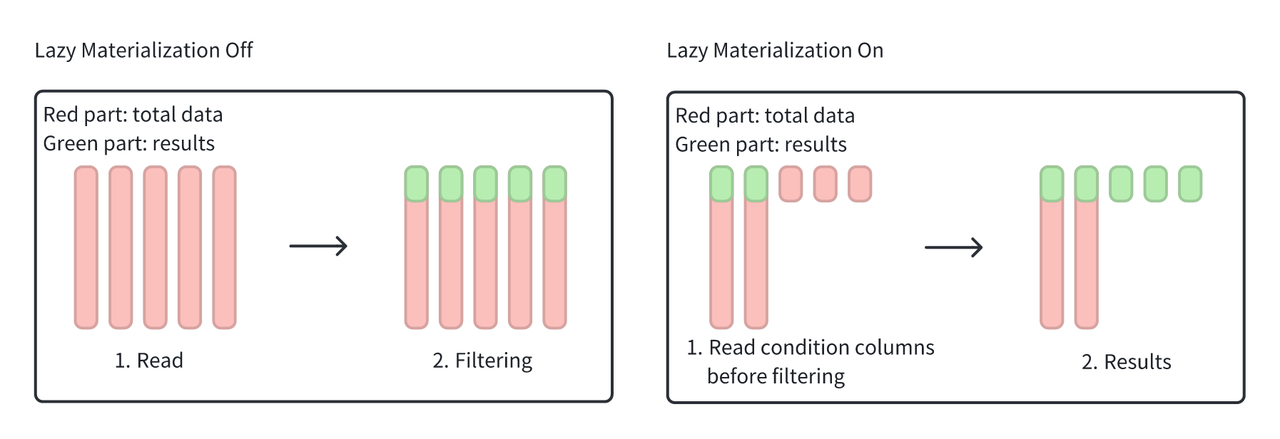
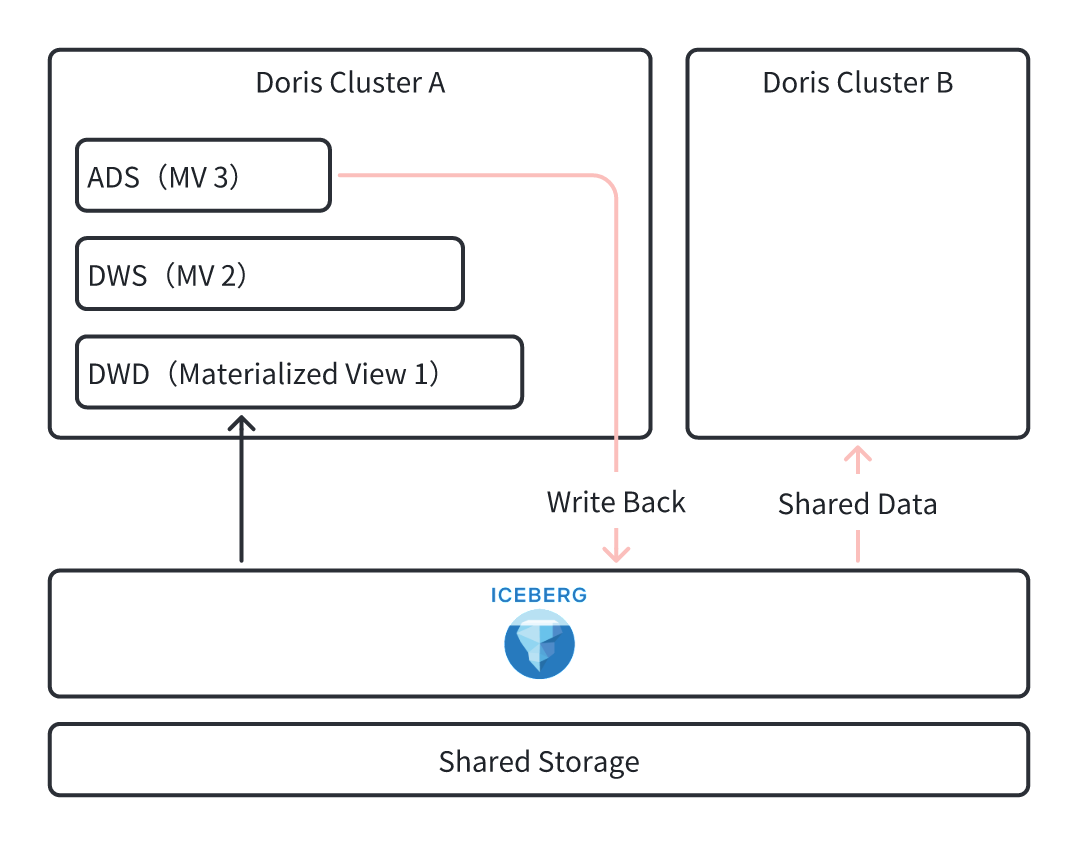
Data write-back to Iceberg:
Users processes data directly in Doris and then writes the results back to Iceberg by leveraging layered data processing in asynchronous materialized views. Based on the shared storage of Iceberg, these results can be seamlessly shared with other Doris clusters.
Log Storage and Analysis
As ELK (Elasticsearch + Logstash + Kibana) struggled with high costs, inefficient queries, and limited scalability when processing large-scale logs, Doris brings improvements:
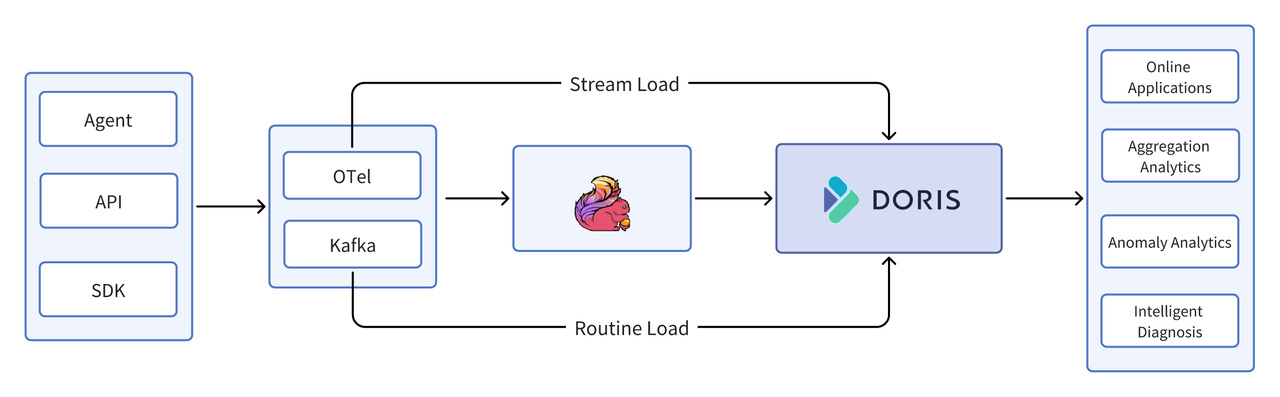
- Large data volumes/critical data: stored in Kafka for traceability, and processed by Flink or imported into Doris through Routine Load
- Small data volumes (less than 10 billion/day): directly imported into Doris through Open Telemetry
Doris achieved 5x higher write throughput, 80% reduction in storage costs, sub-second log retrieval on 10 billion logs, and 3x faster queries.
Artificial Intelligence of Things (AIoT)
The AIoT platform is a real-time data analytics system. It handles 10,000+ concurrent data loads, data tables of 10 billion records, and hundreds of millions of daily incremental data. Most queries return single-row results, demanding high concurrency and low latency. For this, Doris provides significant support:
- Intelligent partitioning & bucketing: Doris's partition pruning and bucketing parallelism can uniform data distribution, reduce the data scanning range, and lower I/O costs for higher query performance.
- Advanced indexing system: Doris supports various rich indexes, such as BloomFilter index and inverted index, to reduce I/O and accelerate queries.
- Efficient batch loading: users can batch data (from several MB to GB in size) on the client side before loading, avoiding severe write amplification issues caused by high-frequency small loads. For high-concurrency small data volume loading, users can implement server-side batching with Group Commit for lower loading costs.
With Doris, the AIoT platform achieved average QPS 8,000 and peak QPS 15,000.
The Future: Seamless Migration to Apache Doris
This company will explore Doris further:
- Introducing Doris compute storage decoupled mode: addressing challenges such as data sharing, tiered storage, and resource isolation in business scenarios.
- Accelerating Doris's adoption: applying Doris in data analytics, log retrieval, and ad-hoc query scenarios to accelerate digital transformation.
- Engaging in Doris community: collaborating to support the development of metadata, Catalog, CCR, and Doris compute storage decoupled mode for sustainable progress.