



A heartfelt thank-you to Parth Soni, Senior Data Engineer at Planet (a company in the payment space), AWS Solutions Architect, open source contributor, and passionate Data & AI Evangelist. Parth recently completed a successful migration from Snowflake to Apache Doris, which is now running in production. In our recent VeloDB Webinar, he generously shared his firsthand experiences and technical insights from this journey, offering practical suggestions that inspire many in the Apache Doris community. To help more users benefit from his talk, we’ve put together this article based on his presentation. We’re deeply grateful for Parth’s time, expertise, and generosity.
As Parth said at the beginning of his talk, "I went through that roller coaster ride of migration, so I would be really glad to share this out. I'll be sharing the hands-on experience about all the lessons, gratifying wins, and some moments that my team are reaching for a comforting cup of coffee."
Original data architecture
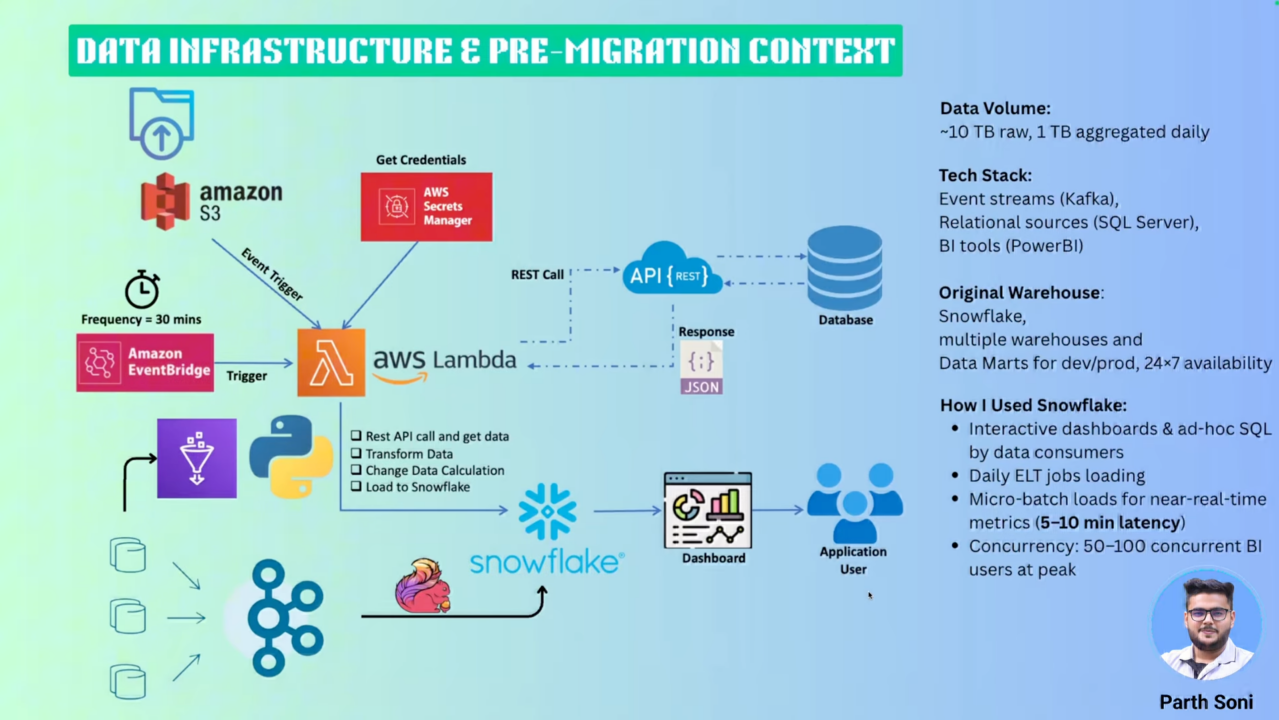
In Parth and his team's use case, this data architecture was designed to support high-volume real-time analytics, processing over 3 billion user-generated events per day. That's equivalent to 1 TB of aggregated data and 10 TB of raw data daily.
At a high level, the pipeline includes:
- Event ingestion via Kafka, which streams data into Flink and Snowflake for further processing
- Transactional data captured using Change Data Capture (CDC)
- External data sources integrated through APIs, with data pushed into Snowflake
- Batch data loads from Amazon S3 into the platform
- Daily ETL jobs running
Snowflake served as the central analytical layer, enabling fast access to curated data for business users and stakeholders. It powered interactive dashboards and ad-hoc SQL queries, making it a core component for downstream consumption and insights delivery.
Challenges with Snowflake
- Concurrency and cost management: Snowflake's pay-per-query model, while flexible, resulted in unpredictable expenses during usage surges. During peak usage, especially when 50 to 100 BI users query simultaneously, concurrency demands spiked, leading to significant cost increases.
- Latency in real-time processing: Although designed for real-time analytics, the system exhibited a 5–10 minute delay in event visibility due to micro-batch loading and the inherent latency in Snowflake's "near real-time" processing. This made it difficult to meet strict real-time expectations.
- Scalability vs. cost trade-offs: As data volume continues to grow, both performance and costs scale up. Spinning up multi-cluster virtual warehouses to handle high concurrency proved shockingly expensive, challenging the cost-effectiveness of the architecture.
- Vendor lock-in and organizational constraints: The organization faced vendor lock-in issues, including contractual restrictions and compliance concerns from the legal team, driving interest in open-source alternatives or self-hosted solutions (e.g., on AWS EC2).
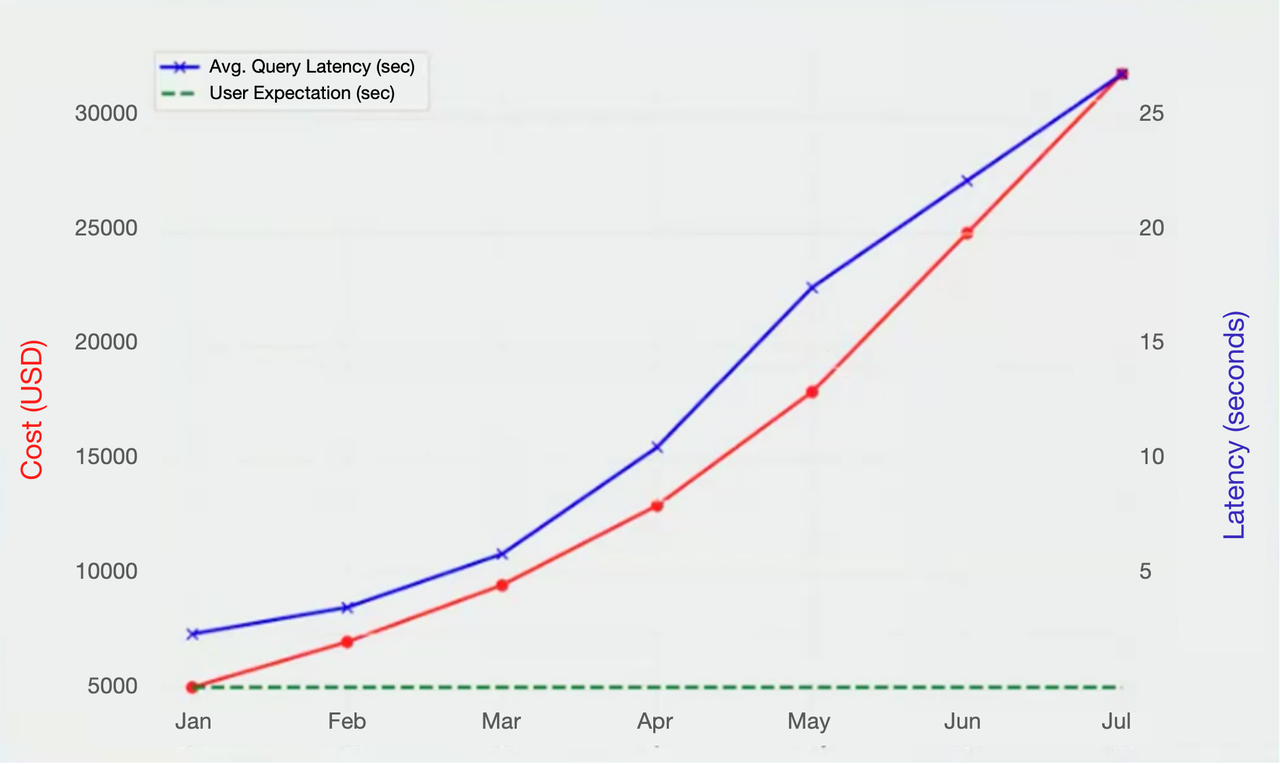

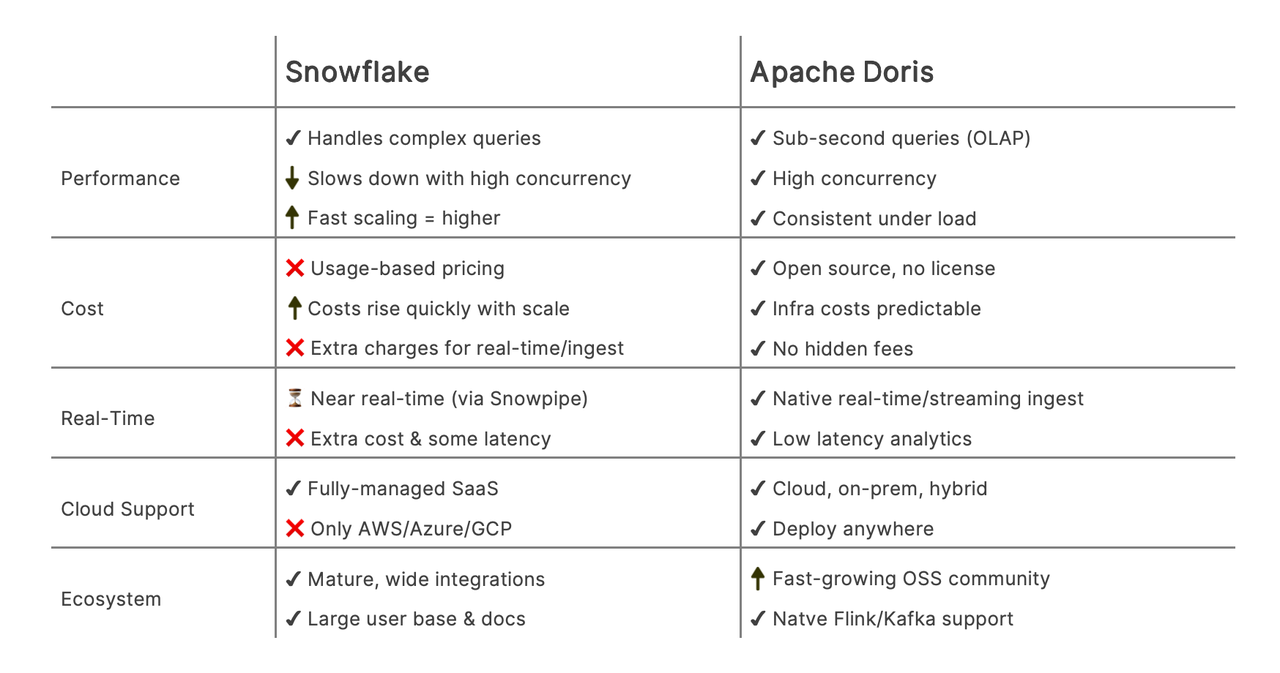
Why Apache Doris
The decision to adopt Apache Doris was driven by a combination of performance, flexibility, integration capabilities, and cost-effectiveness. The user conducted a bake-off and proof of concept (POC) comparing Apache Doris and ClickHouse, evaluating them based on several key criteria:
- Total Cost of Ownership (TCO): While open-source tools come with some operational overhead, Apache Doris offered a favorable balance between capability and control, without incurring the unpredictable costs associated with SaaS platforms.
- Query performance & low latency: Apache Doris delivers sub-second query speeds powered by columnar storage and a vectorized execution engine, enabling fast and reliable analytics for real-time and ad-hoc use cases, and it delivers consistent performance under load.
- Operational simplicity & flexibility: The system proved easy to deploy and maintain on EC2, with support for custom storage formats and user-defined functions, allowing greater control over the architecture and governance.
- Real-time analytics & ecosystem integration: Apache Doris offered native support for Kafka, Flink, and Spark.
- Community support: Strong engagement from the open-source community helped accelerate adoption and problem-solving.
Migration Strategy
As for the migration process, Parth introduces his well-defined, phased strategy to ensure stability and performance throughout the process.
- It began with a thorough assessment and planning phase, which involved auditing existing queries, analyzing schema complexity, and mapping Snowflake data types to Apache Doris equivalents. This step helped create a clear picture of the migration scope and stakeholder requirements.
- The next phase was data export and loading. Data was exported from Snowflake in Parquet format and loaded into Apache Doris, followed by validation through QA and data audits to ensure consistency and accuracy.
- For ETL migration, the user leveraged the Doris Kafka Connector and Flink Doris Connector: the former Routine Loads, and the latter for more complex ETL workflows. This enabled smooth integration with existing streaming data pipelines.
- Subsequently, query and SQL dialect conversion was undertaken to align stored procedures and queries with Doris syntax.
- The final stage focused on parallel validation and performance testing, comparing Apache Doris and Snowflake under real-world conditions. This helped confirm the improvements and ensured production readiness.
Phase 1: Schema & data model transformation
The first phase of migration focused on schema and data model transformation. ETLs were extracted from Snowflake, and all data types were translated into their Apache Doris equivalents. To ensure optimal performance, the team revisited partition keys, distribution columns, and defined primary and unique keys to improve ingestion efficiency.
Automation played a key role. Python scripts and Jinja templates were used to streamline schema conversion, and Airflow orchestrated the batch data workflows.
Phase 2: ETL/ELT pipeline redesign
The second phase involved ETL and ELT pipeline redesign. For batch loads, data was exported as Parquet files, staged on S3, and loaded into Apache Doris using LOAD DATA INFILE.
For real-time ingestion, the team adopted the Doris Stream Load API, which offered rich functionality for managing streaming data. Additionally, micro-batches using Spark were used for large-scale backfills.
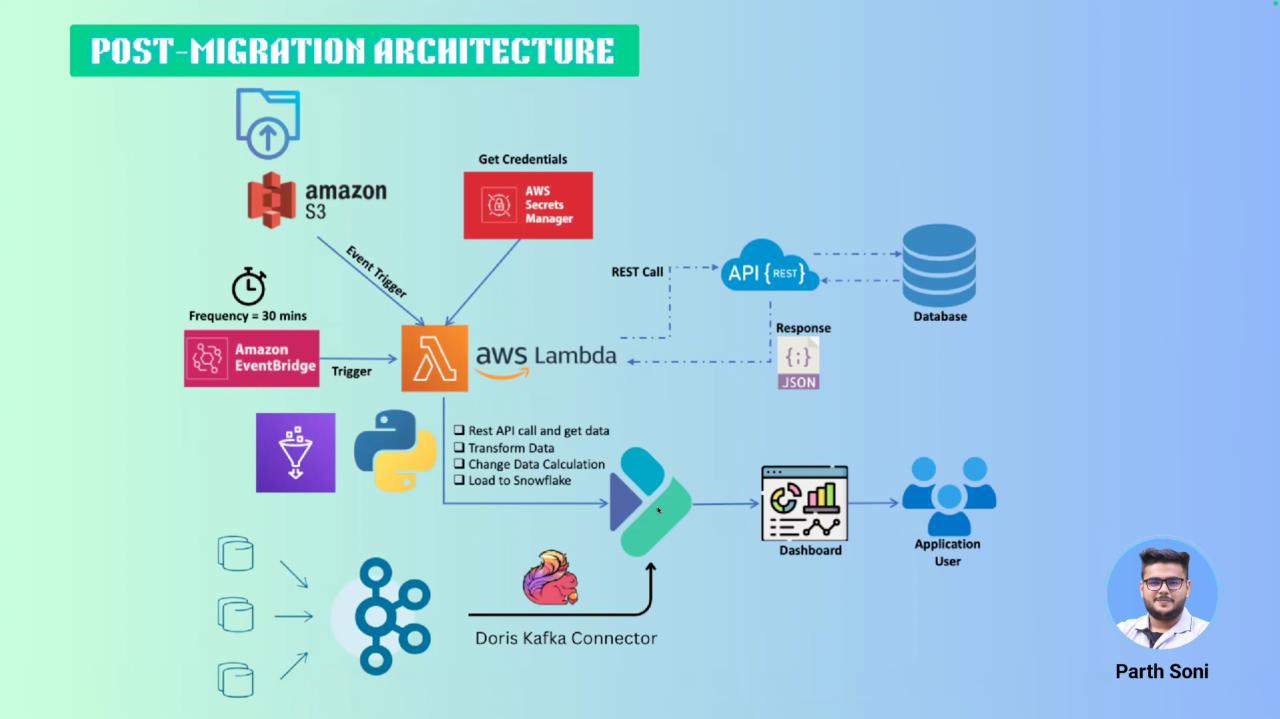
New data architecture
After the migration, Snowflake has been fully replaced by Apache Doris as the primary analytics warehouse. The rest of the data architecture remains unchanged. Currently, Doris is running in production and performing reliably. Parth is also exploring Doris' capabilities for log analytics through a POC.
Performance benchmarks & cost comparison
After migrating to Apache Doris, Parth conducted a series of performance benchmarks across real-world analytical scenarios:
- In standard OLAP tests involving 20 million rows, Apache Doris returned results in 0.9 seconds, compared to 5 seconds on Snowflake, so Apache Doris is more than 4.6 times faster.
- When testing a larger table containing 475 million records, Apache Doris completed queries in just 1–3 seconds, while Snowflake required 45–90 seconds, showing a 15x performance advantage.
- For multi-table JOINs, Apache Doris handled the queries in 1.5 seconds, outperforming Snowflake's 8 seconds.
- In high-concurrency queries, where 100 user dashboards queried a 20 million row table, Apache Doris maintained an average response time of 1.2 seconds, again demonstrating superior performance.
- One of the most notable improvements was in micro-batch loading. Snowflake showed 5–10 minutes of ingestion latency, whereas Apache Doris delivered data in 1–2 seconds through its native real-time capabilities.
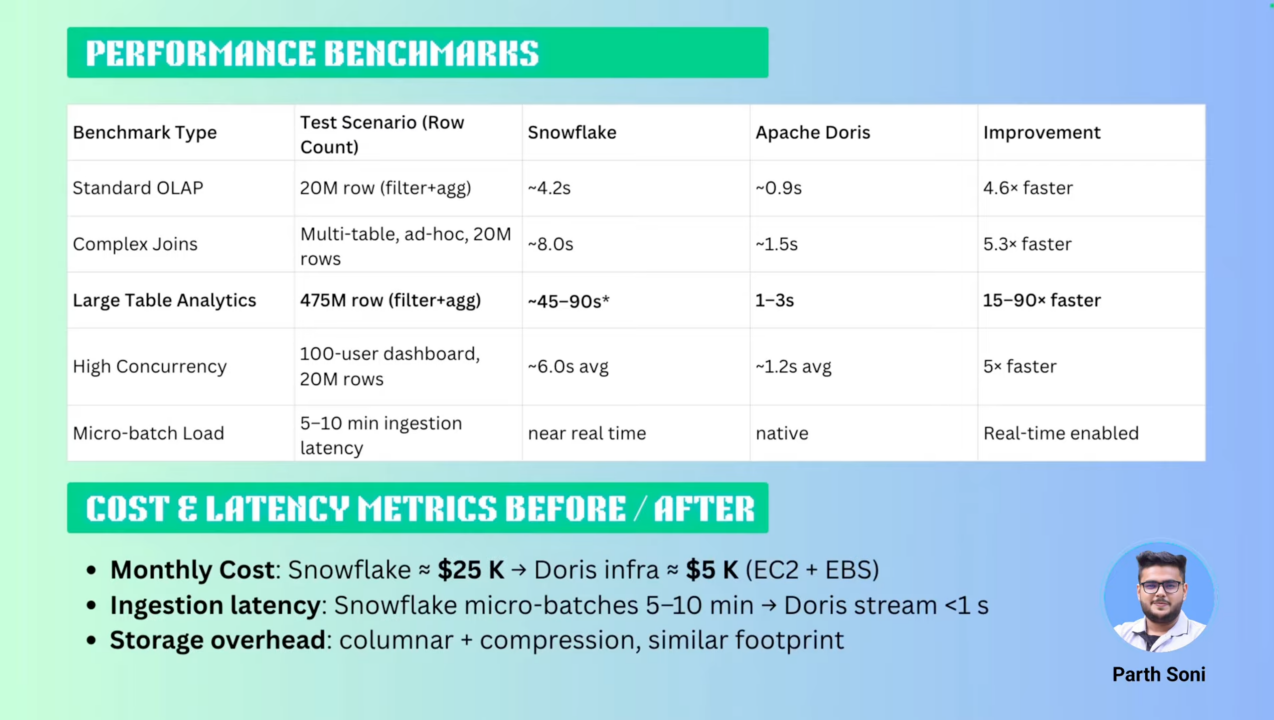
Parth also compared the costs before and after the migration. In June, the monthly expenses for Snowflake were approximately $25,000 USD. After moving to Apache Doris, which is deployed on AWS EC2 and EBS infrastructure, the total monthly cost dropped to around $5,000 USD, achieving a 5x cost reduction.
While the shift to Apache Doris involves managing infrastructure and owning the cost of compute and storage, Parth found the tradeoff worthwhile. Beyond cost, Apache Doris also delivered real-time capabilities that Snowflake could not, making it a compelling choice both economically and technically.
Lessons learned and best practices
Parth also generously shares his lessons learned while migrating from Snowflake to Apache Doris:
- Schema drift: This is common when migrating from one technology to another. Inconsistent data definitions caused early pipeline failures. Enforcing strict DDL contracts helped prevent type mismatches and ensured stability during ingestion.
- Data skew: Initial performance bottlenecks were traced to uneven data distribution. Switching from single-column to multi-column distribution largely improved query performance by balancing tablet sizes.
- Resource tuning: Tuning BE memory limits, JVM heap sizes, and RPC thread configurations was essential to avoid out-of-memory (OOM) errors.
- Backfill quirks: Segment compaction must be tuned to avoid OOM.
Despite these initial hurdles, the performance and cost benefits made the effort worthwhile.
And some best practices share by Parth:
- Use BITMAP and Bloom Filters for high-cardinality dimensions
- Define sensible tablet row-count (e.g. 100K rows per segment)
- Set replication factor more than 3 for high availability
- Leverage Materialized Views for common aggregations
- Monitor compaction / clean-up cycles to prevent stale segments
POC worth doing!
Parth encouraged teams to evaluate whether their current architecture delivers the real-time visibility their business requires at a sustainable cost. If not, he recommended setting aside a couple of development sprints to run a proof of concept with Apache Doris on critical workloads. Based on his experience, the results may exceed expectations!
The Apache Doris team provides free technical support in the Slack community. Everyone is welcome to join the conversation!
If you're interested in Apache Doris' real-time performance but prefer to avoid the overhead of managing infrastructure yourself, check out VeloDB Cloud, a fully managed solution built on Apache Doris.


