



We are excited to announce the official release of Apache Doris 3.1, a milestone version that makes semi-structured data and lakehouse analytics more powerful and practical.
Doris 3.1 introduces sparse columns and schema template for the VARIANT data type, allowing users to efficiently store, index, and query datasets with tens of thousands of dynamic fields, ideal for logs, events, and JSON-heavy workloads.
For lakehouse capabilities, Doris 3.1 brings better asynchronous materialized view into lakehouse, building a stronger bridge between data lakes and data warehouses. It also expands support for Iceberg and Paimon, making complex lakehouse workloads easier and more efficient to manage.
More than 90 contributors submitted over 1,000 improvements and fixes during the development of Apache Doris 3.1. We'd like to send a big heartfelt thank you to everyone who contributed through development, testing, and feedback.
Download Apache Doris 3.1 on GitHub
Download from the official website
Key Highlights in Apache Doris 3.1
- Semi-Structured Data Analytics
- Sparse columns for the VARIANT type, supporting tens of thousands of subcolumns.
- Schema template for VARIANT, delivering faster queries, more stable indexing, and controllable costs without losing flexibility.
- Inverted Indexes Storage Format upgrade from V2 to V3, reducing storage usage by up to 20%.
- Three new tokenizers: ICU Tokenizer, IK Tokenizer, and Basic Tokenizer. We also added support for custom tokenizers, greatly improving search recall across diverse scenarios.
- Lakehouse Upgrades
- Better materialized views features were introduced to data lakes, strengthening the bridge between data lakes and data warehouses.
- Broader support for Iceberg and Paimon.
- Dynamic partition pruning and batch splits scheduling, improve certain query workloads by up to 40% and reduce FE (frontend) memory consumption.
- Doris 3.1 refactors the connection properties for external data sources, providing a clearer way to integrate with various metadata services and storage systems, offering more flexible connectivity options.
- Storage Engine Improvements
- New flexible column updates, building on partial column updates, now allow different columns to be updated for each row within a single import.
- In storage-compute separation scenarios, Doris 3.1 optimizes the lock mechanism for MOW tables, improving the experience of high-concurrency data ingestion.
- Performance Optimizations
- Doris 3.1 enhanced partition pruning and query planning, delivering faster queries and lower resource usage with large partitions (tens of thousands) and complex filtering expressions.
- The optimizer also introduces data-aware optimization techniques, achieving up to 10× performance gains in specific workloads.
1. VARIANT Semi-Structured Data Analytics Get a Major Upgrade
Storage Capabilities: Sparse columns and Subcolumns Vertical Compaction
Traditional OLAP systems often struggle with "super-wide tables" containing thousands to tens of thousands of columns, facing metadata bloat, compaction amplification, and degraded query performance. Doris 3.1 addresses this with sparse subcolumns and subcolumn-level vertical compaction for the VARIANT type, pushing the practical column limit to tens of thousands.
VARIANT brings the following benefits with its thorough optimizations in storage layer:
- Stable support for subcolumns (thousands to tens of thousands) in columnar storage, delivering smoother queries and reducing compaction latency.
- Controllable metadata and indexing, preventing exponential growth.
- Subcolumnarization over 10,000 subcolumns (columnar storage) is achievable in real-world tests, with smooth and efficient compaction performance.
Key use cases for ultra-wide tables:
- Connected Vehicles / IoT Telemetry: Support various device models and dynamically changing sensor dimensions.
- Marketing Automation / CRM: Continuously expanding events and user attributes (e.g., custom events/properties).
- Advertising / Event Tracking: Massive optional properties with sparse and continuously evolving fields.
- Security Auditing / Logs: Diverse log sources have varying fields that need to be aggregated and searched by schema.
- E-commerce Product Attributes: Wide category range with highly variable product attributes.
How it works:
-
Frequent JSON keys become real columns
We automatically keep the most common JSON keys as true columnar subcolumns. This keeps queries fast and metadata small. Rare keys stay in a compact "sparse" area, so the table doesn’t bloat.
-
Smart, low‑memory merges for subcolumns
We merge VARIANT subcolumns in small vertical groups, which uses much less memory and keeps background maintenance smooth even with thousands of fields. Hot keys are detected and promoted to subcolumns automatically.
-
Faster handling of missing values
We batch‑fill default values to cut per‑row overhead during reads and merges.
-
Lean metadata via LRU caching
Column metadata is cached with an LRU policy, reducing memory usage and speeding up repeated access. In short: you get columnar speed for the fields that matter, without paying a heavy cost for the long tail, and background operations stay smooth and predictable.
How to Enable and Use:
New column-level Variant parameter control, column properties:
variant_max_subcolumns_count: Default is 0, which means sparse subcolumn support is disabled. When set to a specific value, the system extracts the Top-N most frequent JSON keys for columnar storage, while the remaining keys are stored sparsely.
-- Enable sparse subcolumns and cap hot subcolumn count
CREATE TABLE IF NOT EXISTS tbl (
k BIGINT,
v VARIANT<
properties("variant_max_subcolumns_count" = "2048") -- pick top-2048 hot keys
>
) DUPLICATE KEY(k);
Schema Templates
Schema templates make constantly changing JSON predictable along critical paths: so queries run faster, indexes stay stable, and costs remain under control, without losing flexibility. Benefits are:
- Type stability: Lock types for key JSON subpaths in DDL to prevent type drift that causes query errors, index invalidation, and implicit cast overhead.
- Faster, more accurate retrieval: Tailor inverted index strategies per subpath (tokenized/non-tokenized, parsers, phrase search) to cut latency and improve hit rates.
- Controlled indexing and costs: Tune indexes per subpath instead of indexing the whole column, significantly reducing index count, write amplification, and storage usage.
- Maintainability and collaboration: Acts as a "data contract" for JSON, semantics stay consistent across teams. Types and index states are easier to observe and debug.
- Easier to evolve: Template and optionally index hot paths, while keeping long‑tail fields flexible, so you scale without surprises.
How to enable and use:
- Explicitly declare common subpaths and types (including wildcards) inside
VARIANT<...>, for example:VARIANT<'a': INT, 'c.d': TEXT, 'array_int_*': ARRAY<INT>>. - Configure per‑subpath indexes with differentiated strategies (
field_pattern,parsers,tokenization,phrasesearch), and use wildcards to cover families of fields at once. - New column property:
variant_enable_typed_paths_to_sparse - Default:
false(typed, predefined paths are not stored sparsely). - Set to true also to treat typed paths as sparse candidates, useful when many paths match and you want to avoid column sprawl.
In short: template what matters, index it precisely, and keep everything else flexible.
Example 1: Schema Definition with Multiple Indexes on a Single Column
-- Common properties: field_pattern (target subpath), analyzer, parser, support_phrase, etc.
CREATE TABLE IF NOT EXISTS tbl (
k BIGINT,
v VARIANT<'content' : STRING>, -- specify concrete type for subcolumn 'content'
INDEX idx_tokenized(v) USING INVERTED PROPERTIES("parser" = "english", "field_pattern" = "content"), -- tokenized inverted index for 'content' with english parser
INDEX idx_v(v) USING INVERTED PROPERTIES("field_pattern" = "content") -- non-tokenized inverted index for 'content'
);
-- v.content will have both a tokenized (english) inverted index and a non-tokenized inverted index
-- Use tokenized index
SELECT * FROM tbl WHERE v['content'] MATCH 'Doris';
-- Use non-tokenized index
SELECT * FROM tbl WHERE v['content'] = 'Doris';
Example 2: Batch Processing Columns Matching a Wildcard Pattern
-- Use wildcard-typed subpaths with per-pattern indexes
CREATE TABLE IF NOT EXISTS tbl2 (
k BIGINT,
v VARIANT<
'pattern1_*' : STRING, -- batch-typing: all subpaths matching pattern1_* are STRING
'pattern2_*' : BIGINT, -- batch-typing: all subpaths matching pattern2_* are BIGINT
properties("variant_max_subcolumns_count" = "2048") -- enable sparse subcolumns; keep top-2048 hot keys
>,
INDEX idx_p1 (v) USING INVERTED
PROPERTIES("field_pattern"="pattern1_*", "parser" = "english"), -- tokenized inverted index for pattern1_* with english parser
INDEX idx_p2 (v) USING INVERTED
PROPERTIES("field_pattern"="pattern2_*") -- non-tokenized inverted index for pattern2_*
) DUPLICATE KEY(k);
Example 3: Allowing Predefined Typed Columns to be Stored Sparsely
-- Allow predefined typed paths to participate in sparse extraction
CREATE TABLE IF NOT EXISTS tbl3 (
k BIGINT,
v VARIANT<
'message*' : STRING, -- batch-typing: all subpaths matching prefix 'message*' are STRING
properties(
"variant_max_subcolumns_count" = "2048", -- enable sparse subcolumns; keep top-2048 hot keys
"variant_enable_typed_paths_to_sparse" = "true" -- include typed (predefined) paths as sparse candidates (default: false)
)
>
) DUPLICATE KEY(k);
1. Inverted Index Storage Format V3
Compared to V2, Inverted Index V3 further optimizes storage:
- Smaller index files reduce disk usage and I/O overhead.
- Testing with httplogs and logsbench datasets shows up to 20% storage space savings with V3, great for large-scale text data and log analysis scenarios.

Key Improvements:
- Introduced ZSTD dictionary compression for inverted index term dictionaries, enabled via
dict_compressionin index properties. - Added compression for positional information associated with each term in the inverted index, further reducing storage footprint.
How to Use:
-- Enable V3 format when creating the table
CREATE TABLE example_table (
content TEXT,
INDEX content_idx (content) USING INVERTED
PROPERTIES("parser" = "english", "dict_compression" = "true")
) ENGINE=OLAP
PROPERTIES ("inverted_index_storage_format" = "V3");
Full-Text Search Tokenizers
We added new commonly used tokenizers in Doris 3.1 to better meet diverse tokenization needs:
- ICU Tokenizer:
- Implementation: Based on International Components for Unicode (ICU).
- Use Cases: Ideal for internationalized text with complex writing systems and multilingual documents.
- Example:
SELECT TOKENIZE('مرحبا بالعالم Hello 世界', '"parser"="icu"');
-- Results: ["مرحبا", "بالعالم", "Hello", "世界"]
SELECT TOKENIZE('มนไมเปนไปตามความตองการ', '"parser"="icu"');
-- Results: ["มน", "ไมเปน", "ไป", "ตาม", "ความ", "ตองการ"]
- Basic Tokenizer
- Implementation: A simple rule-based custom tokenizer, using basic character type recognition.
- Use cases: Simple scenarios or cases with very high performance requirements.
- Rules:
- Continuous alphanumeric characters are treated as one token.
- Each Chinese character is a separate token.
- Punctuation, spaces, and special characters are ignored.
- Examples:
-- English text tokenization
SELECT TOKENIZE('Hello World! This is a test.', '"parser"="basic"');
-- Results: ["hello", "world", "this", "is", "a", "test"]
-- Chinese text tokenization
SELECT TOKENIZE('你好世界', '"parser"="basic"');
-- Results: ["你", "好", "世", "界"]
-- Mixed-language tokenization
SELECT TOKENIZE('Hello你好World世界', '"parser"="basic"');
-- Results: ["hello", "你", "好", "world", "世", "界"]
-- Handling numbers and special characters
SELECT TOKENIZE('GET /images/hm_bg.jpg HTTP/1.0', '"parser"="basic"');
-- Results: ["get", "images", "hm", "bg", "jpg", "http", "1", "0"]
-- Processing long numeric sequences
SELECT TOKENIZE('12345678901234567890', '"parser"="basic"');
-- Results: ["12345678901234567890"]
Custom Tokenization
A new custom tokenization feature lets users design tokenization logic according to their needs, improving recall for text search.
By combining character filters, tokenizers, and token filters, users can go beyond the limitations of built-in analyzers and define exactly how text should be split into searchable terms, directly influencing both search relevance and analytical accuracy.

Example Use Case
- Problem: With the default Unicode tokenizer, a phone number like "13891972631" is treated as a single token, making prefix search (e.g., "138") impossible.
- Solution:
-
Create a tokenizer using the Edge N-gram custom tokenizer:
-
CREATE INVERTED INDEX TOKENIZER IF NOT EXISTS edge_ngram_phone_tokenizer PROPERTIES ( "type" = "edge_ngram", "min_gram" = "3", "max_gram" = "10", "token_chars" = "digit" ); -
Create an analyzer:
-
CREATE INVERTED INDEX ANALYZER IF NOT EXISTS phone_prefix_analyzer PROPERTIES ( "tokenizer" = "edge_ngram_phone_tokenizer" ); -
Specify an analyzer when creating the table
-
CREATE TABLE customer_contacts ( id bigint NOT NULL AUTO_INCREMENT(1), phone text NULL, INDEX idx_phone (phone) USING INVERTED PROPERTIES( "analyzer" = "phone_prefix_analyzer" ) ) ENGINE=OLAP DUPLICATE KEY(id) DISTRIBUTED BY RANDOM BUCKETS 1 PROPERTIES ("replication_allocation" = "tag.location.default: 1"); -
Check tokenization results:
-
SELECT tokenize('13891972631', '"analyzer"="phone_prefix_analyzer"'); +----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | tokenize('13891972631', '"analyzer"="phone_prefix_analyzer"') | +----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | [{ "token": "138" }, { "token": "1389" }, { "token": "13891" }, { "token": "138919" }, { "token": "1389197" }, { "token": "13891972" }, { "token": "138919726" }, { "token": "1389197263" }] | +----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ -
Text search results
SELECT * FROM customer_contacts_optimized WHERE phone MATCH '138'; +------+-------------+ | id | phone | +------+-------------+ | 1 | 13891972631 | | 2 | 13812345678 | +------+-------------+ SELECT * FROM customer_contacts_optimized WHERE phone MATCH '1389'; +------+-------------+ | id | phone | +------+-------------+ | 1 | 13891972631 | | 2 | 13812345678 | +------+-------------+ 2 rows in set (0.043 sec) -
Using the Edge N-gram tokenizer, a phone number is broken into multiple prefix tokens, enabling flexible prefix-matching search.
-
3. Lakehouse Capability Upgrades
Asynchronous Materialized Views Now Fully Support Data Lakes
In version 3.1, asynchronous materialized views have been significantly enhanced, now providing comprehensive support for partition-level incremental maintenance and partition-level transparent query rewriting. This functionality is available for data lake formats like Iceberg, Paimon, and Hudi.
Doris introduced asynchronous materialized views in version 2.1, and we have kept improving, including:

Version 3.1 focuses on strengthening our lakehouse capabilities by providing comprehensive support for partition-level incremental maintenance and partition-level compensation for external tables during query rewriting. This enhancement targets mainstream data lake table formats like Iceberg, Paimon, and Hudi, effectively creating a high-speed data bridge between the data lake and the data warehouse. The detailed scope of support is outlined in the table below.
See specific support details below:
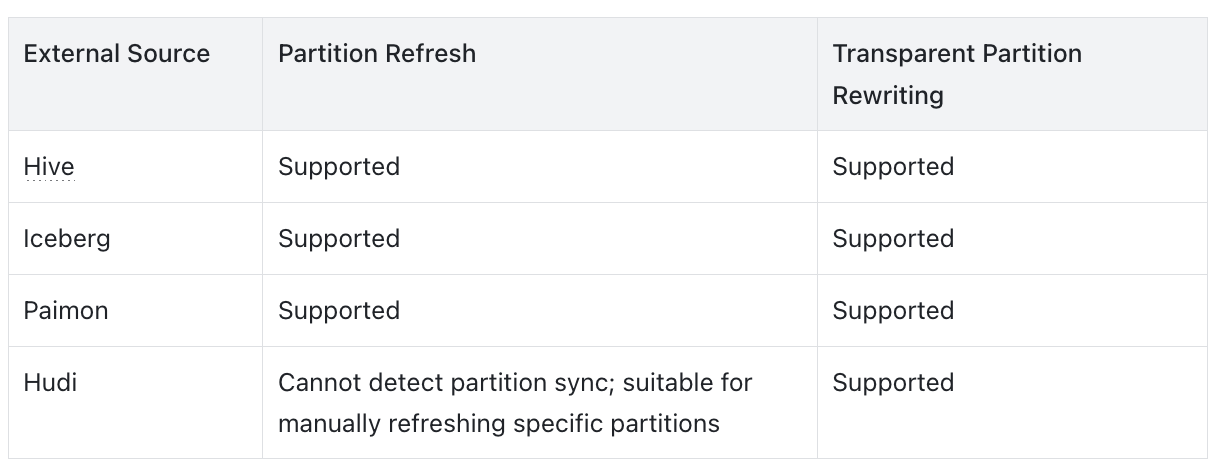
Better Support for Iceberg and Paimon
1. Iceberg
Doris 3.1 introduces a wide range of optimizations and enhancements for Iceberg table format, offering compatibility with the latest Iceberg capabilities.
Branch / Tag Lifecycle Management
Starting in 3.1, Doris natively supports creating, deleting, reading, and writing Iceberg Branches and Tags. Much like Git, this allows users to manage Iceberg table data versions seamlessly. With this capability, users can perform parallel version management, canary releases, and environment isolation, without relying on external engines or custom logic.
-- Create branches
ALTER TABLE iceberg_tbl CREATE BRANCH b1;
-- Write data to a specific branch
INSERT INTO iceberg_tbl@branch(b1) values(1, 2);
-- Query data from a specific branch
SELECT * FROM iceberg_tbl@branch(b1);
Comprehensive System Tables Support
Doris 3.1 adds support for Iceberg system tables such as $entries, $files, $history, $manifests, $refs, $snapshots. Users can directly query Iceberg with commands like SELECT * FROM iceberg_table$history or …$refs to inspect metadata, snapshot histories, branch/tag mappings, and file organization. This dramatically improves metadata observability, making issue diagnosis, performance tuning, and governance more transparent.
You can directly query Iceberg's underlying metadata, snapshot lists, branch, and tag information using statements likeSELECT * FROM iceberg_table$history or …$refs. This allows you to gain in-depth insights into the organization of data files, the history of snapshot changes, and branch mappings. This capability greatly enhances the observability of Iceberg metadata, making it easier and more transparent to troubleshoot issues, perform optimization analysis, and make governance decisions.
Example: querying the number of deleted files via system tables.
SELECT
CASE
WHEN content = 0 THEN 'DataFile'
WHEN content = 1 THEN 'PositionDeleteFile'
WHEN content = 2 THEN 'EqualityDeleteFile'
ELSE 'Unknown'
END AS ContentType,
COUNT(*) AS FileNum,
SUM(file_size_in_bytes) AS SizeInBytes,
SUM(record_count) AS Records
FROM
iceberg_table$files
GROUP BY
ContentType;
+--------------------+---------+-------------+---------+
| ContentType | FileNum | SizeInBytes | Records |
+--------------------+---------+-------------+---------+
| EqualityDeleteFile | 2787 | 1432518 | 27870 |
| DataFile | 2787 | 4062416 | 38760 |
| PositionDeleteFile | 11 | 36608 | 10890 |
+--------------------+---------+-------------+---------+
Support Querying Iceberg View
Doris 3.1 added support for accessing and querying Iceberg logical views, further enhancing Doris's Iceberg capabilities. In future 3.x releases, we plan to add SQL dialect translation support for Iceberg Views.
Schema Evolution with ALTER Statements
Starting in 3.1, Doris supports adding, deleting, renaming, and reordering columns in Iceberg tables through the ALTER TABLE statement. This further empowers Doris to manage Iceberg tables without needing third-party engines like Spark.
ALTER TABLE iceberg_table
ADD COLUMN new_col int;
Additionally, in version 3.1, the Iceberg dependency has been upgraded to version 1.9.2 to better support new Iceberg features. Future 3.1.x releases will further improve Iceberg table management, including data compaction and branch evolution.
Documentation: https://doris.apache.org/docs/lakehouse/catalogs/iceberg-catalog
2. Paimon
Doris 3.1 brings several updates and enhancements to the Paimon table format based on real use cases.
Support for Paimon Batch Incremental Queries
Doris 3.1 allows reading incremental data between two specified snapshots in a Paimon table. This allows users to better access Paimon incremental data, especially enabling incremental aggregation materialized views on Paimon tables.
SELECT * FROM paimon_tbl@incr('startSnapshotId'='2', 'endSnapshotId'='5');
Branch and Tag Reading
From 3.1 and onwards, Doris supports reading Paimon table data from branches and tags, offering more flexible multi-version data access.
SELECT * FROM paimon_tbl@branch(branch1);
SELECT * FROM paimon_tbl@tag(tag1);
Comprehensive System Tables Support
Similar to Iceberg, 3.1 adds support for Paimon system tables like $files, $partitions, $manifests, $tags, $snapshots. Users can query underlying metadata directly with statements like SELECT * FROM partition_table$files, making Paimon tables easier to explore, debug, and optimize.
For example, we can use system tables to count new data files added per partition.
SELECT
partition,
COUNT(*) AS new_file_count,
SUM(file_size_in_bytes)/1024/1024 AS new_total_size_mb
FROM my_table$files
WHERE creation_time >= DATE_SUB(NOW(), INTERVAL 3 DAY)
GROUP BY partition
ORDER BY new_total_size_mb DESC;
In 3.1, Paimon's dependency is upgraded to version 1.1.1 to better support new features.
Documentation: https://doris.apache.org/docs/lakehouse/catalogs/paimon-catalog
Enhanced Data Lake Query Performance
Doris 3.1 added thorough optimizations for data lake table formats, hoping to provide more stable and efficient data lake analytics in real-world production environments.
- Dynamic Partition Pruning
In multi-table join queries, this feature generates partition predicates from the right-hand table at runtime and applies them to the left-hand table. Pruning unnecessary partitions on the fly reduces data I/O and improves query performance. Doris 3.0 introduced dynamic partition pruning for Hive tables. Now with 3.1, we have expanded this capability to Iceberg, Paimon, and Hudi tables. In test scenarios, queries with high selectivity showed a 30%–40% performance improvement.
- Batch Split Scheduling
When a lakehouse table contains a large number of shards, the Frontend (FE) traditionally collects all shard metadata at once and sends it to the Backend (BE). This can cause high FE memory consumption and long planning times, particularly for queries on large datasets.
Batch shard execution solves this by generating shard metadata in batches and executing them as they are produced. This reduces FE memory pressure, allowing planning and execution to run in parallel and improving overall efficiency. Doris 3.0 added support for this feature on Hive tables, and in 3.1 extended it to Iceberg tables. In large-scale test scenarios, it significantly reduced FE memory usage and query planning time.
Federated Analytics: More Flexible, More Powerful Connectors
In 3.1, Doris restructured its connector properties for external data sources. This makes it easier to integrate with different metadata services and storage systems, while also expanding the range of supported capabilities.
1. More Flexible Data Lake Rest Catalog Support
-
Iceberg REST Catalog
We have improved support for Iceberg REST Catalog. Doris 3.1 now works with multiple backend implementations, including Unity, Polaris, Gravitino, and Glue. We also added support for vended credentials, enabling more secure and flexible credential management. AWS is supported, with GCP and Azure support planned in upcoming releases.
Refer to documentation
-
Paimon REST Catalog
Doris 3.1 introduces support for Paimon REST Catalog via Alibaba Cloud DLF, allowing direct access to Paimon tables managed by the latest DLF versions.
Refer to documentation
2. More Powerful Hadoop Ecosystem Support
- Multi-Kerberos Environment Support
Doris 3.1 allows access to multiple Kerberos authentication environments within the same cluster. Different environments can use separate KDC services, Principals, and Keytabs. Doris 3.1 allows each Catalog to now be configured with its own Kerberos settings independently. This feature makes it much easier for users with multiple Kerberos environments to manage them all through Doris with unified access control.
Refer to documentation
- Multi-Hadoop Environment Support
Previously, Doris only allowed a single Hadoop configuration (e.g., hive-site.xml, hdfs-site.xml) to be placed under the conf directory. Multiple Hadoop environments and configurations are not supported. With Doris 3.1, users can now assign different Hadoop configuration files to different Catalogs, making it easier to manage external data sources flexibly.
Refer to documentation
1. Storage Engine Improvements
In Doris 3.1, we've continued to improve the storage layer, improving performance and stability.
Flexible Column Updates: A New Data Update Experience
Previously, the Partial Column Update feature in Doris required each row in a single import to update the same set of columns. However, in many scenarios, source systems only provide records containing the primary key and the specific columns being updated, with different rows updating different columns. To address this, Doris introduced the Flexible Column Update feature, which greatly simplifies the user's workload of preparing per-column data and improving write performance.
How to Use
- Enable when creating a Merge-on-Write Unique table:
"enable_unique_key_skip_bitmap_column" = "true"
- Specify the import mode:
unique_key_update_mode: UPDATE_FLEXIBLE_COLUMNS
- Doris will automatically handle flexible column updates and fill in missing data.
Example
Flexible column updates allow different rows to update different columns in the same import:
- Delete a row (
DORIS_DELETE_SIGN) - Update specific columns (e.g.,
v1,v2,v5) - Insert new rows with only the primary key and updated columns; other columns use default values or historical data.
Performance
- Test environment: 1 FE + 4 BE, 16C 64GB, 300M rows × 101 columns, 3 replicas
- Import 20,000 rows updating just 1 column (99 columns filled automatically)
- Single concurrency import performance: 10.4k rows/sec
- Resource usage per node: CPU ~60%, memory ~30GB, read IOPS ~7.5k/s, write IOPS ~5k/s
Storage-Compute Separation: MOW Lock Optimization
In storage-compute separation scenarios, updating the Delete Bitmap in MOW tables requires acquiring a distributed lock delete_bitmap_update_lock. Previously, import, compaction, and schema change operations would lock race, causing long waits or failures under high-concurrency imports.
We have added several optimizations to make large-scale, concurrent data ingestion more stable and efficient. These include reducing compaction lock times: cutting p99 commit latency from 1.68 minutes to 49.4 seconds in high-concurrency multi-tablet import tests. We also reduced long-tail import latency by allowing transactions to force-lock after a wait threshold is exceeded.
2. Query Performance Boosts
Enhanced Partition Pruning Performance and Coverage
Doris organizes data into partitions that can be stored, queried, and managed independently. Partitioning improves query performance, optimizes data management, and reduces resource consumption. During queries, applying filters to skip irrelevant partitions (known as partition pruning) can significantly boost performance while lowering system resource usage.
In use cases like log analytics or risk control systems, a single table can have tens of thousands of partitions, or even hundreds of thousands, but most queries only touch a few hundred. Efficient partition pruning is therefore critical for performance.
In 3.1, Doris introduces several optimizations that significantly enhance both the performance and applicability of partition pruning:
- Binary search for partition pruning: For partitions based on a time column, the partition pruning process has been optimized by sorting partitions according to the column values. This changes the pruning calculation from a linear scan to a binary search. In a scenario with 136,000 partitions using a DATETIME partition field, this optimization reduced pruning time from 724 milliseconds to 43 milliseconds, achieving over a 16-fold speedup.
- Add support for a large number of monotonic functions in partition pruning: In real-world use cases, filter conditions on time-partitioned columns are often not simple logical comparisons but complex expressions involving time-related functions on the partition columns. Examples include expressions like
to_date(time_stamp) > '2022-12-22',date_format(timestamp,'%Y-%m-%d %H:%i:%s') > '2022-12-22 11:00:00'. In Doris 3.1, When a function is monotonic, Doris can determine whether an entire partition can be pruned by evaluating the partition boundary values. And Doris 3.1 already supports CAST and 25 commonly used time-related functions, covering the vast majority of filtering conditions on time-partitioned columns. - Full-path code optimizations: Additionally, in Doris 3.1, the entire partition pruning code path has been thoroughly optimized at the code level to eliminate unnecessary overhead.
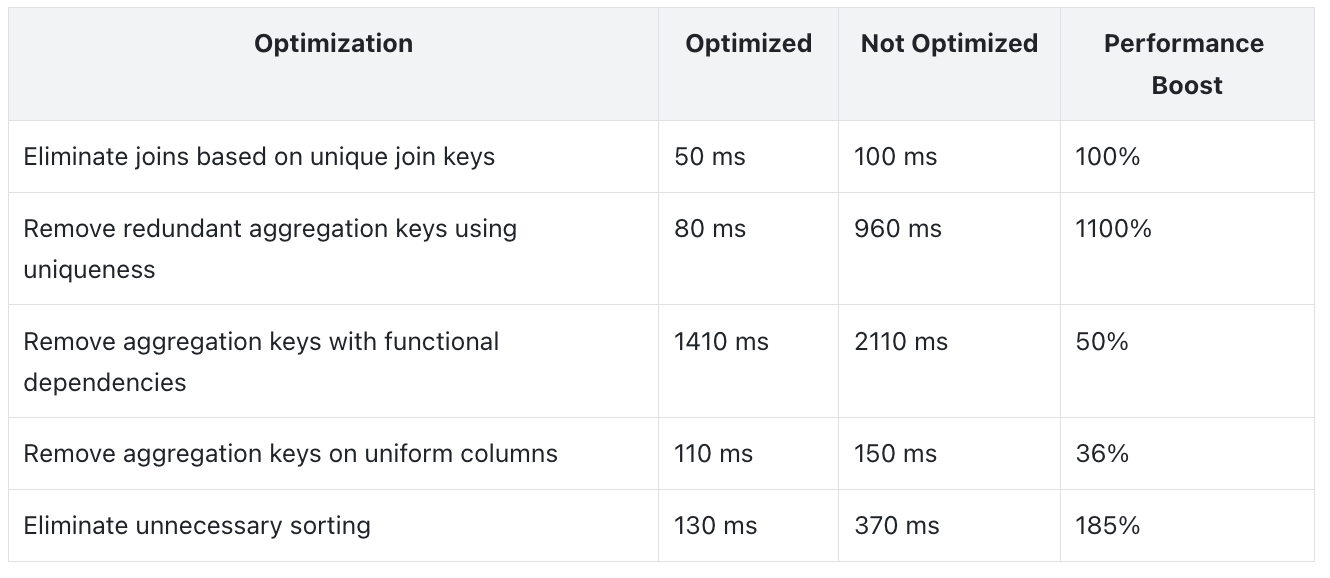
Data Traits: Up to 10× Performance Boost
In Doris 3.1, the optimizer can make smarter use of data traits to enhance query performance. It analyzes each node in the query plan to collect data traits such as UNIQUE, UNIFORM, and EQUAL SET, and infers functional dependencies between columns. When data at a node meets certain traits, Doris can eliminate unnecessary joins, aggregations, or sorts, significantly boosting performance.
In test cases designed to leverage these optimizations, leveraging data traits has achieved more than 10× performance improvement. See more in the table below:
6. Feature Improvements
Semi-structured Data
VARIANT
- Added
variant_type(x)function: returns the current actual type of a Variant subfield. - Added ComputeSignature/Helper to improve the ability to infer function parameters and return types. to improve parameter and return type inference.
STRUCT
- Schema Change now supports adding subcolumns to STRUCT types.
Lakehouse
- Now support setting metadata cache policies at the Catalog level (e.g., cache expiration time), giving users more flexibility to balance data freshness and metadata access performance.
Refer to documentation
- Added support for the
FILE()Table Valued Function, which unifies the existingS3(),HDFS(),LOCAL()functions into a single interface for easier use and understanding.
Refer to documentation
Enhanced Aggregate Operator Capabilities
In Doris 3.1, the optimizer has focused on improving the aggregate operators, adding support for two widely used features.
Non-Standard GROUP BY Support
SQL Standard does not permit queries for which the select list, HAVING condition, or ORDER BY list refer to nonaggregated columns that are not named in the GROUP BY clause. However, in MySQL, if the SQL_MODE does not include "ONLY_FULL_GROUP_BY," then there's no restriction. See the MySQL documentation for more details: https://dev.mysql.com/doc/refman/8.4/en/sql-mode.html#sqlmode_only_full_group_by
The effect of disabling ONLY_FULL_GROUP_BY is equivalent to using ANY_VALUE on non-aggregated columns. For example:
-- Non-standard GROUP BY
SELECT c1, c2 FROM t GROUP BY c1
-- Equal to
SELECT c1, any_value(c2) FROM t GROUP BY c1
In 3.1, Doris enables "ONLY_FULL_GROUP_BY" by default, aligned with previous behavior. To use non-standard GROUP BY functionality, users can enable it through configuration below:
set sql_mode = replace(@@sql_mode, 'ONLY_FULL_GROUP_BY', '');
Support for Multiple DISTINCT Aggregates
In previous versions, if an aggregation query contained multiple DISTINCT aggregate functions with different parameters—and their DISTINCT semantics differed from their non-DISTINCT semantics, while not being one of the following—Doris could not execute the query:
- single-parameter COUNT
- SUM
- AVG
- GROUP_CONCAT
Doris 3.1 significantly enhances this area. Now, queries involving multiple distinct aggregates can be executed correctly and return results as expected, for example:
SELECT count(DISTINCT c1,c2), count(DISTINCT c2,c3), count(DISTINCT c3) FROM t;
7. Behavioral Changes
VARIANT
variant_max_subcolumns_countconstraint- In a single table, all Variant columns must have the same
variant_max_subcolumns_countvalue: either all 0 or all greater than 0. Mixing values will cause errors during table creation or schema changes.
- In a single table, all Variant columns must have the same
- New Variant read/write/serde and compaction paths are backward compatible with old data. Upgrading from older Variant versions may produce slight differences in query output (e.g., extra spaces or additional levels created by . separators).
- Creating an inverted index on Variant data type will generate empty index files if none of the data fields meet the index conditions; this is expected behavior.
Permissions
- The permission required for SHOW TRANSACTION has changed: it now requires LOAD_PRIV on the target database instead of ADMIN_PRIV.
- SHOW FRONTENDS / BACKENDS and the NODE RESTful API now use the same permission. These interfaces now require SELECT_PRIV in the information_schema database.
Get Started with Apache Doris 3.1
Even before the official release of version 3.1, several features in semi-structured data and data lakes have been validated in real-world production scenarios, and showing expected performance improvements. We encourage users with relevant needs to try the new version:
Download Apache Doris 3.1 on GitHub
Download from the official website
Acknowledgements
We sincerely thank all contributors who contributed to the development, testing, and giving feedback for this release:
@924060929 @airborne12 @amorynan @BePPPower @BiteTheDDDDt @bobhan1 @CalvinKirs @cambyzju @cjj2010 @csun5285 @DarvenDuan @dataroaring @deardeng @dtkavin @dwdwqfwe @eldenmoon @englefly @feifeifeimoon @feiniaofeiafei @felixwluo @freemandealer @Gabriel39 @gavinchou @ghkang98 @gnehil @gohalo @HappenLee @heguanhui @hello-stephen @HonestManXin @htyoung @hubgeter @hust-hhb @jacktengg @jeffreys-cat @Jibing-Li @JNSimba @kaijchen @kaka11chen @KeeProMise @koarz @liaoxin01 @liujiwen-up @liutang123 @luwei16 @MoanasDaddyXu @morningman @morrySnow @mrhhsg @Mryange @mymeiyi @nsivarajan @qidaye @qzsee @Ryan19929 @seawinde @shuke987 @sollhui @starocean999 @suxiaogang223 @SWJTU-ZhangLei @TangSiyang2001 @Vallishp @vinlee19 @w41ter @wangbo @wenzhenghu @wumeibanfa @wuwenchi @wyxxxcat @xiedeyantu @xinyiZzz @XLPE @XnY-wei @XueYuhai @xy720 @yagagagaga @Yao-MR @yiguolei @yoock @yujun777 @Yukang-Lian @Yulei-Yang @yx-keith @Z-SWEI @zclllyybb @zddr @zfr9527 @zgxme @zhangm365 @zhangstar333 @zhaorongsheng @zhiqiang-hhhh @zy-kkk @zzzxl1993


