



We're excited to announce the official release of Apache Doris 4.0: a major milestone release that focused on improving four main areas: 1) new AI capabilities vector search, and AI functions, 2) stronger full-text search, 3) better ETL/ELT processing, and 4) performance optimization with TopN lazy materialization and SQL cache.
Key highlights of Apache Doris 4.0:
- AI-Ready with Vector Search, AI Functions, and Hybrid Search:
- Vector Search: Doris 4.0 introduces vector indexing to support vector search. This allows users to do vector search, as well as regular SQL analytics directly in Apache Doris, with no need for external vector databases.
- AI Functions: These functions allow data analysts to call large language models directly via SQL for tasks like information extraction, sentiment analysis, and text summarization, all within Doris. Less glue codes and cleaner pipelines.
- Hybrid Search and Analytics Processing (HSAP): Doris 4.0 combines vector search, full-text search, and structured analytics all in one engine. This unified approach enables precise keyword search, semantic matching, and complex analytical queries to run seamlessly in a single SQL workflow, without external systems or duplicated data.
- Better Full-Text Search: A brand-new SEARCH() function brings a lightweight DSL syntax similar to Elasticsearch Query String, offering faster, more flexible, and easier-to-use text retrieval.
- Stronger ETL/ELT: Doris 4.0 introduces a new Spill Disk feature to improve heavy ETL/ELT processing and multi-table materialized views. The feature automatically writes intermediate data to disk when memory limits are exceeded, ensuring greater stability and fault tolerance for large-scale ETL tasks.
- Performance Optimization: Doris 4.0 delivers major performance gains through TopN lazy materialization and SQL cache improvements. TopN queries now execute up to dozens of times faster in certain wide-table scenarios. We also improved SQL cache, now enabled by default, achieving a 100x improvement in SQL parsing efficiency.
This release is a team effort from over 200 community members, with more than 9,000 improvements and fixes submitted. Thank you to everyone who has helped test, review, and refine this milestone version.
- GitHub: https://github.com/apache/doris/releases
- Download Doris 4.0: https://doris.apache.org/download
1. AI Capabilities: Vector Search and AI Functions
A. Vector Index for Vector Search
Doris 4.0 introduces vector indexing to improve vector search. With 4.0, users can now use vector index alongside Doris' native SQL analytics, performing both structured queries and vector similarity searches within Doris. This gives users a much simpler architecture for AI workloads like semantic search, smart recommendations, and image retrieval.
Vector Index Search Functions
l2_distance_approximate(): Uses the HNSW index to approximate similarity calculation based on Euclidean Distance (L2). The smaller the value, the higher the similarity.inner_product_approximate(): Uses the HNSW index to approximate similarity calculation based on Inner Product. The larger the value, the higher the similarity.
Example
-- 1) create table
CREATE TABLE doc_store (
id BIGINT,
title STRING,
tags ARRAY<STRING>,
embedding ARRAY<FLOAT> NOT NULL,
INDEX idx_vec (embedding) USING ANN PROPERTIES (
"index_type" = "hnsw",
"metric_type" = "l2_distance",
"dim" = "768",
"quantizer" = "flat" -- options:flat / sq8 / sq4
),
INDEX idx_title (title) USING INVERTED PROPERTIES ("parser" = "english")
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 16
PROPERTIES("replication_num"="1");
-- 2) TopN
SELECT id, l2_distance_approximate(embedding, [...]) AS dist
FROM doc_store
ORDER BY dist ASC
LIMIT 10;
-- 3) hybrid search : filter first and then topn
SELECT id, title,
l2_distance_approximate(embedding, [...]) AS dist
FROM doc_store
WHERE title MATCH_ANY 'music' -- filter using full text index
AND array_contains(tags, 'recommendation') -- filter using structured filter
ORDER BY dist ASC
LIMIT 5;
-- 4) range query
SELECT COUNT(*)
FROM doc_store
WHERE l2_distance_approximate(embedding, [...]) <= 0.35;
Parameters
index_type: Required. Currently supportshnsw(Hierarchical Navigable Small Worlds).metric_type: Required. Options arel2_distance(Euclidean Distance) orinner_product.dim: Required. A positive integer that must be strictly consistent with the dimension of the imported vectors.max_degree: Optional. The default value is 32. Controls the out-degree (parameterMin the HNSW algorithm) of nodes in the HNSW graph.ef_construction: Optional. The default value is 40. Specifies the length of the candidate queue during the index construction phase (parameterefConstructionin the HNSW algorithm).quant: Optional. Options areflat(default),sq8(8-bit scalar quantization), orsq4(4-bit scalar quantization). Quantization significantly reduces memory usage: the size of an SQ8 index is approximately 1/3 that of a FLAT index, enabling higher storage capacity and lower costs at the expense of a slight recall rate loss.
Notes
- By default, Doris uses the "pre-filtering" mechanism: it first applies predicate filtering using precisely locatable indexes (e.g., inverted indexes), then performs ANN TopN (Approximate Nearest Neighbor) retrieval on the remaining dataset. This ensures the interpretability of results and stability of recall rates.
- Suppose the SQL query contains predicates that cannot be precisely located via secondary indexes (e.g., ROUND(id) > 100 where no secondary index like an inverted index exists for the id column). In that case, the system will fall back to an exact brute-force search to preserve the semantics and correctness of pre-filtering.
- The vector column must be of type
ARRAY<FLOAT> NOT NULL, and the dimension of imported vectors must match thedimparameter of the index. - Currently, ANN retrieval only supports the Duplicate Key table model.
B. AI Functions
Doris 4.0 also introduced a series of AI Functions.
Data analysts can use AI Functions to call large language models directly with simple SQL queries, no external tools needed. Whether it's extracting key information, classifying sentiment in reviews, or generating concise text summaries, all LLM interactions can now be done seamlessly inside Apache Doris.
- AI_CLASSIFY: Extracts a single label string (from a given set of labels) that has the highest matching degree with the text content.
- AI_EXTRACT: Extracts information related to each specified label based on the text content.
- AI_FILTER: Determines the correctness of the text content and returns a
boolvalue (true/false). - AI_FIXGRAMMAR: Fix grammatical and spelling errors in the text.
- AI_GENERATE: Generates content based on the input parameters.
- AI_MASK: Replaces sensitive information in the original text with
[MASKED]according to specified labels (for data desensitization). - AI_SENTIMENT: Analyzes the sentiment tendency of the text and returns one of the following values:
positive,negative,neutral, ormixed. - AI_SIMILARITY: Evaluates the semantic similarity between two texts and returns a floating-point number between 0 and 10 (a higher value indicates greater semantic similarity).
- AI_SUMMARIZE: Generates a concise summary of the text.
- AI_TRANSLATE: Translates the text into a specified language.
- AI_AGG: Performs cross-row aggregate analysis on multiple text entries.
We currently support the following LLMs: Local (local deployment), OpenAI, Anthropic, Gemini, DeepSeek, MoonShot, MiniMax, Zhipu, Qwen, and Baichuan.
Example of using AI Functions
Check out an example using the AI_FILTER function in a simulated job screening scenario.
We first simulated a table of candidates' resumes and job requirements for recruitment:
CREATE TABLE candidate_profiles (
candidate_id INT,
name VARCHAR(50),
self_intro VARCHAR(500)
)
DUPLICATE KEY(candidate_id)
DISTRIBUTED BY HASH(candidate_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
CREATE TABLE job_requirements (
job_id INT,
title VARCHAR(100),
jd_text VARCHAR(500)
)
DUPLICATE KEY(job_id)
DISTRIBUTED BY HASH(job_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO candidate_profiles VALUES
(1, 'Alice', 'I am a senior backend engineer with 7 years of experience in Java, Spring Cloud and high-concurrency systems.'),
(2, 'Bob', 'Frontend developer focusing on React, TypeScript and performance optimization for e-commerce sites.'),
(3, 'Cathy', 'Data scientist specializing in NLP, large language models and recommendation systems.');
INSERT INTO job_requirements VALUES
(101, 'Backend Engineer', 'Looking for a senior backend engineer with deep Java expertise and experience designing distributed systems.'),
(102, 'ML Engineer', 'Seeking a data scientist or ML engineer familiar with NLP and large language models.');
You can use AI_FILTER to perform semantic matching between job requirements and candidates' profiles, thereby filtering out suitable candidates:
SELECT
c.candidate_id, c.name,
j.job_id, j.title
FROM candidate_profiles AS c
JOIN job_requirements AS j
WHERE AI_FILTER(CONCAT('Does the following candidate self-introduction match the job description?',
'Job: ', j.jd_text, ' Candidate: ', c.self_intro));
+--------------+-------+--------+------------------+
| candidate_id | name | job_id | title |
+--------------+-------+--------+------------------+
| 3 | Cathy | 102 | ML Engineer |
| 1 | Alice | 101 | Backend Engineer |
+--------------+-------+--------+------------------+
2. Better Full-Text Search
To meet the diverse search needs of enterprises, Doris 4.0 has significantly improved its full-text search capabilities, delivering a more precise and flexible full-text search experience, along with better support for hybrid search scenarios.
A. New SEARCH() Function: A Unified, Lightweight DSL for Full-Text Search
Highlights
- One function handles full-text search: Doris 4.0 consolidates complex text search operators into a unified
SEARCH()function, with syntax closely aligned to Elasticsearch Query String, greatly reducing the complexity of SQL concatenation and migration costs. - Multi-condition index pushdown: Complex search conditions are directly pushed down to the inverted index for execution, avoiding the repeated overhead of "parsing once and concatenating once," which significantly improves performance.
Syntax Features Supported in the Current Version
- Term Query:
field:value - ANY / ALL Multi-Value Matching:
field:ANY(v1 v2 ...)/field:ALL(v1 v2 ...) - Boolean Combination:
AND/OR/NOTwith bracket grouping - Multi-Field Search: Perform boolean combination on multiple fields within a single
search()function
Syntax Features to Be Supported in Future Versions (via Continuous Iteration)
- Phrases
- Prefixes
- Wildcards
- Regular Expressions
- Ranges
- Lists
Example
-- Term Queries
SELECT * FROM docs WHERE search('title:apache');
-- ANY: Matches any one of the specified values
SELECT * FROM docs WHERE search('tags:ANY(java python golang)');
-- ALL: Requires all specified values to be present simultaneously
SELECT * FROM docs WHERE search('tags:ALL(machine learning)');
-- Boolean logic with multiple fields
SELECT * FROM docs
WHERE search('(title:Doris OR content:database) AND NOT category:archived');
-- Combined with structured filtering (structured conditions do not affect scoring)
SELECT * FROM docs
WHERE search('title:apache') AND publish_date >= '2025-01-01';
B. Text Search Scoring
To better support hybrid search scenarios, Doris 4.0 introduces the industry-leading BM25 relevance scoring algorithm as a replacement for the traditional TF-IDF algorithm. BM25 dynamically adjusts the weight of term frequency based on document length, significantly improving result relevance and search accuracy, especially in long-text and multi-field search scenarios such as log analysis and document search.
Example:
SELECT *, score() as score
FROM search_demo
WHERE content MATCH_ANY 'search query'
ORDER BY score DESC
LIMIT 10;
Features and Limitations
Supported Index Types
- Tokenized Index: Supports predefined tokenizers and custom tokenizers.
- Non-Tokenized Index: Indexes that do not perform tokenization (whole-text indexing).
Supported Text Search Operators
- MATCH_ANY
- MATCH_ALL
- MATCH_PHRASE
- MATCH_PHRASE_PREFIX
- SEARCH
Notes
- Score Range: BM25 scores have no fixed upper or lower bounds; the relative magnitude of scores is more meaningful than their absolute values.
- Empty Query: If the query term does not exist in the dataset, a score of 0 will be returned.
- Impact of Document Length: Shorter documents typically receive higher scores when they contain the query term.
- Number of Query Terms: For multi-term queries, the total score is the combination (sum) of the scores of individual terms.
C. Better Inverted Index Tokenization
We introduced basic tokenization capabilities in Doris 3.1. These capabilities have been further improved in 4.0 to meet the diverse tokenization and text search needs across various scenarios.
1. New Built-in Tokenizers
- ICU (International Components for Unicode) Tokenizer
Applicable Scenarios: Internationalized texts with complex writing systems, especially suitable for multilingual mixed documents.
Examples:
SELECT TOKENIZE('مرحبا بالعالم Hello 世界', '"parser"="icu"');
-- Result: ["مرحبا", "بالعالم", "Hello", "世界"]
SELECT TOKENIZE('มนไมเปนไปตามความตองการ', '"parser"="icu"');
-- Result: ["มน", "ไมเปน", "ไป", "ตาม", "ความ", "ตองการ"]
- Basic Tokenizer
Applicable Scenarios: Simple scenarios or scenarios requiring extremely high performance; can be used as an alternative to Unicode tokenizers in log processing scenarios.
Examples:
-- English Text Tokenization
SELECT TOKENIZE('Hello World! This is a test.', '"parser"="basic"');
-- Result: ["hello", "world", "this", "is", "a", "test"]
-- Chinese Text Tokenization
SELECT TOKENIZE('你好世界', '"parser"="basic"');
-- Result: ["你", "好", "世", "界"]
-- Mixed-Language Tokenization
SELECT TOKENIZE('Hello你好World世界', '"parser"="basic"');
-- Result: ["hello", "你", "好", "world", "世", "界"]
-- Supports Numbers and Special Characters
SELECT TOKENIZE('GET /images/hm_bg.jpg HTTP/1.0', '"parser"="basic"');
-- Result: ["get", "images", "hm", "bg", "jpg", "http", "1", "0"]
-- Handles Long Numeric Sequences
SELECT TOKENIZE('12345678901234567890', '"parser"="basic"');
-- Result: ["12345678901234567890"]
2. New Custom Tokenization Capabilities
- Flexible Pipeline: Build custom text processing workflows through chained configuration of
char filter,tokenizer, and multipletoken filters. - Reusable Component: Commonly used
tokenizersandfilterscan be shared across multipleanalyzers, reducing redundant definitions and lowering maintenance costs. - Users can leverage Doris' custom tokenization feature to flexibly combine
char filters,tokenizers, andtoken filters. This allows for customized tokenization workflows to suit different fields and meets personalized text search requirements in diverse scenarios.
Usage Example 1:
- Create a
token filterof typeword_delimiter, and configure the Word Delimiter Filter to set dots (.) and underscores (_) as delimiters. - Create a custom tokenizer
complex_identifier_analyzerthat references thetoken filtercomplex_word_splitter.
-- 1. Create a custom token filter
CREATE INVERTED INDEX TOKEN_FILTER IF NOT EXISTS complex_word_splitter
PROPERTIES
(
"type" = "word_delimiter",
"type_table" = "[. => SUBWORD_DELIM], [_ => SUBWORD_DELIM]");
-- 2. Create a custom tokenizer
CREATE INVERTED INDEX ANALYZER IF NOT EXISTS complex_identifier_analyzer
PROPERTIES
(
"tokenizer" = "standard",
"token_filter" = "complex_word_splitter, lowercase"
);
SELECT TOKENIZE('apy217.39_202501260000026_526', '”analyzer“=” complex_identifier_analyzer“');
-- Result:[apy],[217],[39],[202501260000026],[526]
-- MATCH('apy217') or MATCH('202501260000026') can both work
Usage Example 2:
- Create a
tokenizerof typechar_groupnamedmulti_value_tokenizer, which only uses the symbol|as the delimiter. - Create a custom tokenizer
multi_value_analyzerthat references thetokenizermulti_value_tokenizer.
-- Create a char group tokenizer for multi-valued column splitting
CREATE INVERTED INDEX TOKENIZER IF NOT EXISTS multi_value_tokenizer
PROPERTIES
(
"type" = "char_group",
"tokenize_on_chars" = "[|]",
"max_token_length" = "255"
);
-- Create a tokenizer for multi-valued columns
CREATE INVERTED INDEX ANALYZER IF NOT EXISTS multi_value_analyzer
PROPERTIES
(
"tokenizer" = "multi_value_tokenizer",
"token_filter" = "lowercase, asciifolding"
);
SELECT tokenize('alice|123456|company', '"analyzer"="multi_value_analyzer"');
-- Result: [alice]、[123456]、[company]
-- Both MATCH_ANY('alice') and MATCH_ANY('123456') can successfully match
3. Better ETL/ELT Processing
Doris 4.0 introduces a new Spill Disk feature to improve stability and fault tolerance of large-scale ETL/ELT data processing. This feature allows part of the intermediate data to be automatically written to disk when a computing task exceeds its memory threshold, preventing task failures caused by insufficient memory.
Currently, spill-to-disk is supported for the following operators:
- Hash Join operator
- Aggregation operator
- Sort operator
- CTE operator
BE Configuration Items
spill_storage_root_path=/mnt/disk1/spilltest/doris/be/storage;/mnt/disk2/doris-spill;/mnt/disk3/doris-spill
spill_storage_limit=100%
- spill_storage_root_path: Storage path for intermediate result files spilled to disk. By default, it is the same as
storage_root_path. - spill_storage_limit: Disk space limit for spilled files. It can be configured as a specific size (e.g., 100G, 1T) or a percentage; the default value is 20%. If
spill_storage_root_pathis set to a dedicated disk, this parameter can be configured as 100%. Its main purpose is to prevent spilled files from occupying excessive disk space, which would disrupt normal data storage.
FE Session Variable
set enable_spill=true;
set exec_mem_limit = 10g;
set query_timeout = 3600;
- enable_spill: Determines whether a query will spill data to disk. It is disabled by default. When enabled, query will automatically spill intermediate data to disk to prevent failures due to insufficient memory.
- exec_mem_limit: Specifies the maximum memory size that a single query can use.
- query_timeout: When spilling to disk is enabled, query duration may increase significantly, so this parameter needs to be adjusted accordingly.
Monitoring Spill Execution Status
Once spilling to disk occurs, users can monitor its execution status through multiple methods:
Audit Logs
Two fields: SpillWriteBytesToLocalStorage and SpillReadBytesFromLocalStorage have been added to the FE audit log. They represent the total amount of data written to and read from disk during spilling, respectively.
SpillWriteBytesToLocalStorage=503412182|SpillReadBytesFromLocalStorage=503412182
Query Profile
If spilling to disk is triggered during a query, several counters prefixed with Spill are added to the Query Profile to mark and track spill-related metrics. Taking the "Build HashTable" step in HashJoin as an example, the following counters are available:
PARTITIONED_HASH_JOIN_SINK_OPERATOR (id=4 , nereids_id=179):(ExecTime: 6sec351ms)
- Spilled: true
- CloseTime: 528ns
- ExecTime: 6sec351ms
- InitTime: 5.751us
- InputRows: 6.001215M (6001215)
- MemoryUsage: 0.00
- MemoryUsagePeak: 554.42 MB
- MemoryUsageReserved: 1024.00 KB
- OpenTime: 2.267ms
- PendingFinishDependency: 0ns
- SpillBuildTime: 2sec437ms
- SpillInMemRow: 0
- SpillMaxRowsOfPartition: 68.569K (68569)
- SpillMinRowsOfPartition: 67.455K (67455)
- SpillPartitionShuffleTime: 836.302ms
- SpillPartitionTime: 131.839ms
- SpillTotalTime: 5sec563ms
- SpillWriteBlockBytes: 714.13 MB
- SpillWriteBlockCount: 1.344K (1344)
- SpillWriteFileBytes: 244.40 MB
- SpillWriteFileTime: 350.754ms
- SpillWriteFileTotalCount: 32
- SpillWriteRows: 6.001215M (6001215)
- SpillWriteSerializeBlockTime: 4sec378ms
- SpillWriteTaskCount: 417
- SpillWriteTaskWaitInQueueCount: 0
- SpillWriteTaskWaitInQueueTime: 8.731ms
- SpillWriteTime: 5sec549ms
System Table: backend_active_tasks
We have added two fields to the table: SPILL_WRITE_BYTES_TO_LOCAL_STORAGE and SPILL_READ_BYTES_FROM_LOCAL_STORAGE. They represent the total amount of data written to disk and read from disk for intermediate spill data during a query, respectively.
Example query result:
mysql [information_schema]>select * from backend_active_tasks;
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
| BE_ID | FE_HOST | WORKLOAD_GROUP_ID | QUERY_ID | TASK_TIME_MS | TASK_CPU_TIME_MS | SCAN_ROWS | SCAN_BYTES | BE_PEAK_MEMORY_BYTES | CURRENT_USED_MEMORY_BYTES | SHUFFLE_SEND_BYTES | SHUFFLE_SEND_ROWS | QUERY_TYPE | SPILL_WRITE_BYTES_TO_LOCAL_STORAGE | SPILL_READ_BYTES_FROM_LOCAL_STORAGE |
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
| 10009 | 10.16.10.8 | 1 | 6f08c74afbd44fff-9af951270933842d | 13612 | 11025 | 12002430 | 1960955904 | 733243057 | 70113260 | 0 | 0 | SELECT | 508110119 | 26383070 |
| 10009 | 10.16.10.8 | 1 | 871d643b87bf447b-865eb799403bec96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | SELECT | 0 | 0 |
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
2 rows in set (0.00 sec)
Testing
To verify the stability of the Spill Disk feature, we conducted tests using the TPC-DS 10TB standard dataset. The test environment was configured with 3 BE servers on AWS (each with 16-core CPU and 64GB memory ), resulting in a BE memory-to-data size ratio of 1:52.
Test results show that the total execution time was 28102.386 seconds, and all 99 queries in the TPC-DS benchmark were successfully completed, validating the stability of the Spill Disk feature.
For more details of the Spill Disk feature, please read our documentation: https://doris.apache.org/docs/dev/admin-manual/workload-management/spill-disk
4. Data Quality Assurance: End-to-End
Data accuracy is the cornerstone of sound business decisions. To strengthen this foundation, Doris 4.0 introduces a comprehensive review and standardization of function behaviors, establishing an end-to-end verification mechanism: from data ingestion to analytical computation. This ensures the accuracy and reliability of every processing result, providing a solid data backbone for enterprise decision-making.
Note: These data quality improvements may lead to behavioral changes from previous versions. Please review the documentation carefully before upgrading.
CAST Function
CAST is one of the most logically complex functions in SQL, whose core function is to convert different data types. This process not only requires handling a large number of detailed format rules and edge cases, but also involves precise mapping of type semantics. All of these make CAST a part of the process that's highly prone to errors in real-world use.
Particularly in data import scenarios, which essentially is a CAST process that converts external strings to internal database types. Thus, the behavior of CAST directly determines the accuracy and stability of import logic.
Also, we foresee that many of the databases will be operated by AI systems, which need clear definitions of database behaviors. That's why we have introduced the BNF (Backus-Naur Form). By defining behaviors through BNF, we aim to provide clear operational guidelines for developers and AI Agents.
For example, the CAST operation for the DATE type alone already covers dozens of format combination scenarios via BNF (see: https://doris.apache.org/docs/dev/sql-manual/basic-element/sql-data-types/conversion/datetime-conversion). During the testing phase, we also derived millions of test cases based on these rules to ensure the correctness of results.
<datetime> ::= <date> (("T" | " ") <time> <whitespace>* <offset>?)?
| <digit>{14} <fraction>? <whitespace>* <offset>?
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<date> ::= <year> ("-" | "/") <month1> ("-" | "/") <day1>
| <year> <month2> <day2>
<year> ::= <digit>{2} | <digit>{4} ; Till 1970
<month1> ::= <digit>{1,2} ; 01–12
<day1> ::= <digit>{1,2} ; 01–28/29/30/31
<month2> ::= <digit>{2} ; 01–12
<day2> ::= <digit>{2} ; 01–28/29/30/31
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<time> ::= <hour1> (":" <minute1> (":" <second1> <fraction>?)?)?
| <hour2> (<minute2> (<second2> <fraction>?)?)?
<hour1> ::= <digit>{1,2} ; 00–23
<minute1> ::= <digit>{1,2} ; 00–59
<second1> ::= <digit>{1,2} ; 00–59
<hour2> ::= <digit>{2} ; 00–23
<minute2> ::= <digit>{2} ; 00–59
<second2> ::= <digit>{2} ; 00–59
<fraction> ::= "." <digit>*
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<offset> ::= ( "+" | "-" ) <hour-offset> [ ":"? <minute-offset> ]
| <special-tz>
| <long-tz>
<hour-offset> ::= <digit>{1,2} ; 0–14
<minute-offset> ::= <digit>{2} ; 00/30/45
<special-tz> ::= "CST" | "UTC" | "GMT" | "ZULU" | "Z" ;
<long-tz> ::= ( ^<whitespace> )+ ; e.g. America/New_York
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<digit> ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"
<area> ::= <alpha>+
<location> ::= (<alpha> | "_")+
<alpha> ::= "A" | … | "Z" | "a" | … | "z"
<whitespace> ::= " " | "\t" | "\n" | "\r" | "\v" | "\f"
Strict Mode, Non-Strict Mode, and TRY_CAST
In Doris 4.0, we have added three mechanisms for CAST operations: Strict Mode, Non-Strict Mode (controlled by the enable_strict_cast session var), and the TRY_CAST function. These mechanisms allow Doris to better handle data type conversions.
Strict Mode
The system performs strict verification on the format, type, and value range of input data in accordance with predefined BNF (Backus-Naur Form) syntax rules. If the data fails to meet the rules (e.g., a string is passed for a field that requires a "numeric type," or a date does not conform to the "YYYY-MM-DD" standard), the system will directly terminate the data processing workflow and throw a clear error (including the specific non-compliant field and reason). This prevents invalid data from entering storage or computation processes.
This "zero-tolerance" verification logic is highly consistent with the strict data validation behavior of PostgreSQL. It ensures data accuracy and consistency from the source, making it indispensable for scenarios with extremely high requirements for data reliability: such as transaction reconciliation in the financial industry, bill accounting in finance, and information registration in government systems. Invalid data (e.g., negative transaction amounts, incorrect bill date formats) in these scenarios could lead to financial losses, compliance risks, or business process disruptions.
Non-Strict Mode
The system also verifies data against BNF rules but adopts a "fault-tolerant" processing logic: if the data is non-compliant, the workflow will not be terminated and no error will be thrown. Instead, the invalid data is automatically converted to a NULL value before the SQL continues execution (e.g., converting the string "xyz" to a numeric NULL). This ensures the SQL task completes normally, prioritizing the continuity and execution efficiency of business processes.
This mode is more suitable for scenarios where "data integrity requirements are low, but SQL execution success rate is critical": such as log data processing, user behavior data cleaning, and ad-hoc data analysis. In these scenarios, data volumes are massive and data sources are complex (e.g., APP logs may contain fields with garbled formats due to device anomalies). If the entire SQL task is interrupted by a small amount of invalid data, processing efficiency will be significantly reduced; meanwhile, a small number of NULL values have minimal impact on overall analysis results (e.g., statistics on active users or click-through rates).
TRY_CAST Function
The enable_strict_cast parameter controls the behavior of all CAST operations at the statement level. However, a scenario may arise where a single SQL contains multiple CAST functions: some require Strict Mode, while others require Non-Strict Mode. To address this, the TRY_CAST function is introduced.
The TRY_CAST function converts an expression to a specified data type. If the conversion succeeds, it returns the converted value; if it fails, it returns NULL. Its syntax is TRY_CAST(source_expr AS target_type), where source_expr is the expression to be converted, and target_type is the target data type.
For example:
TRY_CAST('123' AS INT)returns123;TRY_CAST('abc' AS INT)returnsNULL.
The TRY_CAST function provides a more flexible approach to type conversion. In scenarios where strict conversion success is not required, this function can be used to avoid errors caused by conversion failures.
Floating Number Calculations
Doris supports two floating-point data types: FLOAT and DOUBLE. However, the uncertain behavior of INF (infinity) and NAN (not a number) has historically led to potential errors in operations like ORDER BY or GROUP BY. In Doris 4.0, we have standardized and clearly defined the behavior of these values.
Arithmetic Operations
Doris floating-point numbers support common arithmetic operations, including addition, subtraction, multiplication, and division.
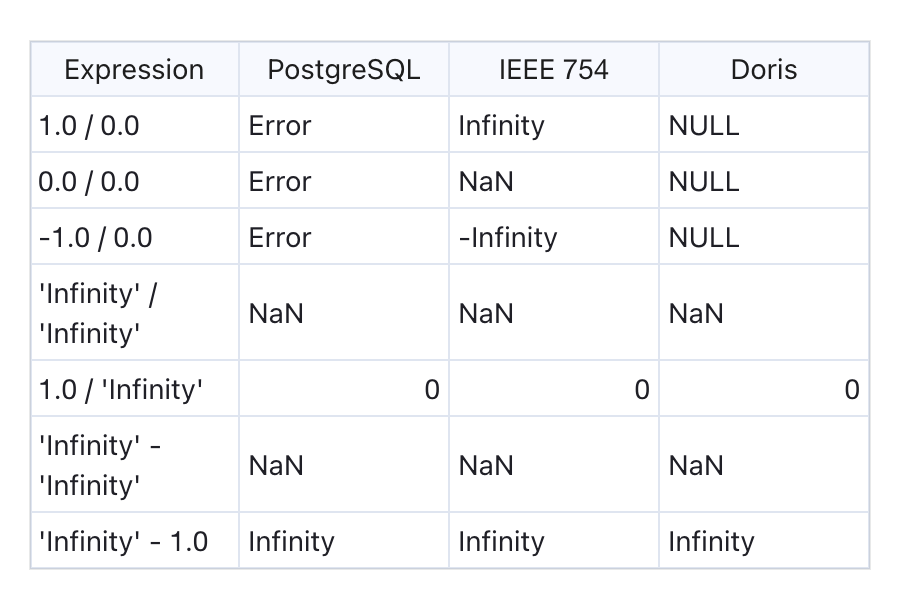
I want to let you know that Doris does not fully comply with the IEEE 754 standard when handling floating-point division by zero. Instead, Doris references PostgreSQL's implementation: when dividing by zero, no special values (e.g., INF) are generated; instead, the result returned is SQL NULL.
Comparison Operations
Floating-point comparisons defined by the IEEE standard have important differences from typical integer comparisons. For example:
- Negative zero and positive zero are considered equal.
- Any NaN (Not a Number) value is not equal to any other value, including itself.
- All finite floating-point numbers are strictly less than +∞ and strictly greater than -∞.
To ensure consistency and predictability of results, Doris handles NaN differently from the IEEE standard. In Doris:
- NaN is considered greater than all other values (including Infinity).
- NaN is equal to NaN.
Example
mysql> select * from sort_float order by d;
+------+-----------+
| id | d |
+------+-----------+
| 5 | -Infinity |
| 2 | -123 |
| 1 | 123 |
| 4 | Infinity |
| 8 | NaN |
| 9 | NaN |
+------+-----------+
mysql> select
cast('Nan' as double) = cast('Nan' as double) ,
cast('Nan' as double) > cast('Inf' as double) ,
cast('Nan' as double) > cast('123456.789' as double);
+-----------------------------------------------+-----------------------------------------------+------------------------------------------------------+
| cast('Nan' as double) = cast('Nan' as double) | cast('Nan' as double) > cast('Inf' as double) | cast('Nan' as double) > cast('123456.789' as double) |
+-----------------------------------------------+-----------------------------------------------+------------------------------------------------------+
| 1 | 1 | 1 |
+-----------------------------------------------+-----------------------------------------------+------------------------------------------------------+
Date Functions
This optimization focuses on two key areas: date functions and time zone support, further enhancing the accuracy and applicability of data processing:
Unified Date Overflow Behavior
The behavior of numerous date functions in overflow scenarios (e.g., dates earlier than 0000-01-01 or later than 9999-12-31) has been standardized. Previously, different functions handled overflow inconsistently; now, all relevant functions uniformly return errors when date overflow is triggered, preventing data calculation deviations caused by abnormal results.
Expanded Date Function Support
The parameter signatures of some date-type functions have been upgraded from int32 to int64. This adjustment breaks the date range limitations of the original int32 type, enabling related functions to support date calculations over a wider span.
Improved Time Zone Support Documentation
Based on Doris' actual time zone management logic (documentation: https://doris.apache.org/docs/dev/admin-manual/cluster-management/time-zone), the time zone support content has been updated and clarified. This includes detailed explanations of the roles and modification methods of two core parameters (system_time_zone and time_zone), as well as the specific impact of time zones on date functions (e.g., FROM_UNIXTIME, UNIX_TIMESTAMP) and data import conversions. This provides users with clearer guidance for configuring and using time zone features.
Summary
To build a truly AI agent-friendly database ecosystem and help large models understand Doris more accurately and deeply, we have systematically improved Doris' SQL Reference. This includes refining core content such as data type definitions, function definitions, and data transformation rules, laying a clear and reliable technical foundation for collaborative interaction between AI and databases.
This effort was made possible by the incredible support of our community contributors, whose insights and energy have brought vital momentum to the project. We warmly welcome more community members to join us: working together to push the boundaries of innovation, strengthen the ecosystem, and create greater value for everyone.
5. Performance Optimization
TopN
The query pattern SELECT * FROM tableX ORDER BY columnA ASC/DESC LIMIT N is a typical TopN query, widely used in high-frequency scenarios such as log analysis, vector search, and data exploration. Since such queries do not include filtering conditions, traditional execution methods require full-table scanning and sorting when dealing with large datasets. This leads to excessive unnecessary data reading and severe read amplification issues—especially in high-concurrency request or large-data storage scenarios, where performance bottlenecks for these queries become more prominent, creating an urgent need for optimization.
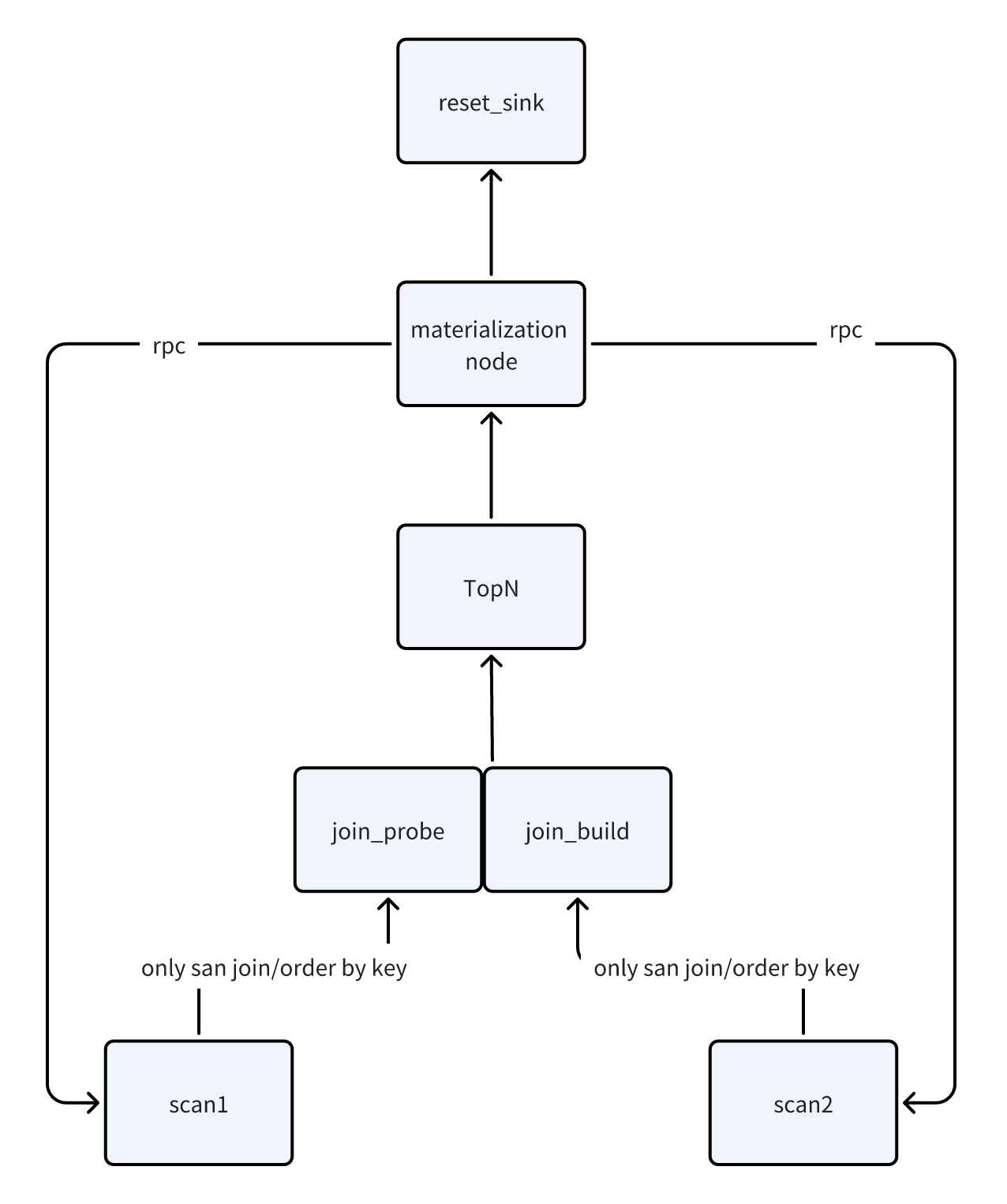
To address this pain point, we have introduced the "Lazy Materialization" optimization mechanism, which splits TopN queries into two phases for efficient execution:
- First Phase: Only read the sort column (
columnA) and the primary key/row identifier used for data positioning. Quickly filter out the target rows that meet theLIMIT Ncondition through sorting. - Second Phase: Precisely read all column data of the target rows based on the row identifiers.
In Doris 4.0, we have further extended this capability:
- Support for TopN lazy materialization in multi-table joins.
- Support for TopN lazy materialization in external table queries.
In these two new scenarios, this solution significantly reduces the amount of unnecessary column reading, fundamentally reducing read amplification. In wide-table scenarios with small LIMIT values, the execution efficiency of TopN queries has also been improved by several dozen times.
SQL Cache
SQL Cache was a feature provided in earlier versions of Doris, but its usage was restricted by many conditions and thus disabled by default. In this version, we have systematically addressed issues that could affect the correctness of SQL Cache results, such as:
- Changes to query permissions for catalogs, databases, tables, or columns
- Modifications to Session variables
- Presence of non-deterministic functions that cannot be simplified via constant folding rules
After ensuring the correctness of SQL Cache results, this feature is now enabled by default.
We also significantly optimized the SQL parsing performance in the query optimizer, achieving a 100x improvement in SQL parsing efficiency.
For example, consider the following SQL, where big_view is a large view containing nested views, with a total of 163 joins and 17 unions:
SELECT *, now() as etl_time from big_view;
The SQL parsing time for this query has been reduced from 400ms to 2ms. This optimization not only benefits SQL Cache but also significantly improves Doris' performance in high-concurrency query scenarios.
JSON Performance Optimization
JSON is a standard storage format for semi-structured data. In Doris 4.0, we have also upgraded JSONB:
Added Support for Decimal Type
This complements the mapping system between Number types in JSON and Doris internal types (previously covering Int8/Int16/Int32/Int64/Int128/Float/Double). It further meets storage and processing needs for high-precision numeric scenarios, avoiding precision loss in JSON conversion caused by type adaptation issues for large or high-precision data. This also helps the derivation of VARIANT data types.
Systematic Performance Optimization for JSONB-Related Functions
Doris 4.0 made full-scale performance improvements to JSONB-related functions (e.g., json_extract series, json_exists_path, json_type). After optimization, the execution efficiency of these functions has increased by more than 30%, significantly accelerating the processing speed of high-frequency operations such as JSON field extraction, type judgment, and path validation. This provides stronger support for efficient analysis of semi-structured data.
For detailed information about related features, please refer to the official Doris documentation: https://doris.apache.org/docs/dev/sql-manual/basic-element/sql-data-types/semi-structured/JSON
6. More User-Friendly Resource Management
Doris 4.0 also optimizes the usage mechanism of workload group:
- Unified the definition methods for soft limits and hard limits of CPU and memory. There is no longer a need to enable soft/hard limit functions individually via various configuration items.
- Support for using both soft limits and hard limits in the same
workload group.
This optimization not only simplifies the parameter configuration process but also enhances the flexibility of workload group, meeting more diverse resource management needs.
CPU Resource Configuration
MIN_CPU_PERCENT and MAX_CPU_PERCENT define the minimum and maximum guaranteed CPU resources for all requests in a Workload Group when CPU contention occurs:
- MAX_CPU_PERCENT (Maximum CPU Percentage): The upper limit of CPU bandwidth for the group. Regardless of the current CPU usage, the CPU utilization of the Workload Group will never exceed this value.
- MIN_CPU_PERCENT (Minimum CPU Percentage): The reserved CPU bandwidth for the group. During contention, other groups cannot use this portion of bandwidth; however, when resources are idle, the group can use bandwidth exceeding
MIN_CPU_PERCENT.
Example: Suppose a company's sales and marketing departments share the same Doris instance. The sales department's workload is CPU-intensive and includes high-priority queries; the marketing department's workload is also CPU-intensive but with lower-priority queries. By creating separate Workload Groups for each department:
- Allocate 40%
MIN_CPU_PERCENTto the sales Workload Group. - Allocate 30%
MAX_CPU_PERCENTto the marketing Workload Group.
This configuration ensures the sales workload gets the required CPU resources while preventing the marketing workload from impacting the sales department's CPU needs.
Memory Resource Configuration
MIN_MEMORY_PERCENT and MAX_MEMORY_PERCENT represent the minimum and maximum memory that a Workload Group can use:
- MAX_MEMORY_PERCENT: When requests run in the group, their memory usage will never exceed this percentage of the total memory. If exceeded, the query will trigger spilling to disk or be terminated (killed).
- MIN_MEMORY_PERCENT: The minimum memory reserved for the group. When resources are idle, the group can use memory exceeding
MIN_MEMORY_PERCENT; however, when memory is insufficient, the system will allocate memory based onMIN_MEMORY_PERCENT. It may kill some queries to reduce the group's memory usage toMIN_MEMORY_PERCENT, ensuring other Workload Groups have sufficient memory.
Integration with Spill Disk
In Doris 4.0, we have integrated the memory management capability of Workload Groups with the Spill Disk feature. Users can not only control spilling by setting memory sizes for individual queries but also implement dynamic spilling via the slot mechanism of Workload Groups. The following policies are implemented for Workload Groups:
- none (default): Disables the policy. Queries use as much memory as possible, but once the Workload Group's memory limit is reached, spilling is triggered (no selection based on query size).
- fixed: Memory available per query =
workload group's mem_limit * query_slot_count / max_concurrency. This policy allocates fixed memory to each query based on concurrency. - dynamic: Memory available per query =
workload group's mem_limit * query_slot_count / sum(running query slots). This primarily addresses unused slots infixedmode; essentially, it triggers spilling for large queries first.
Both fixed and dynamic set hard limits for queries: exceeding the limit triggers spilling or killing, and they override the static memory allocation parameters set by users. Therefore, when configuring slot_memory_policy, ensure max_concurrency for the Workload Group is properly set to avoid memory shortages.
Summary
Apache Doris 4.0 takes a major step forward with new AI support (vector search, AI Functions) and better full-text search capabilities. These upgrades help users stay ahead in the AI and agent era, enabling companies to handle everything from traditional BI analysis to AI-driven workloads.
Whether it's powering real-time dashboards and user behavior analytics, or supporting document search and large-scale offline data processing, Doris 4.0 delivers a faster, more reliable, and AI-ready analytics experience across industries: tech, finance, Web3, retail, healthcare, and more.
The latest version of Apache Doris is now available for download. Visit doris.apache.org for detailed release notes and upgrade guides, and join the Doris community to explore, test, and share your feedback.
Acknowledgments
Once again, we would like to express our most sincere gratitude to all contributors who participated in the R&D, testing, and requirement feedback for this version:
Pxl, walter, Gabriel, Mingyu Chen (Rayner), Mryange, morrySnow, zhangdong, lihangyu, zhangstar333, hui lai, Calvin Kirs, deardeng, Dongyang Li, Kaijie Chen, Xinyi Zou, minghong, meiyi, James / Jibing-Li, seawinde, abmdocrt, Yongqiang YANG, Sun Chenyang, wangbo, starocean999, Socrates / 苏小刚,Gavin Chou, 924060929, HappenLee, yiguolei, daidai, Lei Zhang, zhengyu, zy-kkk, zclllyybb /zclllhhjj, bobhan1, amory, zhiqiang, Jerry Hu, Xin Liao, Siyang Tang, LiBinfeng, Tiewei Fang, Luwei, huanghaibin, Qi Chen, TengJianPing, 谢健,Lightman, zhannngchen, koarz, xy720, kkop, HHoflittlefish777, xzj7019, Ashin Gau, lw112, plat1ko, shuke, yagagagaga, shee, zgxme, qiye, zfr95, slothever, Xujian Duan, Yulei-Yang, Jack, Kang, Lijia Liu, linrrarity, Petrichor, Thearas, Uniqueyou, dwdwqfwe, Refrain, catpineapple, smiletan, wudi, caiconghui, camby, zhangyuan, jakevin, Chester, Mingxi, Rijesh Kunhi Parambattu, admiring_xm, zxealous, XLPE, chunping, sparrow, xueweizhang, Adonis Ling, Jiwen liu, KassieZ, Liu Zhenlong, MoanasDaddyXu, Peyz, 神技圈子,133tosakarin, FreeOnePlus, Ryan19929, Yixuan Wang, htyoung, smallx, Butao Zhang, Ceng, GentleCold, GoGoWen, HonestManXin, Liqf, Luzhijing, Shuo Wang, Wen Zhenghu, Xr Ling, Zhiguo Wu, Zijie Lu, feifeifeimoon, heguanhui, toms, wudongliang, yangshijie, yongjinhou, yulihua, zhangm365, Amos Bird, AndersZ, Ganlin Zhao, Jeffrey, John Zhang, M1saka, SWEI, XueYuhai, Yao-MR, York Cao, caoliang-web, echo-dundun, huanghg1994, lide, lzy, nivane, nsivarajan, py023, vlt, wlong, zhaorongsheng, AlexYue, Arjun Anandkumar, Arnout Engelen, Benjaminwei, DayuanX, DogDu, DuRipeng, Emmanuel Ferdman, Fangyuan Deng, Guangdong Liu, HB, He xueyu, Hongkun Xu, Hu Yanjun, JinYang, KeeProMise, Muhammet Sakarya, Nya~, On-Work-Song, Shane, Stalary, StarryVerse, TsukiokaKogane, Udit Chaudhary, Xin Li, XnY-wei, Xu Chen, XuJianxu, XuPengfei, Yijia Su, ZhenchaoXu, cat-with-cat, elon-X, gnehil, hongyu guo, ivin, jw-sun, koi, liuzhenwei, msridhar78, noixcn, nsn_huang, peterylh, shouchengShen, spaces-x, wangchuang, wangjing, wangqt, wubiao, xuchenhao, xyf, yanmingfu, yi wang, z404289981, zjj, zzwwhh, İsmail Tosun, 赵硕


