



We benchmarked Apache Doris against ClickHouse, two popular OLAP systems, to see which handles real-time, update-intensive workloads more effectively. We ran benchmarks with ClickBench and SSB (Star Schema Benchmark), under fair resource allocations in each product's cloud services. Results: Apache Doris is 18-34x faster than ClickHouse in SSB and 2.5-4.6x faster than ClickHouse in ClickBench.
Why do real-time updates matter in OLAP?
Because in real business scenarios, data analytics isn't just about scanning massive datasets once. Data is constantly changing: new orders, updated customer info, financial trades updates, and web3 on-chain data analysis.
That means modern OLAP systems must be able to query large datasets, as well as continuously ingest and reflect data updates, otherwise dashboards and reports will lag behind reality. This is why real-time update handling has become a critical benchmark for OLAP systems.
Test Environment Configuration
To evaluate how Doris and ClickHouse perform in real-time update scenarios, we ran tests using two standard industry benchmarks: ClickBench and the SSB (Star Schema Benchmark). In both benchmarks, we applied update operations to 25% and 100% of the dataset records.
Details of the SQL updates: https://github.com/dataroaring/ClickBench/tree/main/clickhouse-cloud-update
To ensure a fair comparison, we designed the test plan to accommodate the configuration differences between ClickHouse Cloud and VeloDB Cloud (Apache Doris' cloud service).
We tested with these configurations below:
- ClickHouse Cloud: 2 nodes × (8 vCPUs + 32 GB RAM each)
- ClickHouse Cloud: 2 nodes × (16 vCPUs + 64 GB RAM each)
- VeloDB Cloud: 1 node with 16 vCPUs + 128 GB RAM
One configuration aligns the CPU cores between the systems, while the other aligns memory, allowing us to evaluate performance under both resource scenarios.
Note: ClickHouse refers to its nodes as "replicas," but here we use the term "node" more generally.
Real-Time Update Mechanism in Apache Doris and ClickHouse
Real-Time Updates in Apache Doris: Unique Key
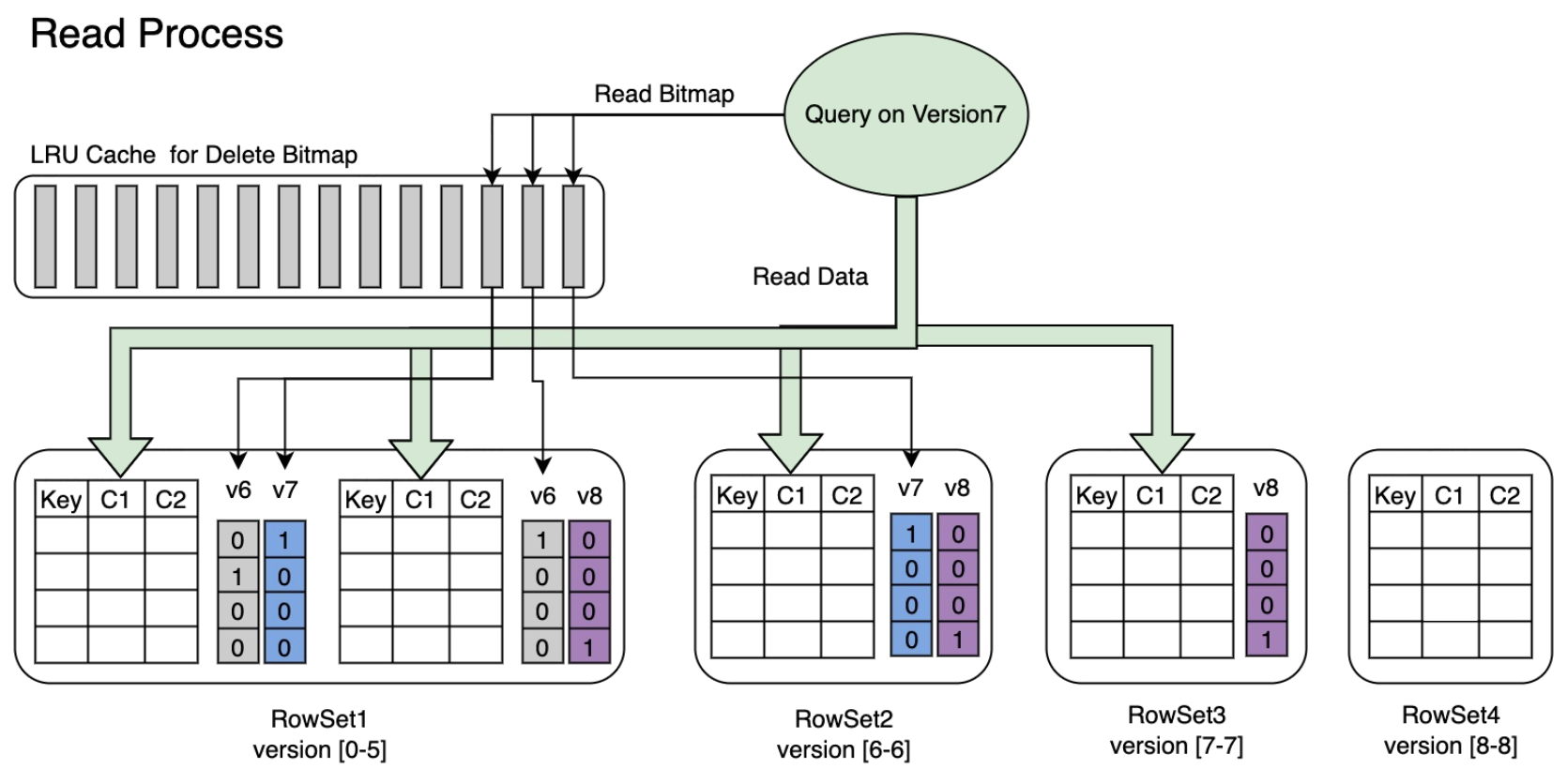
For scenarios that require frequent data updates, Apache Doris offers the Unique Key model, which allows tables to efficiently overwrite existing records with the same primary key. Doris employs a mechanism called Delete Bitmap to optimize query performance.
Unlike ClickHouse, which deletes outdated data during query execution, Doris's Delete Bitmap mechanism doesn't require calculating deletion logic during queries. This significantly reduces query latency, keeping response times consistently within hundreds of milliseconds, even under high concurrency.
Doris handles updates in two main stages:
1. Write Stage
When creating a table with the Unique Key model, you typically define a unique identifier (e.g., primary key ID) and a version column (e.g.,update_time). Whenever new data is written, if the primary key matches and the version is newer, Doris automatically marks the old data with a "delete mark." This information is written to the underlying storage along with the data.
2. Query Stage
During query execution, Doris automatically identifies and skips data rows marked for deletion, eliminating the need to compare or scan multiple versions of data. This enables low-latency, high-efficiency data reads.
Thanks to this mechanism, Doris can support both real-time updates and fast queries, making it ideal for workloads such as customer 360, order management, and observability, where frequent updates and fast analytics are critical.
Real-Time Updates in ClickHouse: ReplacingMergeTree
In ClickHouse, the underlying storage is primarily append-only. However, using the ReplacingMergeTree engine, users can achieve a similar effect to real-time updates. The core idea is to keep all versions of the data at write time and let the engine automatically retain only the latest version during background merges, effectively simulating data "updates".
Detailed documentation: https://clickhouse.com/docs/guides/developer/deduplication
How it Works
- Write Phase: When creating a table using
ReplacingMergeTree, a unique identifier column (e.g., primary key) and a version column (e.g.,update_time) are specified. Each time a record with the same primary key is updated, the system doesn’t overwrite the old data; instead, it inserts a new version of the record. - Merge Phase: ClickHouse’s background merge threads automatically merge data files when the system is idle. For
ReplacingMergeTreetables, the merge process keeps only the latest version of each record based on the primary key value and version column, and old versions are deleted, achieving the final "update" semantics. - Query Phase: Queries might read multiple versions of the same record that haven’t been merged yet. Therefore, it's recommended to use the
FINALquery modifier, for example:
SELECT * FROM my_table FINAL;
Test Results
-
SSB-sf100
In the benchmark results below, we first compare ClickHouse using MergeTree with VeloDB using Duplicate Key mechanisms. Because these mechanisms don't involve real-time updates, and ClickHouse MergeTree is usually the result that ClickHouse displays publicly in benchmarks such as SSB and ClickBench. This initial comparison serves as a baseline for subsequent tests.
Then, we compared ClickHouse itself under both MergeTree (non-real-time updates) and ReplacingMergeTree (real-time updates). As expected, MergeTree is much faster than ReplacingMergeTree.
Finally, we compare ClickHouse and VeloDB under real-time update scenarios: ClickHouse (ReplacingMergeTree) versus VeloDB (Unique Key). Across multiple tests, VeloDB outperforms ClickHouse by 14–34x in real-time update performance.
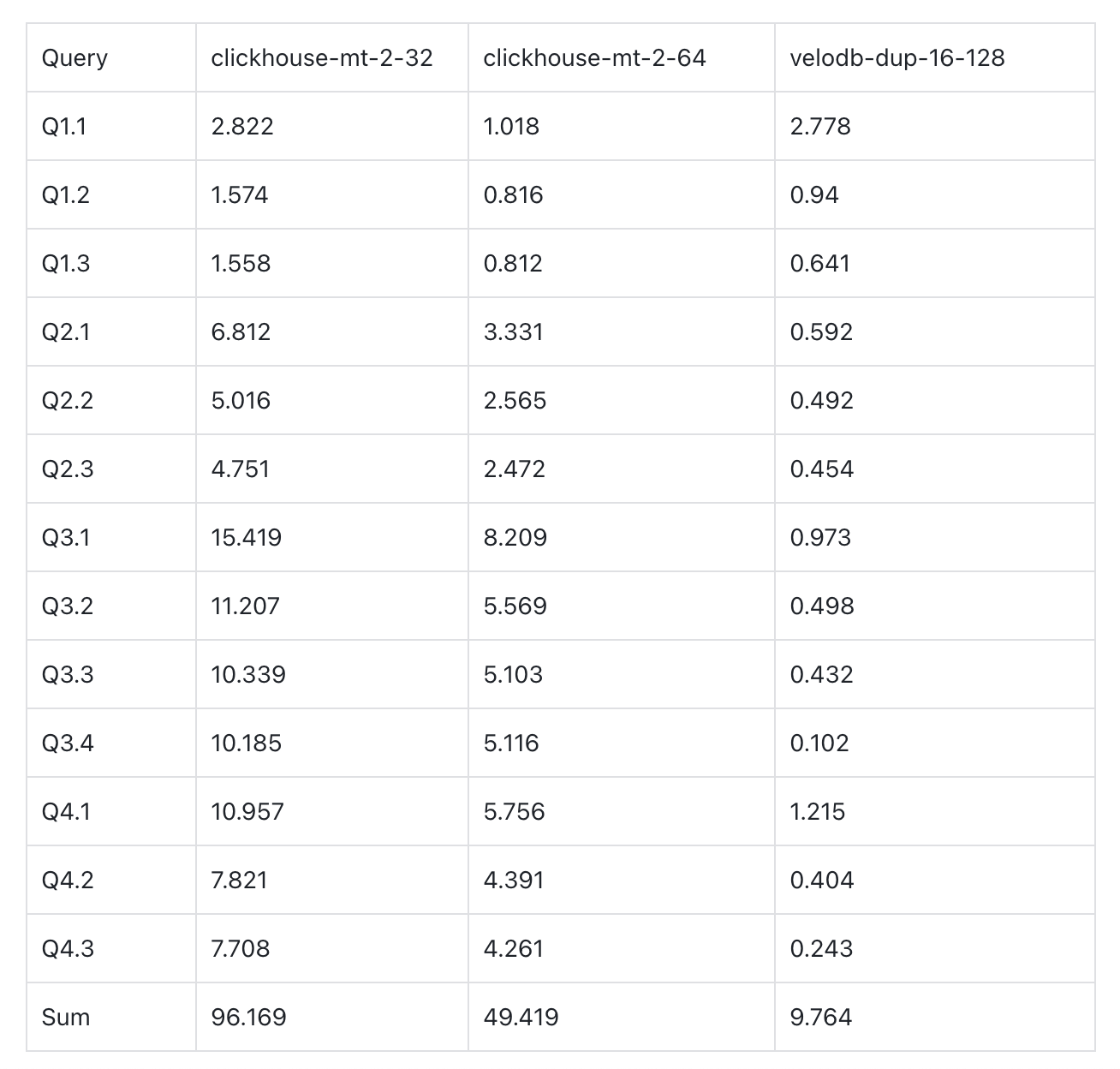
A. Clickhouse MergeTree vs. VeloDB Duplicate Key
- VeloDB (16c 128GB) is 5x faster than ClickHouse 32c 128GB (2 replicas, each replica 16c 64GB).
- VeloDB (16c 128GB) is 9.8x faster than ClickHouse 16c 64GB (2 replicas, each replica 8c 32GB).
B. Clickhouse MergeTree vs. ReplacingMergeTree
- At 25% update ratio, ClickHouse MergeTree is 1.7x faster than ReplacingMergeTree.
- At 100% update ratio, ClickHouse MergeTree is 2.5x faster than ReplacingMergeTree.
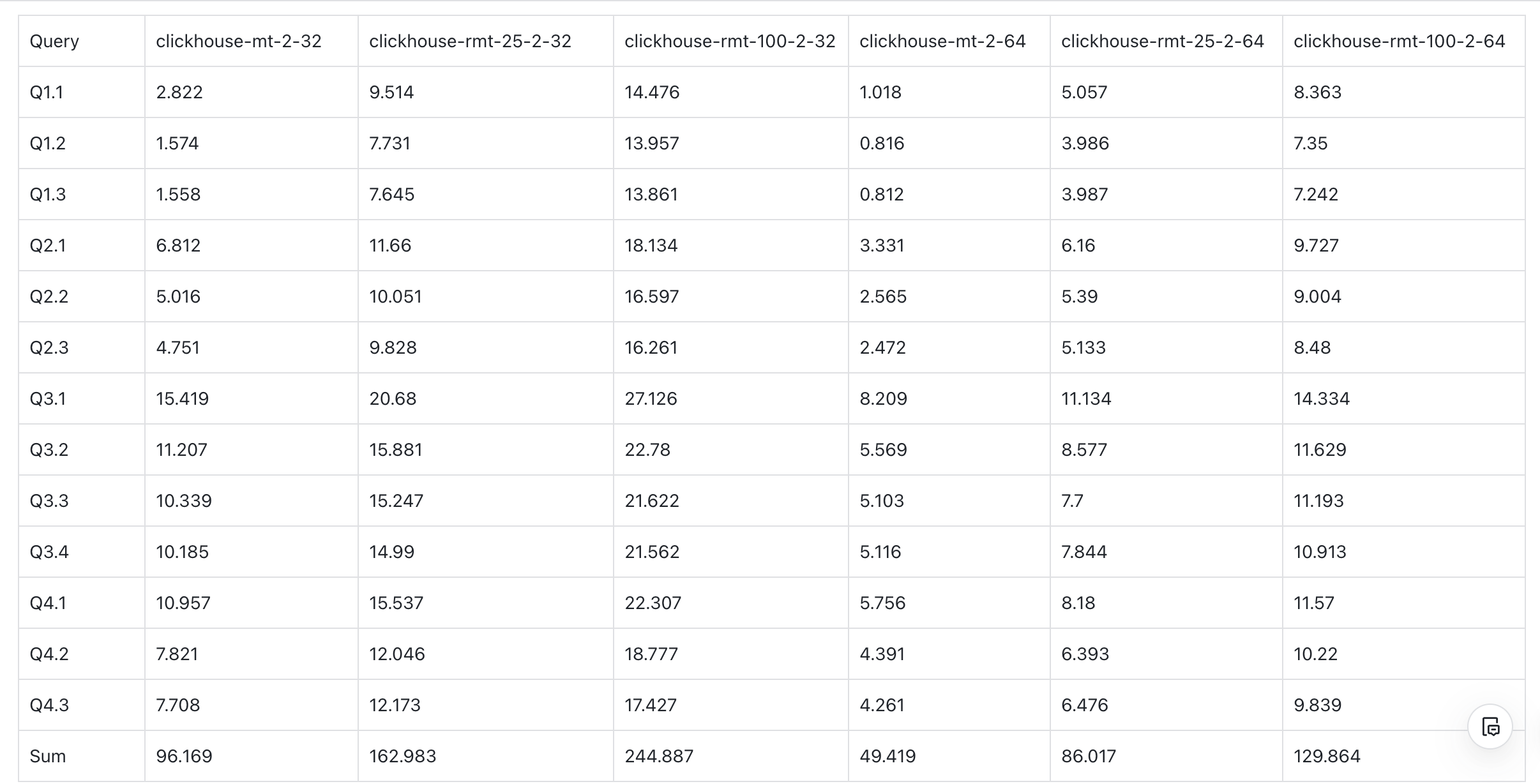
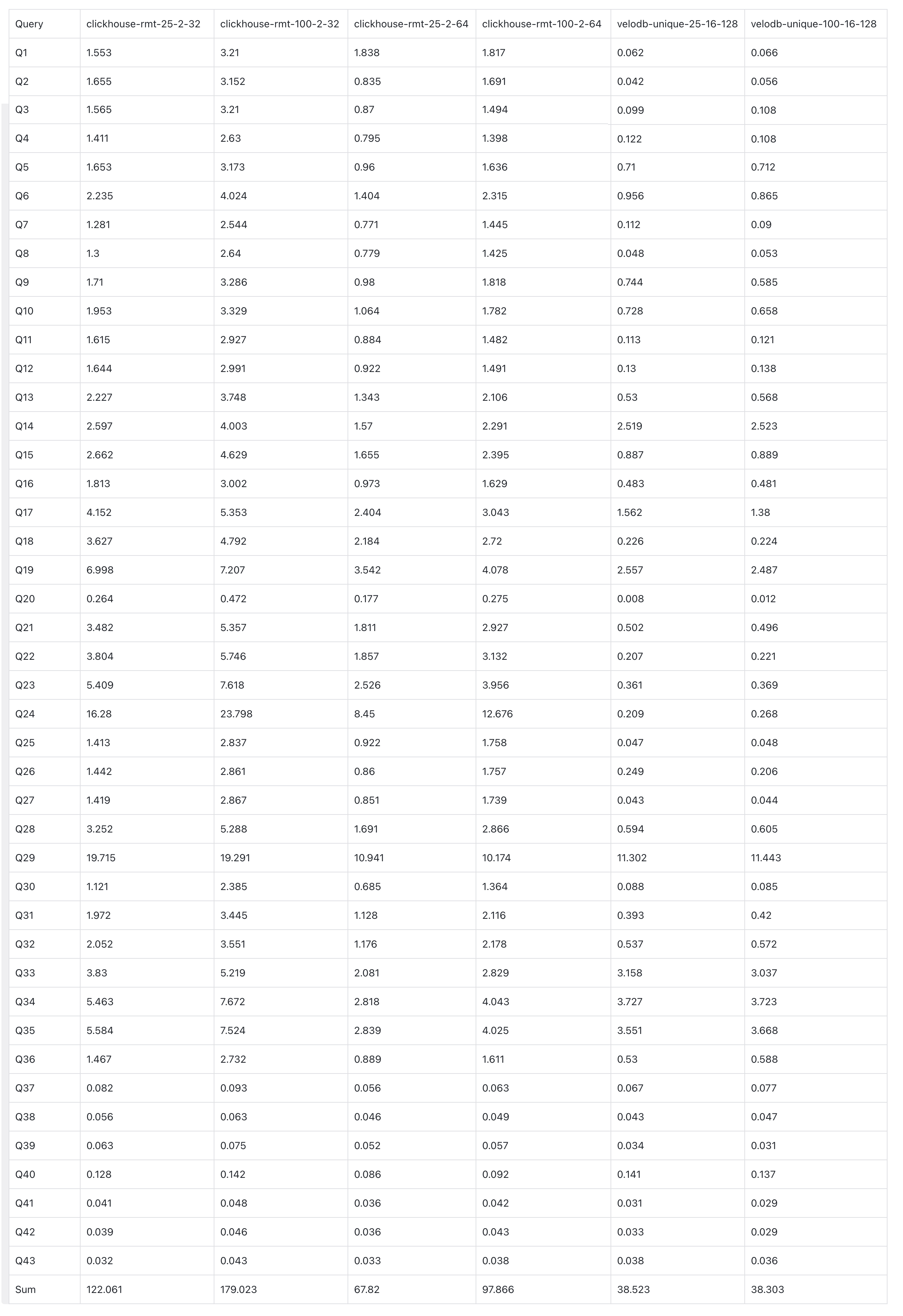
C. Clickhouse ReplacingMergeTree vs. VeloDB UniqueKey
- VeloDB (16c 128GB) vs. ClickHouse 32c 128GB (2 replicas, each replica 16c 64GB):
- At 25% update ratio, VeloDB is 14x faster than ClickHouse.
- At 100% update ratio, VeloDB is 18x faster than ClickHouse.
- VeloDB (16c 128GB) vs. ClickHouse 16c 64GB (2 replicas, each replica 8c 32GB):
- At 25% update ratio, VeloDB is 25x faster than ClickHouse.
- At 100% update ratio, VeloDB is 34x faster than ClickHouse.
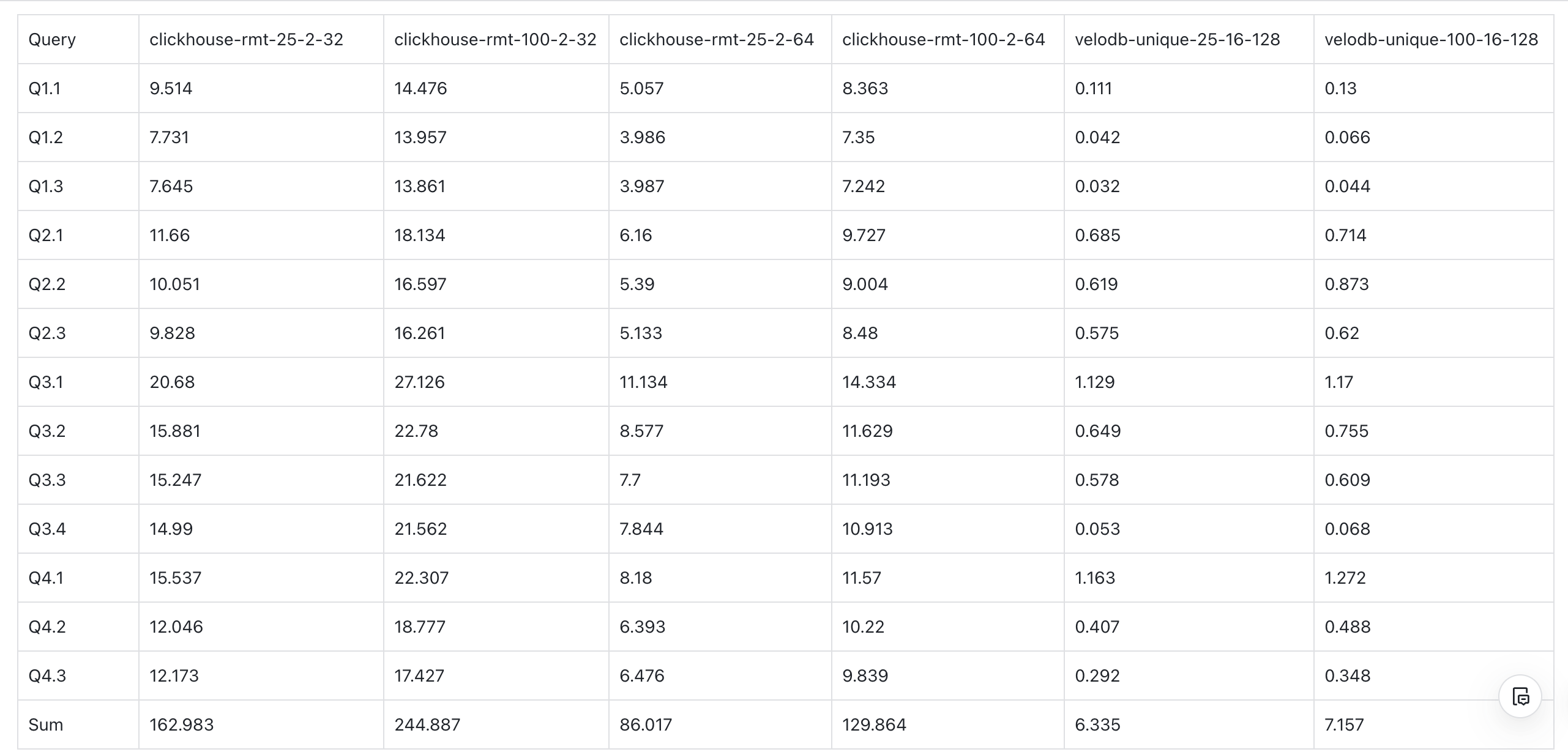
ClickBench
Similar to the SSB benchmark tests above, in the ClickBench tests, we first compared ClickHouse under MergeTree (non-real-time updates) and ReplacingMergeTree (real-time updates). As before, MergeTree performs much faster than ReplacingMergeTree.
We then compared ClickHouse and VeloDB under real-time update scenarios: ClickHouse (ReplacingMergeTree) versus VeloDB (Unique Key). Once again, VeloDB showed it is 1.7-4.6x faster than ClickHouse in real-time updates.
A. Clickhouse MergeTree vs ReplacingMergeTree
- In ClickBench, at 25% update ratio, ClickHouse MergeTree is 2.7x faster than ReplacingMergeTree.
- In ClickBench, at 100% update ratio, ClickHouse MergeTree is 3.9x faster than ReplacingMergeTree.
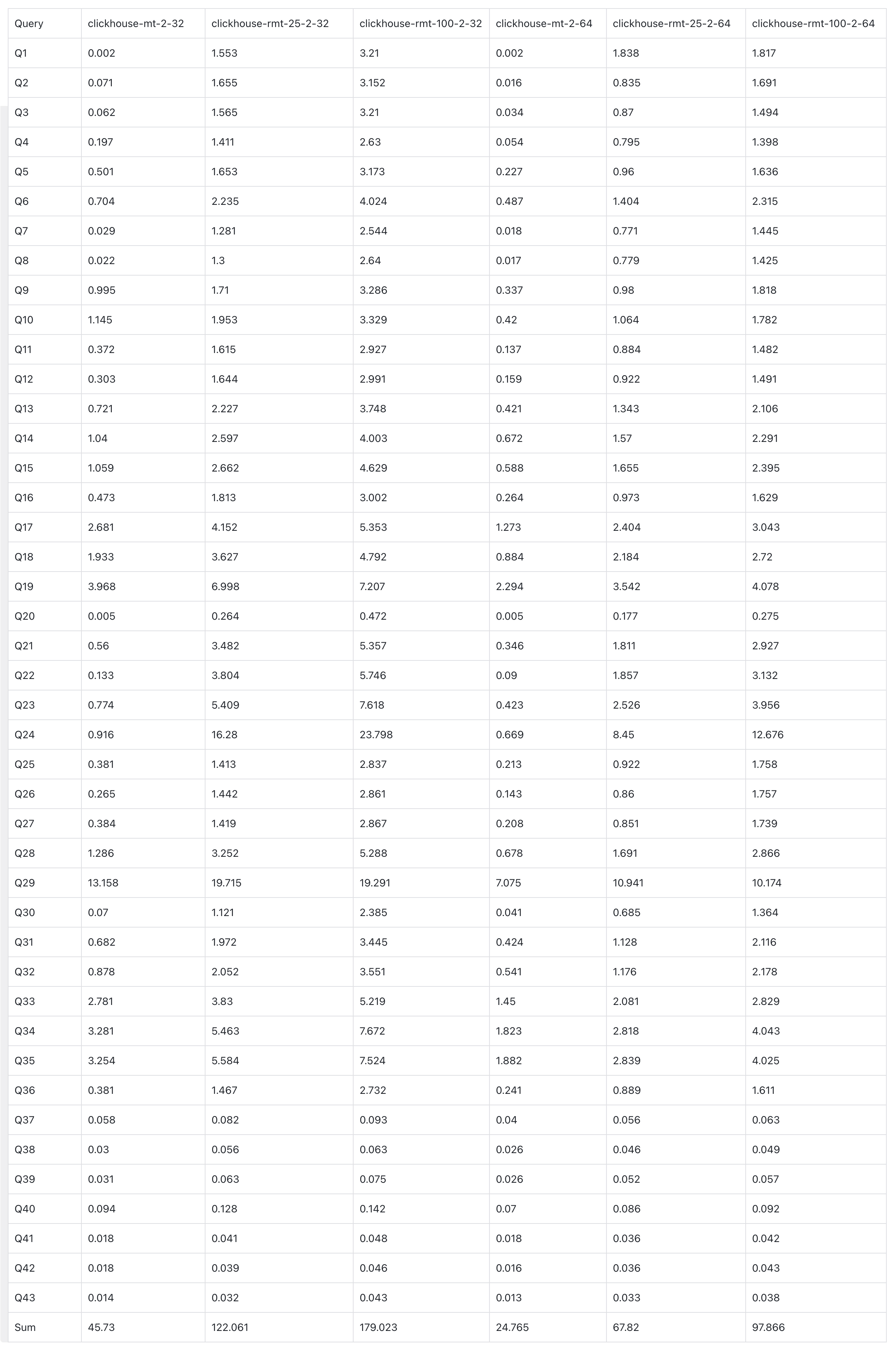
B. Clickhouse ReplacingMergeTree vs. VeloDB UniqueKey
- VeloDB (16c 128GB) vs. ClickHouse 32c 128GB (2 replicas, each replica 16c 64GB):
- At 25% update ratio, VeloDB is 1.7x faster than Clickhouse.
- At 100% update ratio, VeloDB is 2.5x faster than Clickhouse.
- VeloDB (16c 128GB) vs. ClickHouse 16c 64GB (2 replicas, each replica 8c 32GB):
- At 25% update ratio, VeloDB is 3.1x faster than Clickhouse.
- At 100% update ratio, VeloDB is 4.6x faster than Clickhouse.
Why Real-Time OLAP Matters and Key Modern OLAP Features
Initially, there were no dedicated analytical databases like OLAP (Online Analytical Processing). Most companies tried to run analytics directly on their operational databases like OLTP (Online Transaction Processing), such as MySQL, PostgreSQL, or SQL Server.
But as data volume grew exponentially, OLTP no longer fit the growing analytical needs. Because OLTP is optimized for many small, fast writes, not large analytical queries. Complex queries often caused slowdowns and could interfere with operational workloads, and aggregations across millions of rows in OLTP were inefficient.
As a result, dedicated OLAP emerged in the 1990s. And now, three decades later, OLAP has evolved from traditional data warehouses to modern data warehouses, offering real-time analytics, lakehouse capability, and cloud-native deployments.
Modern OLAP Features:
- Real-Time Processing: Real-time means low-latency in data ingestion and query execution. A modern data warehouse needs to support second-level data ingestion and millisecond-level queries in high-concurrency environments. OLAPs offering real-time capabilities are Apache Doris, ClickHouse, and Elasticsearch.
- Lakehouse: The lakehouse architecture lets businesses have the best of both worlds: data lake's low-cost, scalable storage and its ability to handle large volumes of structured, semi-structured, and unstructured data; data warehouses' real-time, low-latency analytics. Lakehouse has driven the rise of open table formats like Iceberg, Paimon, and Hudi, along with platforms such as Apache Doris, Databricks, Dremio, and Trino/Starburst, which provide analytical and query support for them.
- Cloud-Native: Most modern data warehouses support both on-premises deployments and cloud services. Cloud services often decouple compute and storage, allowing companies to enjoy the cheaper storage costs of object stores like S3 while still benefiting from fast queries. Leading cloud data warehouses are Snowflake, Redshift, and BigQuery. Apache Doris offers cloud services through VeloDB Cloud (learn more about the services here).
Apache Doris for Real-Time OLAP: Customer Story
Apache Doris is a real-time OLAP that offers low latency, high concurrency, and scalability. And the real proof comes from how customers put Apache Doris to work. In this section, we'll highlight several real-world use cases that demonstrate why companies across various industries have chosen Doris for their analytical workloads and how they're unlocking real-time insights with it.
1. Use Case: NetEase Cloud Music
Ingesting Massive Data Streams with Low Latency in Apache Doris:
NetEase (NTES: NASDAQ) is a global tech company known for its online games, e-commerce, education, and music streaming services. NetEase Cloud Music is its music streaming platform, with more than 40 million paying users. NetEase Cloud Music generates massive volumes of user behavior data, operational data, and logs on a daily basis. These data play a crucial role in tracking anomalies, pinpointing customer complaints, monitoring operational status, and optimizing performance.
NetEase Cloud Music replaced ClickHouse with Apache Doris to build a new log platform capable of handling trillions of new records daily. Doris has delivered stable performances for more than three quarters, scaling to 50 servers, 2 petabytes of data, and peak ingestion throughput of 6 GB/s, with trillions of new log entries ingested daily.
NetEase Cloud Music uses Flink + Doris Connector for data streaming. With Doris' Stream Load feature, data becomes visible within seconds, and a single node can ingest over one million rows per second, helping NetEase Cloud Music achieve real-time, high-volume data ingestion.
Key Optimizations:
- Write Process Optimization: During append operations, data is written directly into compressed streams without intermediate ArrayList buffering, cutting TM memory usage by half (from 8 GB to 4 GB) and effectively preventing out-of-memory errors caused by overly large batch sizes.
- Single Tablet Import: Enabling single tablet import (requiring tables to use a random bucket strategy), greatly improves write performance by reducing metadata overhead that occurs when dealing with many tablets.
- Load Balancing: After each batch flush, BE nodes are randomly chosen for writing data to solve uneven write load, boosting import performance by 70% compared to before.
- Enhanced Fault Tolerance: Failover strategies were improved by optimizing retry logic and increasing retry intervals. When FE or BE nodes experience failures, automatic detection and retry ensure high service availability.
For metadata performance optimization, Doris addresses sudden increases in Stream Load latency in HDD environments by switching three follower FEs to asynchronous disk flush mode, and performance improved 4 times, effectively eliminating the severe latency issues caused during the synchronous metadata write phase.
In summary, with Apache Doris, NetEase Cloud Music saw overall P99 query latency reduced by 30%, and query concurrency increased to 500+ compared to ClickHouse's 200. Doris enhances write stability, reduces operational costs, and achieves automated recovery for disk/node failures.
Read the full customer stories here.
2. Use Case: Lakala
High-Performance Query with Apache Doris:
Lakala is a global digital payment and fintech company that offers payment processing services in over 100 countries.
Lakala's earlier data platform was built on a complex Lambda architecture and faced growing challenges as the business scaled, including high storage costs, poor real-time write performance, slow responses for complex queries, and high maintenance costs due to the multiple components.
To address these issues, Lakala adopted Apache Doris to replace Elasticsearch, Hive, HBase, TiDB, and Oracle/MySQL. It built a streamlined architecture with Doris as a unified OLAP engine, and saw a 15x improvement in query performance and a 52% reduction in server count.
Detailed Improvements:
- Risk Control Query Optimization: After replacing Elasticsearch with Doris, Lakala saw query response time drop from 15 seconds to less than 1 second, a 15x boost in query speed. Doris's standard SQL query interface and superior multi-dimensional analysis capabilities support complex multi-table JOINs, subqueries, window functions, and more.
- High-Concurrency Processing for Billing Systems: Utilizing Doris' high-concurrency processing and ultrafast query capabilities, Lakala can now support processing millions of queries (up to hundreds of millions of data points), with P99 query response time less than 2 seconds and data latency less than 5 seconds.
- Inverted Index Boost Large Table Joins: By adding inverted indexes, adjusting bucketing strategies, and optimizing table structures, Doris reduced large table joins' query latency from 200 seconds to 10 seconds, a 20x performance boost.
- Light Schema Change: Elasticsearch achieves schema changes through Reindex. But Doris uses a more efficient and flexible Light Schema Change mechanism, supporting rapid addition, deletion, and modification of fields and indexes, enhancing data management convenience and business adaptability.
3. Use Case: Kwai
High-Concurrency and Unified Lakehouse with Apache Doris:
Kwai, a popular short video social media platform, has more than 700 million monthly active users. The platform handles nearly 1 billion queries daily. Its previous data warehouse and data lake architecture faced several challenges, such as storage redundancy, competing resources, and complex governance.
Kwai replaced ClickHouse with Apache Doris, utilizing Doris' unified lakehouse architecture, handling hundreds of thousands of tables and hundreds of petabytes of incremental data.
In high-concurrency processing scenarios, Doris helped Kwai to manage the following needs:
- High-Concurrent Query Performance: The system handles nearly 1 billion queries daily, meeting high-concurrency demands for systems used by both external enterprises (such as BI report engines, data management platform, ad platform, and e-commerce production selection platform) and internal teams (KwaiBI, event dashboards, app analytics, user behavior analysis, and more).
- Intelligent Query Routing: The query routing service analyzes and estimates the data scan volume of incoming queries, automatically directing large queries to the Spark engine. This prevents heavy queries from consuming excessive Doris resources, ensuring system stability under high concurrency.
- Transparent Materialized View Rewriting: Leveraging Doris' materialized view rewrite capabilities and its automatic materialization service, query performance improves at least sixfold, with data under tens of billions of rows achieving millisecond-level response times, effectively supporting high-concurrency workloads.
- Cache Optimization Acceleration: By optimizing both metadata and data caching, the average metadata access latency is reduced from 800 ms to 50 ms, significantly enhancing query response efficiency in high-concurrency scenarios.
Kwai achieved unified storage and streamlined pipeline with Doris, allowing direct access to lakehouse data without additional data imports. At the same time, it supports massive concurrent queries while reducing operational complexity and storage costs.
Read the full customer stories here.
Want to learn more about Apache Doris and its real-time updates feature? Join the Apache Doris community on Slack and connect with Doris experts and users. If you're looking for a fully-managed, cloud-native version of Apache Doris, contact the VeloDB team.


