



Just like milk in your fridge, data loses value as time goes by.
Legacy OLAP systems? They are great at crunching numbers in batches, but overwhelmed when faced with the speed and complexity of today's real-time data streams. When handling high-concurrency real-time writes and complex analytical queries, they often show signs of strain: data latency, slow query performance, limited concurrency, and inefficient data updates.
Apache Doris is built from the ground up to handle the velocity of today's data. It connects to diverse data sources with ease and delivers strong real-time update capabilities, so your data starts working the moment it's created.
So, how exactly does Apache Doris keep your data fresh, fast, and flowing with ultra-low latency?
Let's dive beneath the surface.
Challenges of real-time updates
Implementing real-time updates isn't just about speed. It's about architectural resilience under pressure. To truly support real-time performance in production, systems need to tackle several core challenges:
- Data latency: The time from data being generated to becoming queryable should be as short as possible: ideally under 1 second, and no more than 5–10 seconds in most real-world scenarios. At the same time, the system must support high write throughput, ensuring it can ingest massive volumes of updates without buckling under concurrent load.
- Query performance: The real challenge lies in serving fast queries while absorbing constant data changes. Real-time OLAP systems must maintain sub-100ms response times, even as new data streams in nonstop.
- Concurrency handling: Real-time workloads often involve both high-frequency queries and concurrent writes from multiple sources. Legacy systems that rely on table- or partition-level locking often suffer from write conflicts that degrade performance. A modern OLAP system should support fine-grained conflict resolution, ideally allowing users to define custom merge strategies.
- Data stream integrity & operational simplicity: Maintaining consistent and accurate data streams in real time isn't trivial. Challenges like CDC-captured deletes, schema evolution, and pipeline restarts (due to failures or upgrades) can easily lead to duplicate records or data loss. A robust system needs built-in mechanisms to guarantee exactly-once semantics, seamless schema handling, and fault-tolerant ingestion.
These challenges are key indicators for evaluating whether an OLAP system truly possesses real-time update capabilities.
Comparing common solutions
When it comes to handling real-time data updates, most modern data systems tackle three key dimensions:
- How updates are expressed
- How updates are physically implemented
- How conflicts are resolved
Each system offers different trade-offs depending on the use case.
01 Expression method: how updates are defined
In many platforms like Snowflake, Redshift, Apache Iceberg, Databricks, and Hudi, data updates are typically handled via the SQL MERGE INTO pattern. While flexible, this approach requires writing the change data to disk first, and then performing a batch merge operation. This two-step process introduces latency and additional I/O overhead.
In contrast, Apache Doris and ClickHouse take a more lightweight, real-time-friendly approach: they use special column markers to flag delete or update operations, embedding these changes directly into the same data stream. This model is better suited for high-velocity scenarios like transactional record updates, order status changes, or event-driven systems.
02 Update implementation: how changes are executed internally
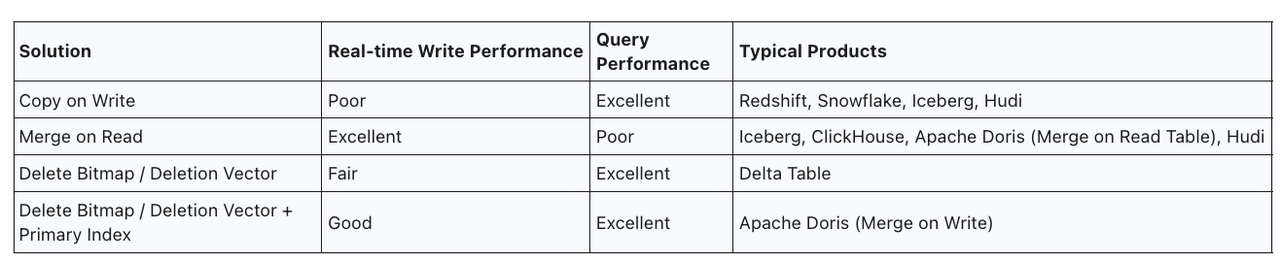
-
Copy-on-Write (CoW)
This method identifies the files that need to be updated, reads them, merges in the new data, and then writes out a brand-new file. While it delivers strong query performance, it comes at a heavy cost: massive I/O during writes, especially for random updates. This method is used by Redshift, ClickHouse, Snowflake, Apache Iceberg, and Apache Hudi. ClickHouse mitigates some of the cost through background merges, but that leads to eventual consistency and weaker performance for strongly consistent reads.
-
Merge-on-Read (MoR)
This write-optimized approach appends new data only, deferring the merge of old and new records to query time, similar to how LSM Trees work. While it greatly reduces write latency and supports high-ingest throughput, it hurts query performance. This method is used by Apache Iceberg, Apache Hudi, Apache Doris (MoR Unique tables).
-
Delete Bitmap / Deletion Vector
This strategy marks records for deletion by writing logical delete flags alongside incoming data. During queries, the engine simply skips over these flagged rows. It strikes a balance between CoW and MoR, maintaining high query performance without triggering expensive rewrite operations.
However, if there's no primary key index, generating these delete markers (Delete Bitmap / Deletion Vector) can become a performance bottleneck, consuming significant I/O and CPU, especially during high-frequency updates.
-
Delete Bitmap / Deletion Vector + Primary Index
This is a hybrid approach that pairs deletion markers with a primary key index. The index largely reduces the cost of identifying and flagging rows to delete, making it viable for high-frequency, real-time updates while still maintaining efficient query paths. This method is used by Apache Doris (Merge-on-Write Unique tables).
03 Conflict resolution: the hidden bottleneck
One of the biggest blockers to scaling real-time data systems is write-write conflict: When multiple concurrent writes collide, forcing the system to serialize them. This kills parallelism and drastically reduces write throughput.
Apache Doris addresses this head-on with a business-semantic-aware conflict resolution mechanism.(See the docs for details) By contrast, systems like Redshift, Snowflake, Iceberg, and Hudi handle conflicts at the file level, which is inherently slower and unsuitable for real-time applications.
In the following sections, we'll break down how Apache Doris delivers ultra-low-latency updates at scale.
Why Apache Doris excels at real-time updates
Traditional OLAP databases were originally built for batch analytics, with data refresh cycles measured in hours or even days. That model works fine for internal reporting systems, but it falls short in today's fast-paced, user-facing analytics world.
Modern applications demand much more:
- Sub-second query latency
- Second-level data freshness
- Millions of records ingested per second
- Low-latency analytics at massive scale
Apache Doris rises to this challenge with a real-time update architecture that combines primary key model, low data latency, fast query performance, high concurrency handling, and overall ease of use.
01 Primary key model
One of the foundations of Apache Doris' real-time update capability is its primary key table model, which enforces row-level uniqueness and supports native upsert semantics. This allows incoming updates to directly overwrite existing records based on the primary key: no manual deduplication or batch merges needed.
Here's a quick example of creating a primary key table with user_id as the unique identifier:
CREATE TABLE IF NOT EXISTS example_tbl_unique (
user_id LARGEINT NOT NULL,
user_name VARCHAR (50) NOT NULL,
city VARCHAR (20),
age SMALLINT,
sex TINYINT
) UNIQUE KEY (user_id) DISTRIBUTED BY HASH (user_id) BUCKETS 10;
In this table, the initial dataset contains four rows: 101, 102, 103, and 104. When new records with the same primary keys (101 and 102) are written, the total row count remains unchanged at four: the values for 101 and 102 are simply updated in place, replacing the previous entries.
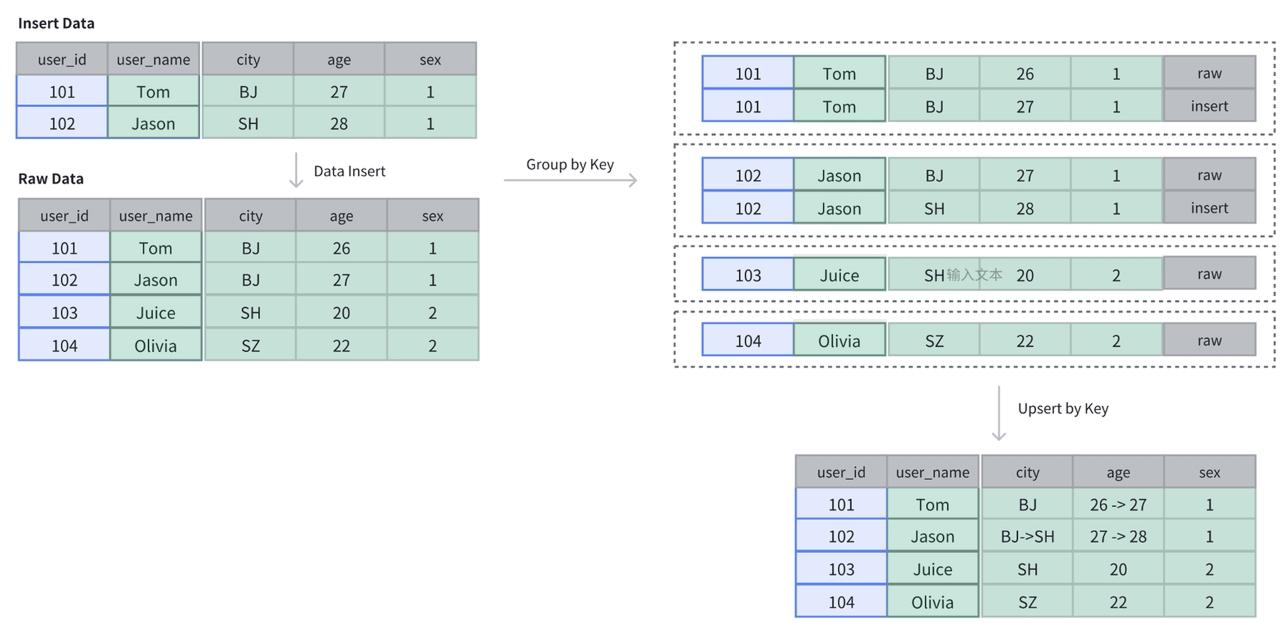
Read the doc for more details.
02 Low data latency
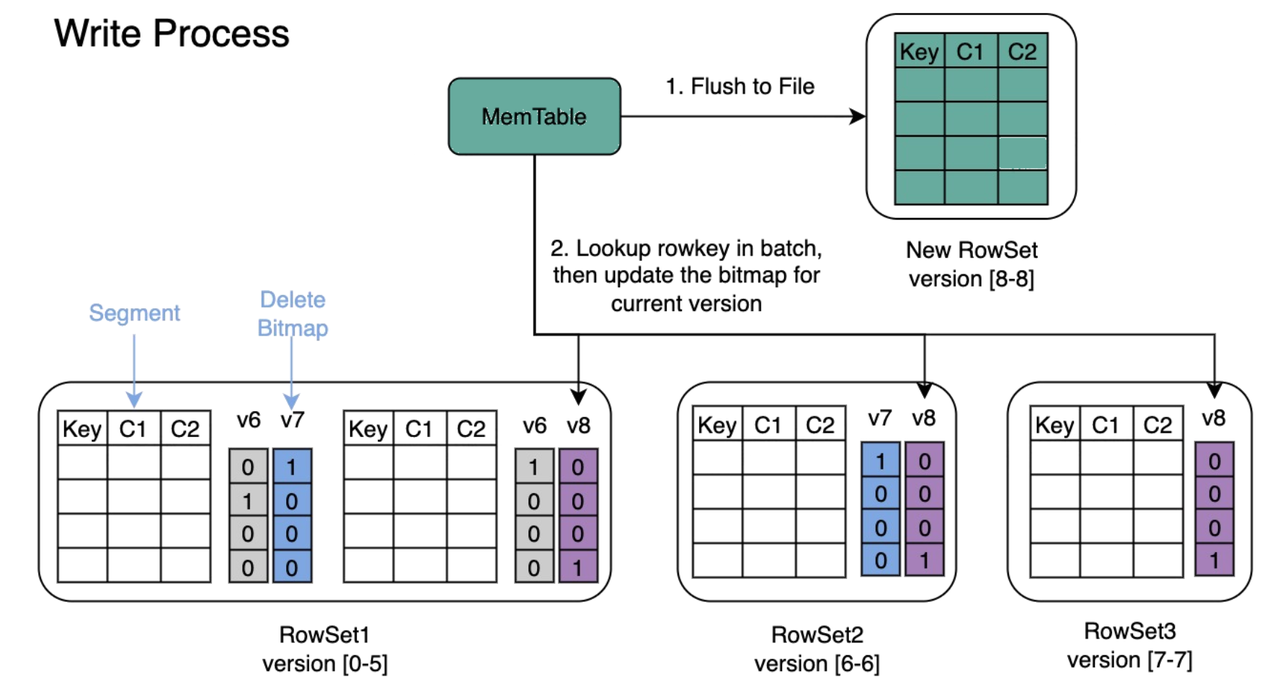
Apache Doris offers strong consistency semantics, ensuring that data becomes immediately queryable after it's written. Under the hood, Apache Doris organizes data using an LSM Tree-like structure, and handles updates through Delete Bitmaps rather than traditional Copy-on-Write mechanisms. This approach significantly reduces I/O overhead and improves write throughput by avoiding costly file rewrites. It also minimizes storage waste and lightens system load, resulting in more efficient and scalable data processing.
On top of that, Apache Doris leverages primary key indexing to accelerate the lookup and replacement of historical records during updates. This not only boosts write performance but also lowers CPU and memory consumption.
Together, these design choices enable Apache Doris to achieve sub-second data freshness.
03 Fast query performance
In real-time update scenarios, Apache Doris leverages Delete Bitmap to boost query performance. Unlike the Merge-on-Read approach, which requires runtime computation to reconcile old and new data, Apache Doris uses lightweight deletion markers to skip over outdated rows at query time. This enables sub-100ms response times even under high-concurrency workloads.
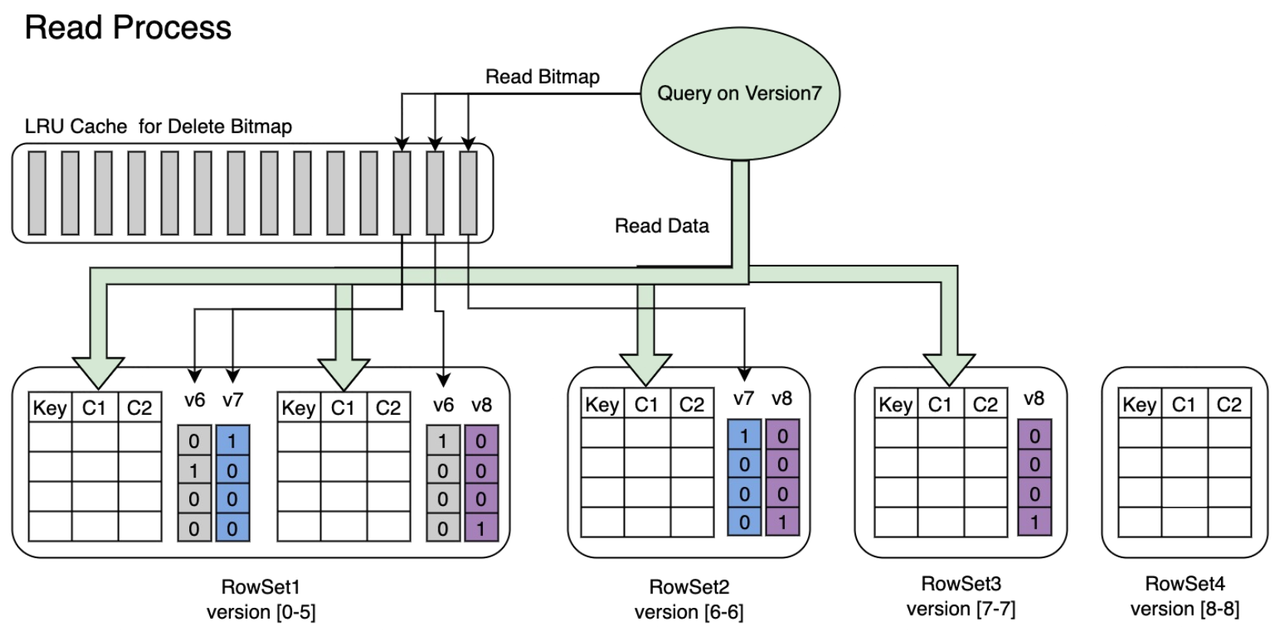
To further accelerate queries at scale, Apache Doris integrates a suite of advanced techniques:
- Smart partition & bucket pruning: By intelligently skipping irrelevant partitions and buckets, Apache Doris minimizes unnecessary data scans, improving I/O efficiency and speeding up query execution.
- Vectorized execution engine: Apache Doris processes data in batches using a fully vectorized engine. This reduces CPU context switching and maximizes throughput, especially for large-scale analytical queries.
- Cost-based optimizer: The built-in optimizer of Apache Doris automatically chooses the most efficient query plan based on real-time conditions. It avoids redundant computations and adjusts execution paths on the fly to improve response times.
- Rich indexing for precise and efficient filtering:
Apache Doris supports multiple index types to serve different query patterns, including point lookup indexes and skip-level indexes. Point lookup indexes (e.g., prefix indexes, inverted indexes) speed up exact-match queries by directly locating rows that match WHERE conditions. Skip-level indexes (e.g., ZoneMap, BloomFilter, NGram BloomFilter) help eliminate irrelevant data blocks before scanning. These indexes identify blocks that definitely don't match query filters, so Apache Doris can skip them entirely and focus only on likely candidates, reducing data scan volume and improving performance.
Thanks to this deep optimization stack, Apache Doris delivers fast, consistent, low-latency query performance, even in write-heavy, highly concurrent environments.
04 High concurrency handling
Apache Doris' primary key tables are designed to handle write conflicts using application-defined semantics, enabling eventual consistency even under high-concurrency and out-of-order writes.
When creating a table, users can specify a SEQUENCE COLUMN to define custom MVCC (Multi-Version Concurrency Control) conflict resolution logic. During data ingestion, the load balancer favors rows with larger values in the SEQUENCE COLUMN, allowing the most up-to-date version of a record to take effect.
This mechanism handles both conflicting writes and updates to existing data. A typical real-world example is syncing OLTP tables where the modify_date field is updated with the current timestamp on every change.
CREATE TABLE test.test_table (
user_id bigint,
date date,
group_id bigint,
modify_date date,
keyword VARCHAR (128)
) UNIQUE KEY (user_id, date, group_id) DISTRIBUTED BY HASH (user_id) BUCKETS 32 PROPERTIES(
"function_column.sequence_col" = 'modify_date',
"replication_num" = "1",
"in_memory" = "false"
);
When streaming change data (CDC) from an OLTP system into Apache Doris, setting modify_date as the SEQUENCE COLUMN ensures that only the latest version of each record is retained. If a later-ingested row has an older modify_date, it’s automatically discarded, preserving consistency without introducing unnecessary I/O or complexity.
Read the doc for more details: https://doris.apache.org/docs/data-operate/update/unique-update-concurrent-control
05 Overall ease of use
-
Atomic writes & immediate consistency
Apache Doris guarantees data consistency and integrity with every write, even under massive concurrency and real-time update pressure. Combined with its delete bitmap mechanism, updates are executed efficiently. This reduces storage overhead and boosting query performance without sacrificing accuracy.
-
Online schema evolution & fine-grained column updates
Apache Doris supports online schema changes, allowing users to adjust table structure on the fly without complex data migrations. This makes maintaining real-time pipelines much simpler. Its column-level update capability lets users update only the fields that changed, avoiding the performance cost of rewriting entire rows, especially valuable in frequently updated datasets.
-
Hidden delete columns for lightweight deletes
For every Unique Key table, Apache Doris generates a hidden
DORIS_DELETE_SIGNcolumn to efficiently mark deletions. This allows rows to be logically removed without relying on heavyweight delete operations, improving system throughput. By combining this with a SEQUENCE COLUMN, Apache Doris ensures that deletion of outdated records never overrides newer data, making real-time update and cleanup workflows both reliable and fast.
Ecosystem integration
Apache Doris is built with openness and flexibility in mind. It provides a rich set of APIs and connectors that make it easy to integrate with popular data processing frameworks like Apache Spark, Apache Flink, and Apache Kafka.
01 Kafka integration
Apache Doris supports native integration with Kafka Connect, a distributed and scalable tool for streaming data in and out of Kafka. Using the Doris Kafka Connector, users can continuously consume messages from Kafka topics and write them directly into Doris for real-time analytics.
Setting up a Doris Sink Connector on your Kafka Connect cluster is simple. Here's an example configuration:
For step-by-step instructions, check out the doc.
curl -i http://127.0.0.1:8083/connectors -H "Content-Type: application/json" -X POST -d '{
"name":"test-doris-sink-cluster",
"config":{
"connector.class":"org.apache.doris.kafka.connector.DorisSinkConnector",
"topics":"topic_test",
"doris.topic2table.map": "topic_test:test_kafka_tbl",
"buffer.count.records":"50000",
"buffer.flush.time":"120",
"buffer.size.bytes":"5000000",
"doris.urls":"10.10.10.1",
"doris.user":"root",
"doris.password":"",
"doris.http.port":"8030",
"doris.query.port":"9030",
"doris.database":"test_db",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"value.converter":"org.apache.kafka.connect.json.JsonConverter"
}}'
02 Flink integration
Apache Flink is a powerful framework and distributed processing engine designed for stateful computations over both bounded and unbounded data streams. With the Flink Doris Connector, you can stream data from upstream sources like Kafka, MySQL, or any Flink-supported source directly into Apache Doris, enabling real-time analytics at scale.
Here’s a quick example of using DataGen with Flink SQL to continuously generate mock data and insert it into Doris:
For step-by-step instructions, check out the doc.
SET 'execution.checkpointing.interval' = '30s';
CREATE TABLE student_source (
id INT,
name STRING,
age INT
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.name.length' = '20',
'fields.id.min' = '1',
'fields.id.max' = '100000',
'fields.age.min' = '3',
'fields.age.max' = '30'
);
-- doris sinkCREATE TABLE student_sink (
id INT,
name STRING,
age INT
) WITH (
'connector' = 'doris',
'fenodes' = '127.0.0.1:8030',
'table.identifier' = 'test.student',
'username' = 'root',
'password' = 'password',
'sink.label-prefix' = 'doris_label'
);
INSERT INTO student_sink SELECT * FROM student_source;
03 Spark structured streaming
Structured Streaming is a scalable and fault-tolerant stream processing engine built on top of the Apache Spark SQL engine. It allows you to efficiently consume data from upstream sources and perform real-time computations using familiar SQL or DataFrame APIs.
By leveraging the Spark Doris Connector, you can use Stream Load to write data into Apache Doris in real time, enabling a seamless end-to-end streaming data pipeline from source to analytics.
To quickly test this setup, you can simulate a data stream using Spark's built-in rate source and write the streaming data into Aapche Doris. Here’s a simplified example:
For full implementation details, refer to the complete example code here.
val spark = SparkSession.builder()
.appName("RateSourceExample")
.master("local[1]")
.getOrCreate()
val rateStream = spark.readStream
.format("rate")
.option("rowsPerSecond", 10)
.load()
rateStream.writeStream
.format("doris")
.option("checkpointLocation", "/tmp/checkpoint")
.option("doris.table.identifier", "db.table")
.option("doris.fenodes", "127.0.0.1:8030")
.option("user", "root")
.option("password", "")
.start()
.awaitTermination()
spark.stop();
User stories
- A leading express delivery company with one of the largest parcel volumes in the logistics industry
With rapid business growth, the former peak-season traffic for this leading express delivery company has become the new normal every single day! However, the legacy data architecture struggled to keep up, facing mounting challenges in data freshness, query performance, and maintenance overhead.
To address these bottlenecks, the company adopted VeloDB, which is now powering real-time logistics analytics, BI reporting, offline data analysis, and high-concurrency query workloads across the organization.
In real-time use cases, VeloDB accelerates query results through its rich SQL expression support and high-throughput compute engine, supporting over 2,000 QPS for concurrent queries. This has largely improved the timeliness and accuracy of data dashboards and operational reporting.
Today, VeloDB processes 600+ million records daily, manages 4.5+ billion total rows across 200+ columns, and has helped the company reduce server resource consumption by 70%. Query latency has been slashed from 10 minutes to seconds, delivering performance gains by an order of magnitude.
- A top-tier consumer finance company
This user operates two major consumer finance product lines, offering fully online, unsecured, and low-interest credit services designed for inclusive lending.
Their original data infrastructure followed a classic Lambda architecture, involving a complex stack of ClickHouse, Spark, Impala, Hive, Kudu, and Vertica. However, it faced serious limitations: high operational overhead, low resource efficiency, poor data freshness, and limited concurrency.
To address these challenges, the company adopted Apache Doris for a full architecture upgrade, achieving real-time analytics, simplified architecture, hybrid deployment, and elastic scalability.
In customer segmentation analysis scenarios, the previous Vertica-based solution took 30–60 minutes to process 240 million records. After switching to Apache Doris, the same workload was completed in just 5 minutes. That's a 6x performance boost. As an open-source solution, Apache Doris also brings significant cost savings over commercial systems like Vertica.
Conclusion
Apache Doris shines in real-time analytics with its robust capabilities. For primary key tables, Apache Doris delivers seamless UPSERT semantics, leveraging primary key indexes and a mark-for-deletion mechanism to ensure top-notch write performance and low-latency queries. Plus, its user-defined conflict resolution boosts concurrency for real-time writes, while fast Schema Change functionality keeps data flows uninterrupted. Flexible column updates and options further empower a wide range of real-time use cases with ease.
Looking ahead, we're doubling down on:
- Reducing data visibility latency for a near-instantaneous data access experience.
- Enhancing ecosystem tools to auto-optimize schema adjustments and broaden the scope of Light Schema.
- More dynamic column updates, giving users smarter, more efficient data management.
Apache Doris is all about making real-time analytics faster, smoother, and more adaptable for modern data needs. If you're interested in this topic, you're more than welcome to join the discussion in the Apache Doris community on Slack.
Or give VeloDB Cloud a try to experience the ultra-fast real-time update capabilities of Apache Doris!


