


No need to worry about sampling if you can collect all the logs
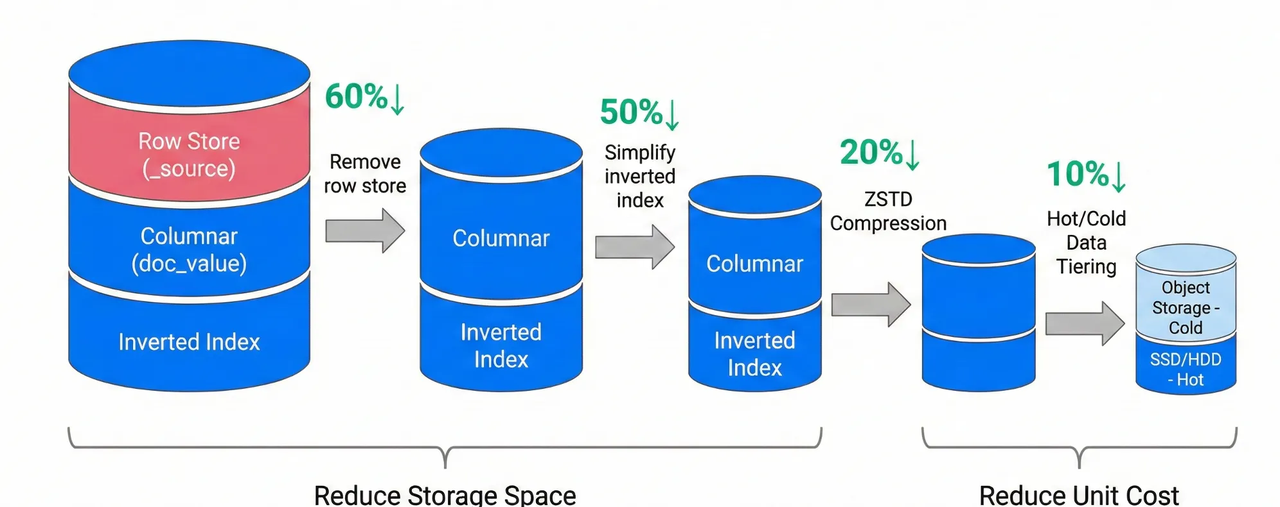
VeloDB and Apache Doris store a single copy of data in columnar format with ZSTD compression, reducing storage cost up to 10X, so you don’t have to worry about fine-tuning your collection strategy to manage cost
Ingest without the bottleneck
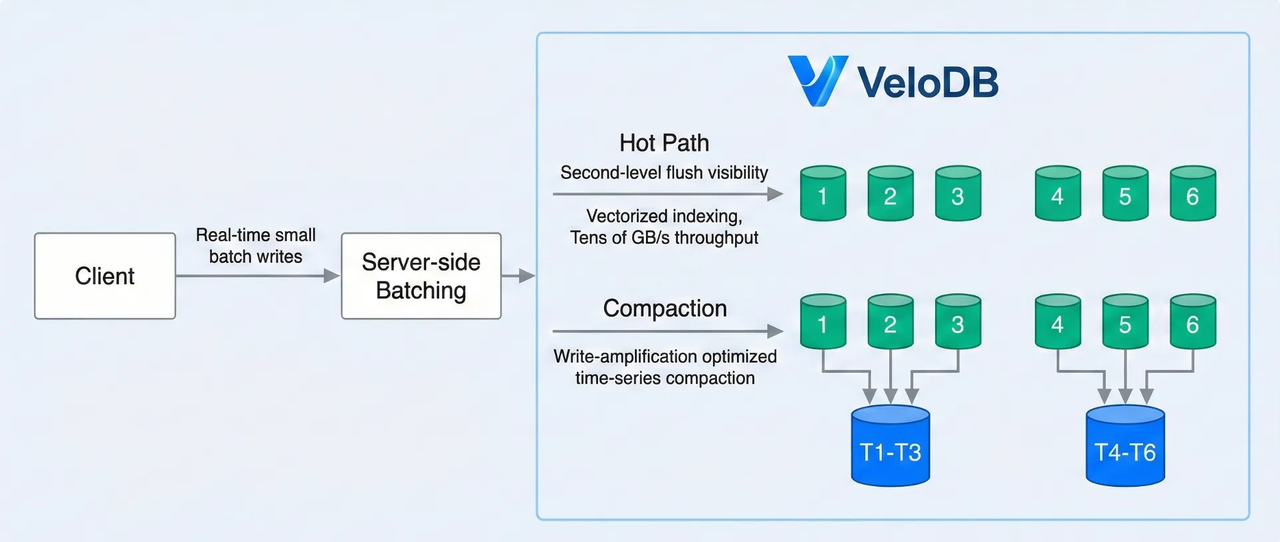
VeloDB is able to achieve tens of GB/S throughput with vectorized indexing and time-series compaction on the commit, providing second-level flush visibility and high throughput at the same time without the need for both a row copy and a columnar copy
Hear from our customers and users on their journey from ElasticSearch to VeloDB and Apache Doris
Learn more about Hybrid Search and Analytic processing