


In Natural Language Processing (NLP), particularly within Information Retrieval (IR) and semantic similarity tasks, the Bi-Encoder and Cross-Encoder represent the two dominant model architectures. They play complementary roles, optimizing different aspects of the system's performance—speed versus accuracy—and are foundational to modern search and generative systems like RAG.
This article details their working mechanisms, core applications, and essential role in the Reranking stage of high-performance systems.
1. Bi-Encoder: The Efficiency Expert (Retrieval)
The core principle of the Bi-Encoder architecture is independent encoding for rapid comparison. Its goal is to transform text into highly efficient vector representations (embeddings) suitable for fast, large-scale retrieval.
How It Works
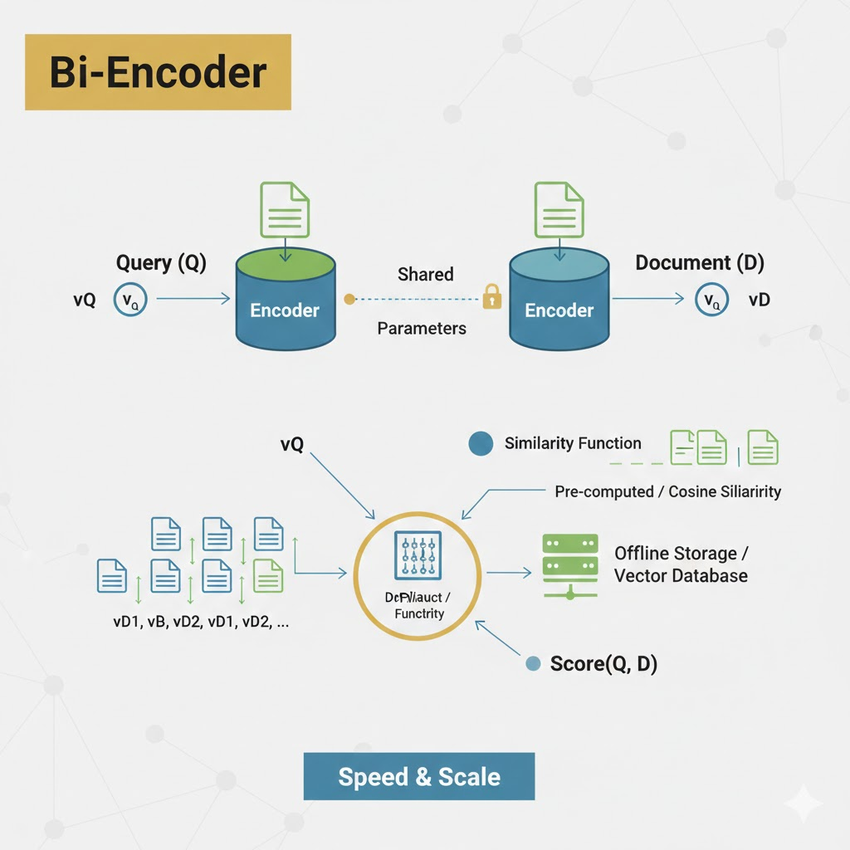
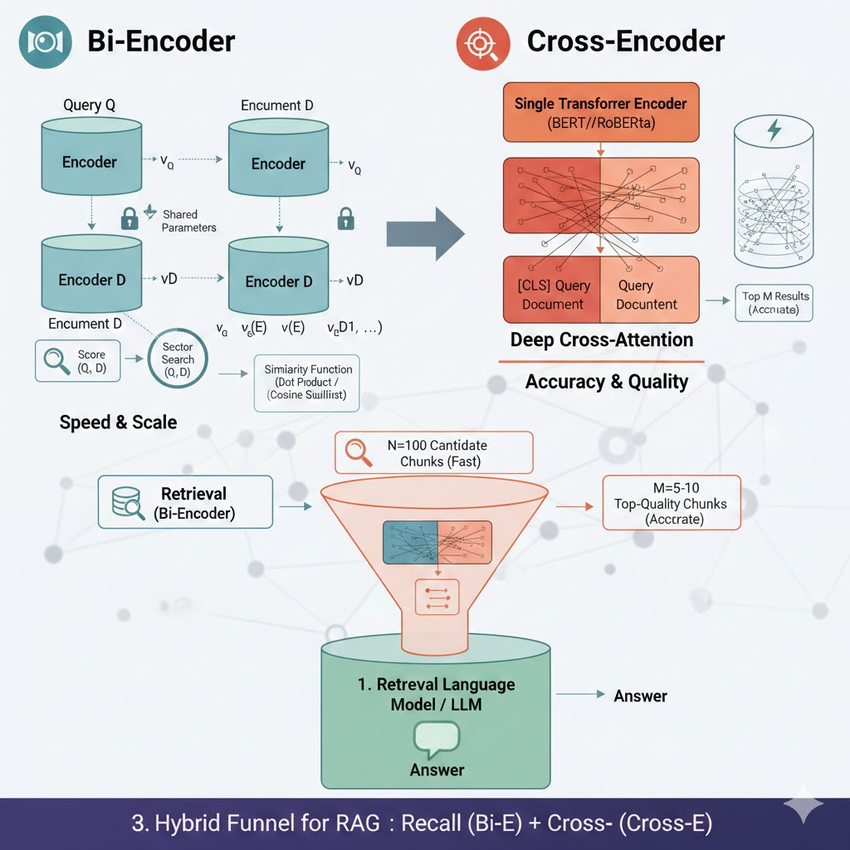
A Bi-Encoder uses two separate (though typically parameter-shared) Transformer models to process the Query (Q) and the Document (D).
- Independent Encoding: The query Q is encoded into vector v_Q, and the document D is encoded into vector v_D.
- Similarity Calculation: The relevance score is computed by measuring the vector similarity (e.g., Dot Product or Cosine Similarity) between v_Q and v_D.
Core Use & Advantage
The major advantages are high efficiency and scalability. Since document vectors (v_D) can be pre-calculated and stored offline, the system only needs to calculate v_Q at query time and perform a fast vector search to find the initial set of candidates. It is the architecture of choice for the Retrieval (Recall) stage in large-scale systems.
2.Cross-Encoder: The Accuracy Judge (Reranking)
The core principle of the Cross-Encoder architecture is joint encoding for deep interaction. It trades computational speed for the highest possible semantic matching accuracy.
How It Works
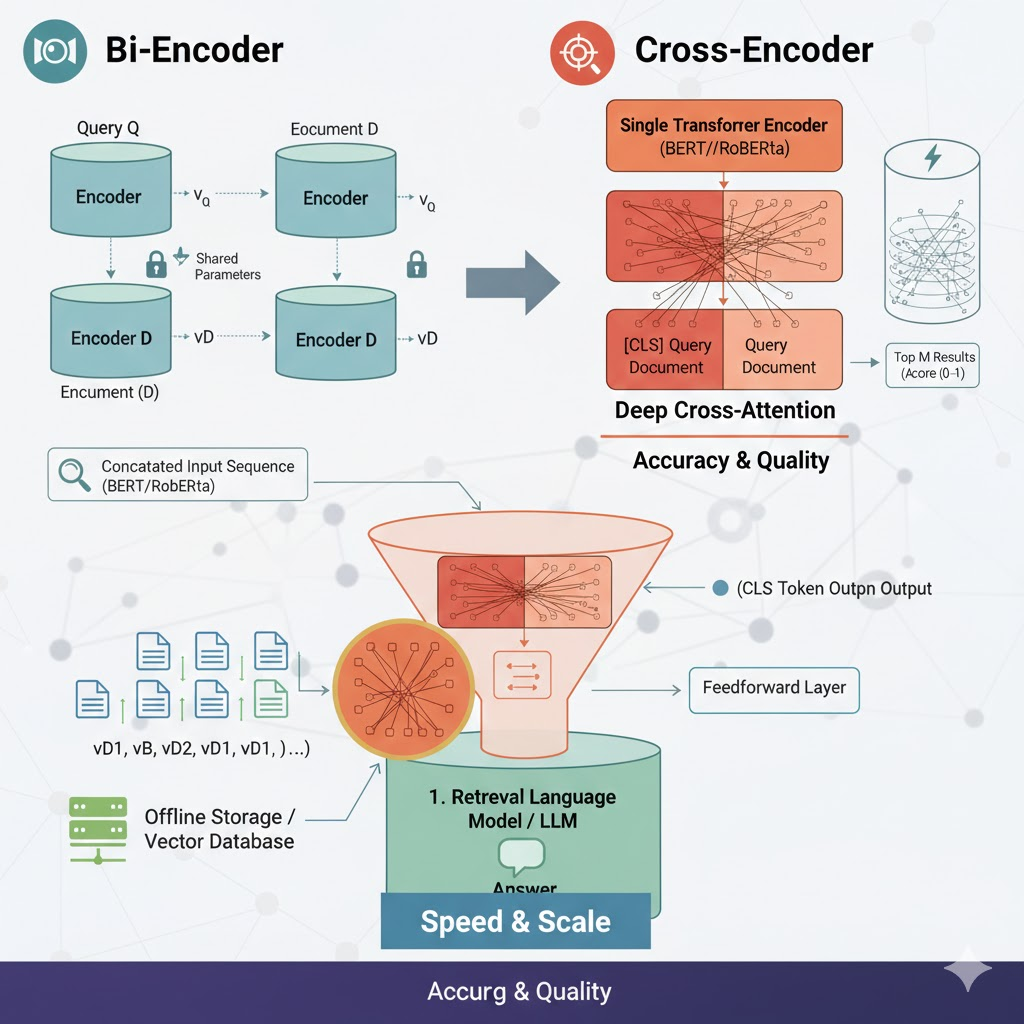
A Cross-Encoder uses a single Transformer model to process both the query Q and the document D.
- Sequence Concatenation: Q and D are concatenated into a single input sequence:
S = [CLS] \ Q \ [SEP] \ D \ [SEP]. - Joint Encoding & Cross-Attention: The Self-Attention mechanism allows every token in the query to interact directly with every token in the document in every layer. This deep cross-attention captures the most subtle semantic dependencies and match patterns.
- Relevance Prediction: The model uses the output vector of the [CLS] token to predict a precise relevance score.
Core Use & Advantage
The major advantage is high accuracy. Due to the high computational cost (running the full model for every pair), it is primarily used for Reranking—sorting a small, already-retrieved list of candidates.
3.Recommended Practical Usage: The Hybrid Funnel
In real-world systems, especially in RAG, the optimal approach is to combine the two architectures into a multi-stage Efficiency-Accuracy Funnel.
The Critical Reranking Step
The Reranking step, powered by the Cross-Encoder, is vital for filtering out context that is superficially similar but semantically irrelevant—a common failure mode of Bi-Encoders.
| Stage | Model Type | Goal | Output |
|---|---|---|---|
| Stage 1: Initial Retrieval | Bi-Encoder | Speed and Coverage: Quickly filter millions of documents. | N Candidate Documents (e.g., N=100) |
| Stage 2: Reranking (Cross-Encoder) | Cross-Encoder | Precision and Quality: Refine the candidate list. | Top M Highest-Quality Documents (e.g., M=5-10) |
The Typical Rerank Implementation:
- Input: The N candidate documents/chunks (D_1, D_2, \dots, D_N) retrieved by the Bi-Encoder.
- Iterative Scoring: For each candidate document D_i in the retrieved set, the following steps are repeated:
- Input Construction: A single sequence is formed:
[CLS] <Query Text> [SEP] <Document_i Text> [SEP]. - Inference: This sequence is passed through the pre-trained Cross-Encoder model (e.g., from the Hugging Face ecosystem or a commercial API like Cohere Rerank).
- Score Output: The Cross-Encoder outputs a highly accurate relevance score S_i (typically between 0 and 1) for that specific query-document pair.
- Input Construction: A single sequence is formed:
- Final Selection:
- All N candidates are sorted in descending order based on their Cross-Encoder scores S_i.
- Only the Top M chunks are selected and passed to the next stage.
Application in RAG Systems
The Reranking stage is non-negotiable for high-quality RAG, as the LLM's output quality is directly proportional to the quality of the context it receives.
Image: RAG Funnel Diagram: Bi-Encoder for Stage 1, Cross-Encoder for Stage 2 (Reranking), leading to the LLM for Generation.
In summary, the Bi-Encoder provides the initial speed and scale, while the Cross-Encoder ensures the final quality and precision—a powerful combination essential for robust, enterprise-grade semantic systems.
