



At the core of database systems, the query optimizer acts as a shrewd strategist, constantly analyzing data traits to devise the optimal execution plans. Apache Doris, a high-performance MPP analytical database, employs a built-in Data Trait analysis mechanism in its optimizer. By uncovering statistical traits and semantic constraints within the data, Data Trait provides fundamental support for query optimization. Let’s explore its power!
What Is Data Trait?
Imagine if you could predict the traits of your data — wouldn’t that help you handle it more intelligently? Data Trait serves as a "trait description" for query data and intermediate results. In Doris, it currently covers four key traits:
- Uniqueness: The "ID Card" of Data This means that each data in the column is unique. Mathematically,
NDV (Number of Distinct Values) = Total Rows in the Tabl``e. - Uniformity: The "Copy-Paste" of Data This means that a column displays uniformity when all its values are identical (i.e., non-null distinct values ≤ 1). Fun fact: Such columns are like military uniforms—perfectly identical. The optimizer can apply special strategies to process them.
- Equal Set: The "Twins" of Data This means that when two columns match perfectly across all rows (including NULL values), they form an equal set. Note: Doris’ equal-set judgment is NULL-sensitive (i.e.,
NULL ≠ NULL). - Functional Dependency: The "Causality" of Data This means that functional dependency exists when a set of columns (X) uniquely determines another set (Y).
- X is called the determinant.
- Y is called the dependency. Formal definition:
∀X, Y ⊆ R, X → Y ⇔ ∀t₁, t₂ ∈ R, t₁[X] = t₂[X] ⇒ t₁[Y] = t₂[Y]Here,t[X]denotes the projection of tupleton attribute setX.
Representation of Data Trait
Uniqueness
Uniqueness is described using UniqueDescription. Think of a corporate employee management system:
- Single-column uniqueness (slots): Like employee IDs (e.g., 101, 102), which are unique across the company.
- Composite uniqueness (slotSets): Like "department + name" combinations. While departments or names alone may repeat (e.g., multiple "R&D" employees or shared names), the pair "R&D + Zhang San" is unique across the company.
Uniformity
Uniformity is described using UniformDescription, which includes:
- Uniform columns with known values (with specific
value):- Example:
WHERE department = 'R&D'—here, thedepartmentcolumn has only "R&D" in the result set. - Similarly,
SELECT 1 AS const_valuecreates a column where all rows equal1.
- Example:
- Uniform columns with unknown values (no specific
value):- Example: After
LIMIT 1, all columns share the same value, but the exact value is uncertain.
- Example: After
Equal Set
Equal sets are managed by a disjoint-set data structure (a highly efficient approach), like a family tree:
- Each column starts as an "individual."
- When two columns are proven identical (e.g., via a predicate like
a = b), they merge into the same "family." - Ultimately, all equivalent columns form "family trees" where members are interchangeable.
Functional Dependency
Functional dependencies are implemented as a directed graph, like corporate reporting lines:
- Nodes: Represent sets of columns (e.g., employee ID, department ID).
- Edges (→): Indicate determinant relationships, such as:
employee_ID → employee_name(knowing the ID to determine the name).department_ID + project_ID → project_manager(composite determinant).
- This network is transitive: If
A→BandB→C, thenA→C.
How Is Data Trait Derived?
- Layer-by-Layer Investigation Starting from the bottom of the query plan, each processing node, such as scan, filter, or join, generates its own data trait report based on its specific traits.
- Lazy Evaluation Mechanism Traits are computed only when needed by the optimizer, thereby avoiding unnecessary analysis overhead.
- Trait Composition Higher-level nodes combine traits from their child nodes with their own operational logic to derive new, comprehensive trait descriptions.
Additionally, Data Traits can also be derived from one another:
- A unique slot can determine all other slots.
- A uniform slot depends on all other slots.
- Equal slots are mutually dependent.
- Equal slots share the same uniqueness and uniformity properties.
Example of the Derivation Process of Data Trait
SELECT dept_id, COUNT(*) AS emp_count FROM employees
GROUP BY dept_id;
Taking the above SQL as an example, we explain the derivation process of DATA TRAIT. The query plan is as follows:
[Aggregate]
|
[Scan]
Scan Layer
When scanning the employees table, the optimizer finds:
- Unique identifier: emp_id is a UNIQUE KEY and therefore unique.
- Functional dependency: Because emp_id is a UNIQUE KEY, it can determine the values of all other columns in the table (knowing an employee's ID allows us to determine their department, name, and other information).
Aggregate
When performing a GROUP BY aggregation, data trait changes:
Uniqueness Changes
- Added: dept_id is the grouping key and therefore unique.
- Lost: The original uniqueness of emp_id is no longer valid because multiple rows are collapsed into the group.
Functional Dependency Changes
- Added: dept_id now becomes the new "determinant," allowing us to determine the number of employees in a department (emp_count) (like knowing the department number allows us to find the headcount of that department).
- Lost: All functional dependencies based on emp_id become invalid because the employee-level information is collapsed by the aggregation operation.
How Does Data Trait Optimize Queries? The Magic of Rule Application
Below, we demonstrate how Data Trait plays a role in actual query optimization through an example. We begin by creating a table and gradually demonstrate how the optimizer uses data traits to perform magic optimizations.
Preparing the test environment
The table creation and data insertion SQL statements are as follows:
-- Employee table (contains unique ID)
DROP TABLE IF EXISTS employees;
CREATE TABLE employees (
emp_id INT NOT NULL,
emp_name VARCHAR(100),
email VARCHAR(100),
dept_id INT,
salary DECIMAL(10,2),
hire_date DATE
) UNIQUE KEY(emp_id) DISTRIBUTED BY HASH(emp_id) PROPERTIES('replication_num'='1');
-- Department table (contains unique ID)
DROP TABLE IF EXISTS departments;
CREATE TABLE departments (
dept_id INT NOT NULL,
dept_name VARCHAR(100),
location VARCHAR(100)
) UNIQUE KEY(dept_id) DISTRIBUTED BY HASH(dept_id) PROPERTIES('replication_num'='1');
-- Order table (contains unique ID)
DROP TABLE IF EXISTS orders;
CREATE TABLE orders (
order_id INT NOT NULL,
customer_id INT,
order_date DATE,
amount DECIMAL(10,2)
) UNIQUE KEY(order_id) DISTRIBUTED BY HASH(order_id) PROPERTIES('replication_num'='1');
-- Insert test data
INSERT INTO departments SELECT number, concat('name',cast(number as string)), concat('location', cast(number as string)) from numbers("number"="30");
INSERT INTO employees SELECT number, concat('name',cast(number as string)), concat('email',cast(number as string)),number % 30, number, '2025-01-01' from numbers("number" = "100000000");
INSERT INTO orders VALUES
(1001, 5001, '2023-01-10', 999.99),
(1002, 5001, '2023-02-15', 1499.99),
(1003, 5002, '2023-01-20', 799.99),
(1004, 5003, '2023-03-05', 2499.99);
Data Trait Optimization Practice
Eliminating Unnecessary Join Operations (ELIMINATE_JOIN_BY_UK)
Scenario: When executing a left join where the join key in the right table is unique (multiple NULL values are permitted) and the query only requires data from the left table...
Magic: The join can be safely eliminated! Since the right table will either match exactly one row or not match at all, this operation safeguards the completeness of data in the left table.
Example:
-- Original query
SELECT COUNT(emp_id) FROM (
SELECT e.emp_id
FROM employees e
LEFT OUTER JOIN departments d ON e.dept_id = d.dept_id) t;
-- Optimized equivalent query
SELECT COUNT(emp_id) FROM employees e;
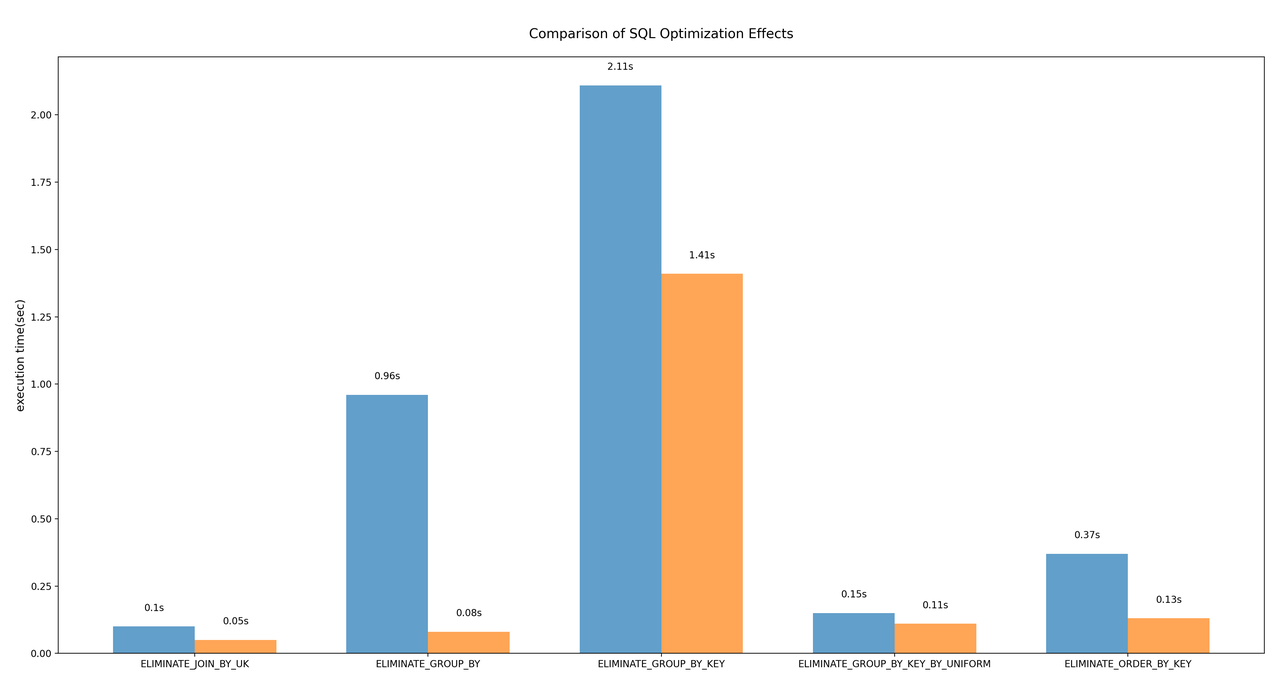
When the ELIMINATE_JOIN_BY_UK optimization is disabled, the execution time is 0.1 seconds. When the ELIMINATE_JOIN_BY_UK optimization is enabled, the execution time is 0.05 seconds, accelerating queries by 100%.
Removing Redundant Group By Based on Uniqueness (ELIMINATE_GROUP_BY)
Scenario: When a unique, non-nullable column exists in the group by key...
Magic: You can simply remove the group by keyword.
--Original query
SELECT COUNT(c2) FROM
(SELECT emp_id c1, sum(salary) c2 from employees GROUP BY emp_id, emp_name) t;
-- Optimized equivalent query
SELECT COUNT(c2) FROM
(SELECT emp_id c1, salary c2 from employees) t;
When ELIMINATE_GROUP_BY optimization is disabled, the execution time is 0.96 seconds. When ELIMINATE_GROUP_BY optimization is enabled, the SQL execution time is 0.08 seconds, accelerating queries by 1100%.
Eliminate Redundant Group By (ELIMINATE_GROUP_BY_KEY)
Scenario: Group By multiple columns with functional dependencies.
Magic: The slots determined by the functional dependency can be eliminated from the group by key.
Example:
--Case 1: Eliminate functional dependencies based on the function provided
-- email -> SUBSTR(email, INSTR(email, 'l')+1))
-- Original query
SELECT count(email) FROM (SELECT email
FROM employees
GROUP BY email, SUBSTR(email, INSTR(email, 'l')+1)) t;
-- Optimized equivalent query
SELECT count(email) FROM (SELECT email
FROM employees
GROUP BY email) t;
--Case 2: Eliminating functional dependencies based on equivalent sets
-- Original query
SELECT COUNT(*)
FROM employees e
INNER JOIN departments d ON e.dept_id = d.dept_id
GROUP BY e.dept_id, d.dept_id;
-- Optimized equivalent query
SELECT COUNT(*)
FROM employees e
INNER JOIN departments d ON e.dept_id = d.dept_id
GROUP BY e.dept_id;
Taking Case 1 as an example, when ELIMINATE_GROUP_BY_KEY optimization is disabled, the execution time is 2.11 seconds. When ELIMINATE_GROUP_BY_KEY optimization is enabled, the SQL execution time is 1.41 seconds, accelerating queries by 50%.
Eliminate Group By Key By Uniform(ELIMINATE_GROUP_BY_KEY_BY_UNIFORM)
Scenario: All values in the GroupBy column are identical...
Magic: Simply remove the GroupBy, since all rows belong to the same group!
Example:
-- Original query
SELECT hire_date, max(salary) FROM employees WHERE hire_date='2025-01-01' GROUP BY dept_id,hire_date;
-- Optimized equivalent query
SELECT '2025-01-01', max(salary) FROM employees WHERE hire_date='2025-01-01' GROUP BY dept_id;
With the ELIMINATE_GROUP_BY_KEY_BY_UNIFORM optimization disabled, the SQL execution time was 0.15 seconds. With the ELIMINATE_GROUP_BY_KEY_BY_UNIFORM optimization enabled, the SQL execution time was 0.11 seconds, accelerating queries by 36%.
Eliminate Order By Key(ELIMINATE_ORDER_BY_KEY)
Scenario: Sorting by a unique key, or when the sort key contains a functional dependency.
Magic: Remove the OrderBy clause, as the data is already "naturally ordered." Remove the key determined by the functional dependency.
Example:
-- Case 1: Simplification of functional dependencies derived from uniqueness
SELECT sum(c1) FROM
(SELECT emp_id c1, emp_name c2
FROM employees
ORDER BY emp_id,emp_name,email,dept_id,salary,hire_date
LIMIT 1000000) t;
-- Optimized equivalent query
SELECT sum(c1) FROM
(SELECT emp_id c1, emp_name c2
FROM employees
ORDER BY emp_id
LIMIT 1000000) t;
-- Case 2: Simplifying functional dependencies derived from expressions
SELECT hire_date, EXTRACT(YEAR FROM hire_date), EXTRACT(MONTH FROM hire_date)
FROM employees
ORDER BY hire_date, EXTRACT(YEAR FROM hire_date), EXTRACT(MONTH FROM hire_date);
-- Optimized equivalent query
SELECT hire_date, EXTRACT(YEAR FROM hire_date), EXTRACT(MONTH FROM hire_date)
FROM employees
ORDER BY hire_date;
-- Case 3: Simplifying multi-column expression function dependencies
SELECT emp_name
FROM employees
ORDER BY emp_name, email, CONCAT(emp_name, ' ', email);
-- Optimized equivalent query
SELECT emp_name
FROM employees
ORDER BY emp_name, email;
-- Case 4: Elimination based on uniformity
SELECT emp_name
FROM employees
WHERE emp_id = 101
ORDER BY emp_id;
--Optimized equivalent query
SELECT emp_name
FROM employees
WHERE emp_id = 101;
Taking Case 1 as an example, when the ELIMINATE_ORDER_BY_KEY optimization is disabled, the SQL execution time is 0.37 seconds. When the ELIMINATE_ORDER_BY_KEY optimization is enabled, the SQL execution time is 0.13 seconds, accelerating queries by 185%.
Optimization Effect Comparison
The following chart compares the optimization effects of the five optimization rules. Blue represents the SQL execution time with the optimization rule disabled, and orange represents the SQL execution time with the optimization rule enabled.
Best Practices
Recommended: Add Explicit UNIQUE Constraints to All Unique Key Columns
Whether a column is a primary key or not, it should be clearly defined through a UNIQUE constraint, as long as it has unique traits (including business unique keys, composite unique keys, and foreign key associated columns).
CREATE TABLE orders (
order_id INT,
order_code VARCHAR(20));
ALTER TABLE orders ADD CONSTRAINT orders_uk UNIQUE (order_id);
Optimization Benefits: Helps the optimizer identify unique traits, enabling optimizations such as Join elimination and Group By simplification.
Recommended: Appropriate Use of NOT NULL Constraints
Add NOT NULL constraints to columns that are not allowed to be nullable for business purposes. Some of the optimization rules mentioned above require slots to be unique and non-null, or uniform and non-null, to be applied. Adding NOT NULL constraints can prevent NULL values from interfering with the optimization.
CREATE TABLE products (
product_id INT NOT NULL,
product_name VARCHAR(100) NOT NULL);
Avoid: Overuse of SELECT *
-- Things to avoid
explain logical plan
SELECT *
FROM employees e
LEFT OUTER JOIN departments d ON e.dept_id = d.dept_id;
-- Recommended writing style
explain logical plan
SELECT e.*
FROM employees e
LEFT OUTER JOIN departments d ON e.dept_id = d.dept_id;
Cause: For example, one of the prerequisites for the optimization rule ELIMINATE_JOIN_BY_UK is that only columns from the left table of the LEFT OUTER JOIN are in the projected columns. Therefore, when you only need data from the left table, using SELECT * prevents the optimizer from applying the optimization rule.
Avoid: Redundant grouping keys and sorting keys
-- Redundant grouping columns (i.e., the user knows that product_id determines product_name, but the database system does not recognize this dependency. In this case, product_name is redundant and can be deleted)
SELECT product_id, product_name
FROM products
GROUP BY product_id, product_name;
By proactively avoiding redundant grouping and sorting keys, you can improve query efficiency, reduce resource consumption, and maintain code simplicity, even if some functional dependencies cannot be automatically identified by the system.
Summary and Outlook
Data Trait empowers the query optimizer with deep data cognition capabilities through four core traits (uniqueness, uniformity, equal sets, functional dependencies):
- Data feature recognition: Accurately captures essential data attributes like primary key uniqueness and constant column uniformity.
- Query semantics understanding: Deciphers underlying data relationships in SQL operations, identifies redundant operations.
- Optimization decision support: Provides a theoretical basis for query rewriting, plan selection, and other optimizations
The design of Data Trait adopts a highly modular architecture, reserving ample space for future expansion. Particularly for the Uniform trait, we plan to introduce more precise value distribution description capabilities. While the current Uniform mainly records completely uniform (single-value) cases, we will expand it to record limited discrete values in the future. For example, when queries contain IN predicate filters like WHERE status IN ('active','pending'), the optimizer can precisely determine that the status column has only 2 possible values in this query context. This enhanced Uniform trait will support decision-making for the optimizer more powerfully.


