TL;DR:
SF Technology migrated its primary BI analytics platform from Presto to Apache Doris, supporting over 1 million daily queries. This strategic move solved critical issues with query speed, stability, and high costs. The results:
- P95 query latency is reduced by nearly 70%.
- Hardware resources saved by 48%.
- Successfully migrated 100% of Ad-hoc and BI workloads.
- The proportion of queries taking longer than 50s dropped from 8% to just 1.5%.
The Challenge: A High-Cost, Unstable Presto Architecture
SF Technology operates a self-developed BI analytics platform, a vital tool for visualizing data across all segments of their operations—from collection and transit to final delivery. With a massive user base and huge data volumes, the platform demands high speed and stability.
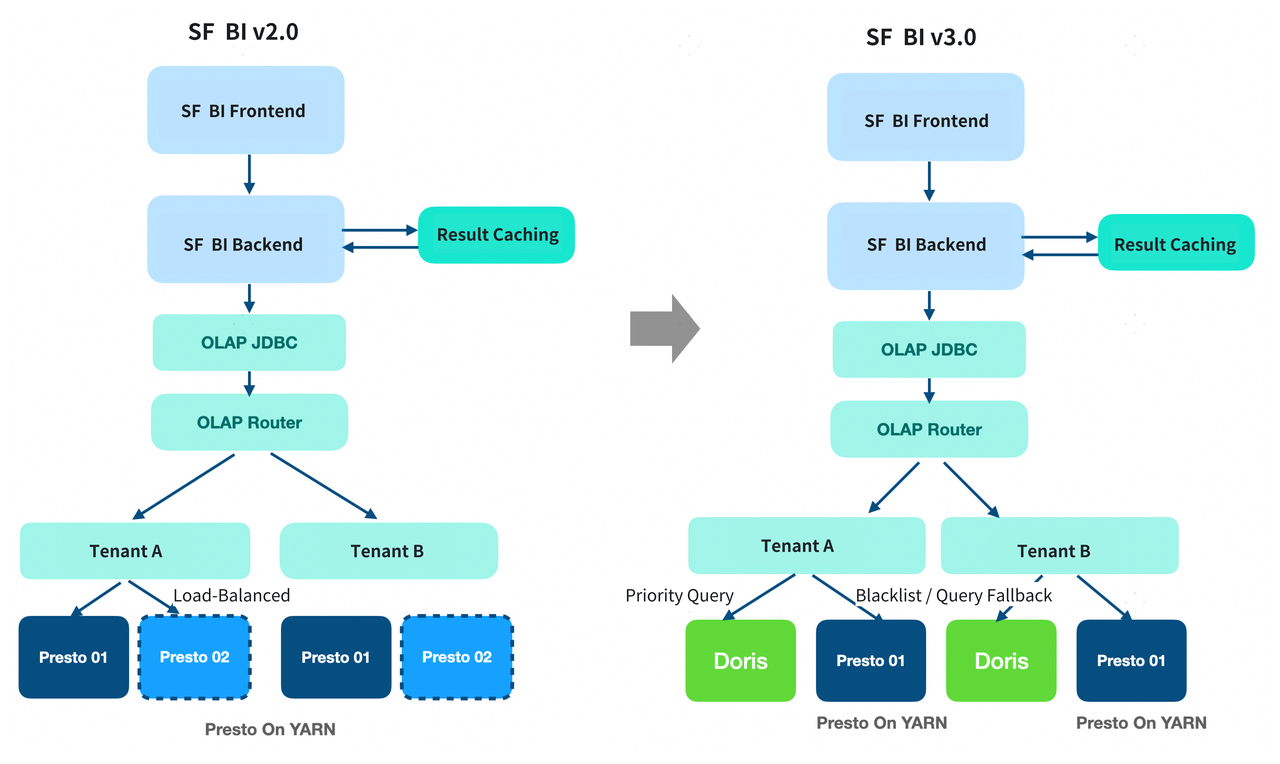
Their initial architecture, built on Presto on YARN, was buckling under the pressure. Despite its ability to auto-scale, it faced several significant challenges:
- Slow Queries: Presto’s query optimizer struggled with the platform's diverse and complex query patterns, leading to slow performance that couldn't meet business requirements.
- Poor Stability: Lacking a built-in cache, Presto was highly susceptible to HDFS I/O jitter, which caused unpredictable query latency. Adding external caching components only increased system complexity.
- High Resource Costs: The Presto cluster ran at a massive scale (tens of thousands of cores), consuming enormous computational resources and driving up hardware costs.
- Limited Scope: As a query engine without native storage, Presto was confined to analyzing data in Hive, making it difficult to support real-time or semi-structured data analytics use cases.
The Search for a Solution: Why Apache Doris?
In early 2024, the SF Technology team began searching for a next-generation analytics engine. They needed a single, high-performance tool that was versatile enough to handle all their data analysis needs. Apache Doris quickly emerged as the top contender due to its clear advantages in performance and cost-efficiency.
- Superior Query Optimization: Doris’s advanced Cost-Based Optimizer (CBO) excels at optimizing complex queries, especially multi-table joins. Its materialized view capabilities also offer flexible data acceleration.
- Enhanced Stability: Built-in metadata and data caching effectively shield queries from underlying storage fluctuations (like HDFS jitter), ensuring stable performance without added system complexity.
- Unified Lakehouse Analytics: Doris can serve as both a high-performance data warehouse and a powerful query engine for data lakes (Hive, Iceberg, Paimon). This unified capability supports diverse scenarios like log analytics and real-time reporting within a single engine.
- Resource Efficiency & Isolation: Features like compute nodes and workload groups provide the physical and thread-level resource isolation needed for their multi-tenant, elastically scaled environment.
The Results: A Seamless Migration with Transformative Gains
SF Technology has now successfully migrated 100% of its ad-hoc and BI platform query workloads from Presto to Apache Doris, handling over 1 million queries daily. The migration was meticulously planned to be seamless, with zero disruption to business users.
The project's success was built on a foundation of deep optimization and compatibility work:
- Massive Performance Boost:
- 3x Faster Queries: P95 query latency dropped to under 20 seconds, a nearly 3x improvement.
- 88% of queries now finish in under 10 seconds, up from 72% with Presto.
- The percentage of long-running queries (>50s) was drastically reduced from 8% to just 1.5%.
- 48% Hardware Cost Savings: The migration allowed them to slash their compute footprint from tens of thousands of Presto cores to just a few thousand Doris cores, saving 48% on hardware resources.
- Seamless Migration with a Powerful SQL Dialect Converter: To ensure a smooth transition, Doris’s SQL Convertor was enhanced to automatically handle differences in syntax, functions, and output formats between Presto and Doris. This achieved a 97% SQL compatibility rate, minimizing the need for manual rewrites.
- Optimized Data Access on the Lake: Performance for Parquet and ORC files was significantly improved through optimizations like late materialization for complex types and intelligent merging of small I/O operations and tiny ORC stripes.
- Intelligent Query Scheduling for Mixed Workloads: Doris’s scheduler was optimized for lakehouse queries. It dynamically prioritizes jobs to prevent large queries from blocking smaller ones, asynchronously fetches file lists to speed up queries on tables with massive partitions, and pushes down LIMIT clauses to rapidly terminate data scans.
- Effective Caching Strategy: Doris’s built-in data cache achieved an impressive 96% hit rate, dramatically improving performance and reducing the load on HDFS and the Hive Metastore.
Building on this success, SF Technology is now containerizing Doris to offer it as an internal cloud product. Their future plans include decommissioning Presto entirely, using Doris to replace Elasticsearch for log analytics, and exploring Doris 3.0’s disaggregated storage and compute architecture to further enhance elasticity and reduce costs.
Talk to Us
If you want to bring similar (or even higher) performance improvements and benefits to your data platform, or just explore further on Apache Doris, you are more than welcome to join the Apache Doris community, where you can connect with other users facing similar challenges and get access to professional technical advice and support.
If you're exploring fully-managed, cloud-native options, you can reach out to the VeloDB team!