Introduction: The Lakehouse is a data management paradigm that combines the advantages of data lakes and data warehouses. Apache Doris advances this concept with its core philosophies of "Boundless Data, Seamless Lakehouse." Our previous article The data lakehouse evolution: why Apache Doris is leading the way provided a comprehensive overview of the Apache Doris Lakehouse solution. This article takes a deeper dive into its typical application scenarios to help readers better understand and apply its capabilities.
In an era of data-driven decision-making, the lakehouse architecture, with its unified storage, computation, and management, addresses the shortcomings of traditional data warehouses and data lakes, gradually becoming the new standard for enterprise big data solutions.
In our previous article, we covered the evolution of the lakehouse and introduced the complete Apache Doris Lakehouse solution. This article goes a step further, focusing on three key application scenarios: Accelerating Lakehouse Analytics, Multi-Source Federated Analytics, and Lakehouse Data Processing and Transformation.
Through these practical scenarios, we will demonstrate how Apache Doris helps enterprises respond quickly to business needs and improve data processing and analytical efficiency. We will also provide detailed usage guides tied to real-world examples to help you better understand and apply the Apache Doris Lakehouse solution.
Scenario 1: Accelerating Lakehouse Analytics
In this scenario, Apache Doris acts as the lakehouse query engine to accelerate queries on data stored in the data lake.
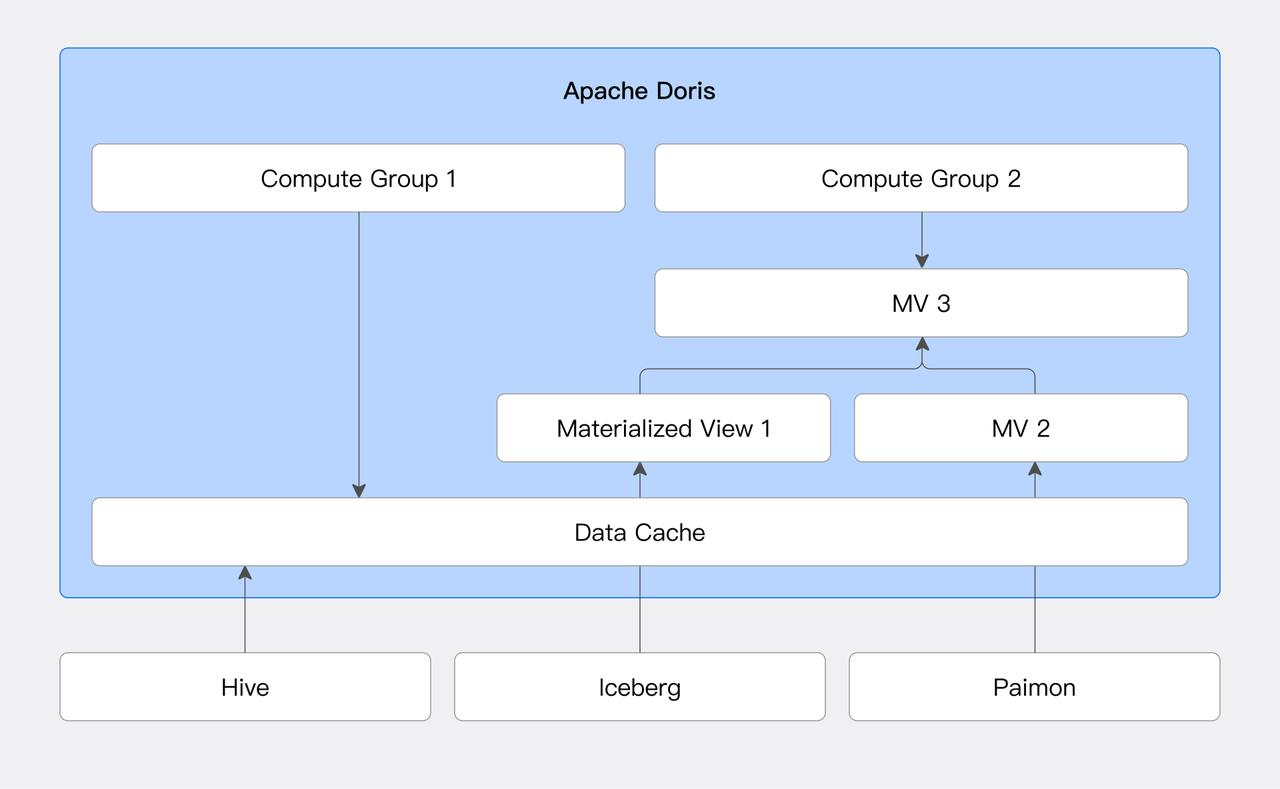
01 Caching for Acceleration
For data lake systems like Hive and Iceberg, users can configure a local disk cache in Doris. This cache automatically stores data files involved in a query in a local directory and manages cache eviction using an LRU (Least Recently Used) policy.
- Configure the cache directory in the BE node's
be.conffile and restart the BE:
enable_file_cache=true;
file_cache_path=[{"path": "/path/to/file_cache", "total_size":53687091200,"query_limit": 10737418240}]
- Enable the cache feature and run a query:
SET enable_file_cache=true;
SELECT * FROM hive.tpcds1000.store_sales WHERE ss_sold_date_sk=2451676;
- If the cache is hit, you will see corresponding metrics in the query's Profile:
- FileCache: 0ns
- BytesScannedFromCache: 2.02 GB
- BytesScannedFromRemote: 0.00
- BytesWriteIntoCache: 0.00
- LocalIOUseTimer: 2s723ms
- NumLocalIOTotal: 444
- NumRemoteIOTotal: 0
- NumSkipCacheIOTotal: 0
- RemoteIOUseTimer: 0ns
- WriteCacheIOUseTimer: 0ns
Tip: It is recommended to use high-speed storage media like SSDs for the cache to achieve the best performance for hot data queries.
02 Materialized Views and Transparent SQL Rewriting
Doris supports creating materialized views based on external data sources. A materialized view pre-computes and stores the results of its defining SQL query in Doris's native internal table format. Furthermore, Doris's query optimizer supports a transparent SQL rewriting algorithm based on the SPJG (SELECT-PROJECT-JOIN-GROUP-BY) pattern. This algorithm analyzes the structure of an incoming query, automatically finds a suitable materialized view, and rewrites the query to use the optimal view.
This feature significantly improves query performance by reducing runtime computation. It also allows applications to benefit from accelerated queries without any changes to the original SQL.
Here is an example using Iceberg Catalog with the TPC-H dataset:
- Create an Iceberg Catalog:
CREATE CATALOG iceberg PROPERTIES (
'type' = 'iceberg',
'iceberg.catalog.type' = 'rest',
'uri' = 'http://172.21.0.1:8181'
);
- Create a materialized view based on the Hive Catalog:
-- Materialized views must be created in an internal catalog. Switch to the internal catalog.
SWITCH internal;
CREATE DATABASE iceberg_mv_db;
USE iceberg_mv_db;
CREATE MATERIALIZED VIEW external_iceberg_mv
BUILD IMMEDIATE REFRESH AUTO ON MANUAL
DISTRIBUTED BY RANDOM BUCKETS 12
PROPERTIES ('replication_num' = '1')
ASSELECT
n_name,
o_orderdate,
sum(l_extendedprice * (1 - l_discount)) AS revenue
FROM
iceberg.tpch1000.customer,
iceberg.tpch1000.orders,
iceberg.tpch1000.lineitem,
iceberg.tpch1000.supplier,
iceberg.tpch1000.nation,
iceberg.tpch1000.region
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'GROUP BY
n_name,
o_orderdate;
- Run the following query. It will be automatically rewritten to use the materialized view for acceleration.
USE iceberg.tpch1000;
SELECT
n_name,
sum(l_extendedprice * (1 - l_discount)) AS revenue
FROM
customer,
orders,
lineitem,
supplier,
nation,
region
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'AND o_orderdate >= DATE '1994-01-01'AND o_orderdate < DATE '1994-01-01' + INTERVAL '1' YEARGROUP BY
n_name
ORDER BY
revenue DESC;
The table below shows the performance difference before and after hitting the materialized view. With transparent rewriting, the query speed improved by approximately 93x.

Scenario 2: Multi-Source Federated Analytics
Apache Doris can act as a unified SQL query engine, connecting to various data sources for federated analysis to break down data silos and unlock data value.
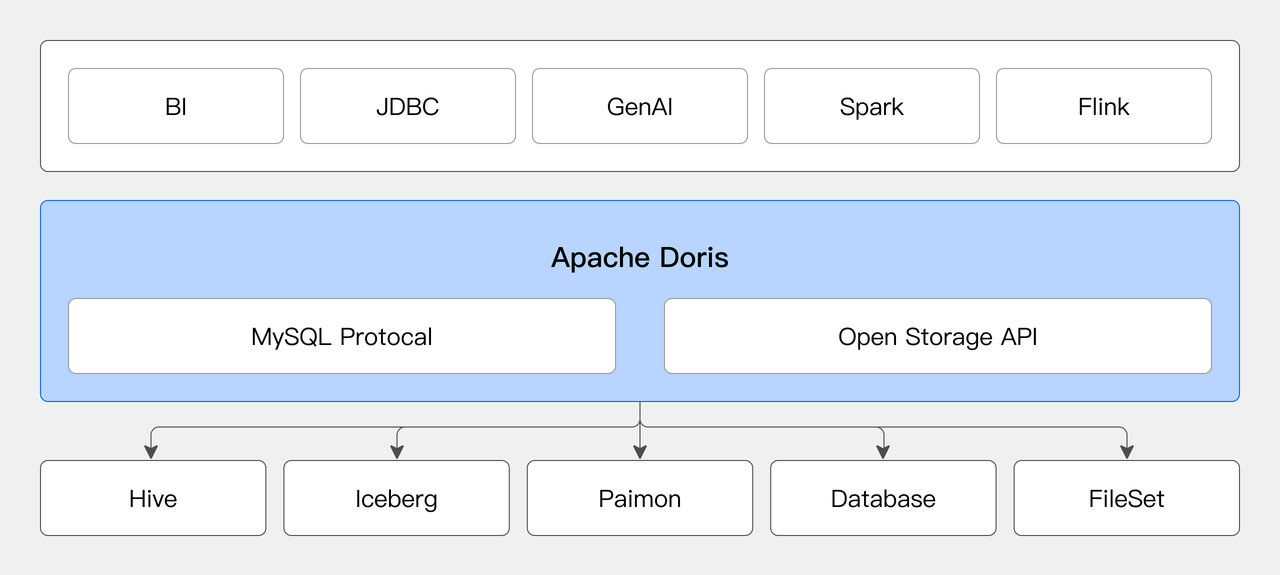
01 Flexibly Connecting to Data Sources
You can dynamically create multiple Catalogs in Doris to connect to different data sources:
-- Create a Hive Catalog
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.0.0.1:9083'
);
-- Create an Iceberg Catalog
CREATE CATALOG iceberg PROPERTIES (
'type'='iceberg',
'iceberg.catalog.type' = 'hadoop',
'warehouse' = 'hdfs://hdfs_host:8020/user/iceberg/'
);
-- Create a MySQL Catalog
CREATE CATALOG mysql PROPERTIES (
"type"="jdbc",
"user"="root",
"password"="pwd",
"jdbc_url" = "jdbc:mysql://example.net:3306",
"driver_url" = "mysql-connector-j-8.3.0.jar",
"driver_class" = "com.mysql.cj.jdbc.Driver"
);
Switch between different Catalogs to view their database and table structures:
-- Switch to the Hive Catalog
SWITCH hive;
-- Show databases
SHOW DATABASES;
+-----------+
| Database |
+-----------+
| tpch1000 |
| tpcds1000 |
+-----------+
-- Describe a table
DESC tpch1000_oss.lineitem;
+-----------------+--------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+--------+------+------+---------+-------+
| l_orderkey | bigint | Yes | true | NULL | |
| l_partkey | bigint | Yes | true | NULL | |
| l_suppkey | bigint | Yes | true | NULL | |
| l_linenumber | int | Yes | true | NULL | |
| l_quantity | double | Yes | true | NULL | |
| l_extendedprice | double | Yes | true | NULL | |
| l_discount | double | Yes | true | NULL | |
| l_tax | double | Yes | true | NULL | |
| l_returnflag | text | Yes | true | NULL | |
| l_linestatus | text | Yes | true | NULL | |
| l_shipdate | date | Yes | true | NULL | |
| l_commitdate | date | Yes | true | NULL | |
| l_receiptdate | date | Yes | true | NULL | |
| l_shipinstruct | text | Yes | true | NULL | |
| l_shipmode | text | Yes | true | NULL | |
| l_comment | text | Yes | true | NULL | |
+-----------------+--------+------+------+---------+-------+
02 Cross-Source Join Queries
Users can write a single SQL statement to perform arbitrary joins across data from different sources:
SELECT
n_name,
SUM(l_extendedprice * (1 - l_discount)) AS revenue
FROM
hive.tpch1000.customer,
hive.tpch1000.orders,
iceberg.tpch1000.lineitem,
iceberg.tpch1000.supplier,
mysql.tpch1000.nation,
mysql.tpch1000.region
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'AND o_orderdate >= DATE '1994-01-01'AND o_orderdate < DATE '1994-01-01' + INTERVAL '1' YEARGROUP BY
n_name
ORDER BY
revenue DESC;
Scenario 3: Lakehouse Data Processing and Transformation
In this scenario, Apache Doris acts as a data processing engine to transform data within the data lake.
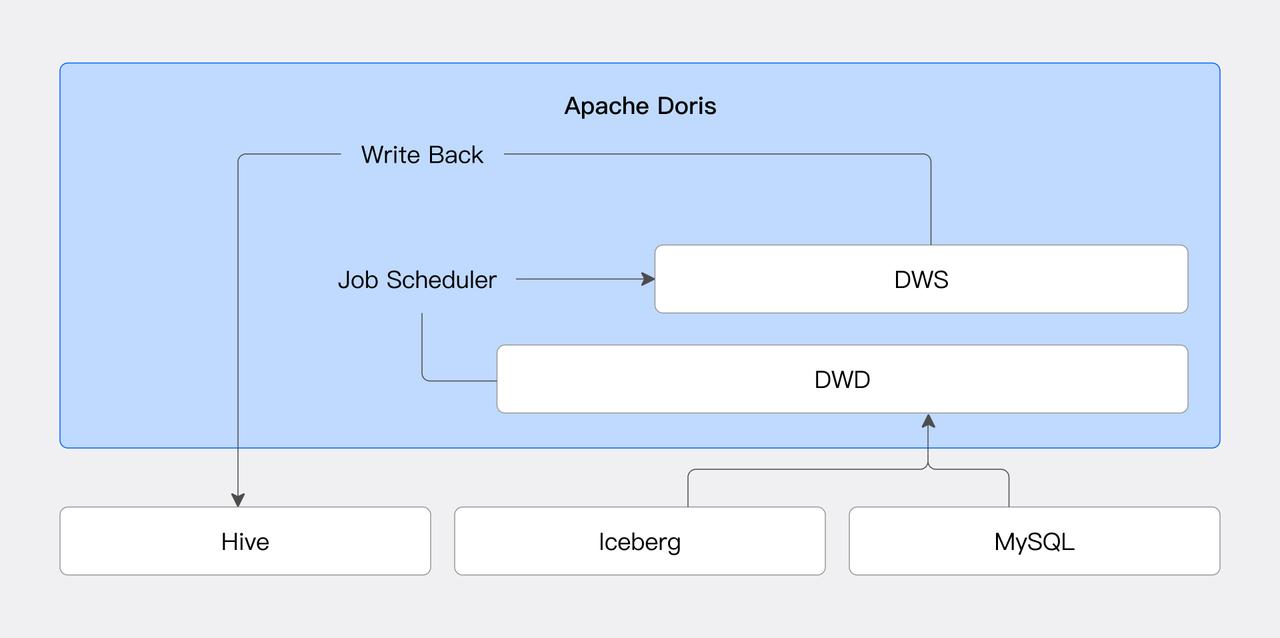
01 Scheduled Task Execution
As data management becomes more sophisticated, scheduled tasks play a crucial role. Common use cases include:
- Periodic Data Updates: Automating periodic data ingestion and ETL operations reduces manual intervention and improves efficiency and accuracy.
- Data Synchronization: Using Catalogs, you can schedule regular synchronization from external sources to ensure that multi-source data is accurately and efficiently integrated.
- Data Maintenance: Regularly cleaning up expired or invalid data frees up storage space and prevents performance degradation.
Doris's built-in Job Scheduler provides efficient and flexible task scheduling, reducing dependency on external systems and lowering operational costs and failure risks. Combined with data source connectors, users can schedule periodic processing of external data into Doris.
Here is a basic example of periodically synchronizing data from MySQL to Doris.
- First, create a table in Doris:
CREATE TABLE IF NOT EXISTS user_activity (
`user_id` LARGEINT NOT NULL,
`date` DATE NOT NULL,
`city` VARCHAR(20),
`age` SMALLINT,
`sex` TINYINT,
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00",
`cost` BIGINT SUM DEFAULT "0",
`max_dwell_time` INT MAX DEFAULT "0",
`min_dwell_time` INT MIN DEFAULT "99999"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES ( "replication_allocation" = "tag.location.default: 1" );
- Create a Catalog for the MySQL data source:
CREATE CATALOG activity PROPERTIES (
"type"="jdbc",
"user"="root",
"jdbc_url" = "jdbc:mysql://127.0.0.1:9734/user?useSSL=false",
"driver_url" = "mysql-connector-java-5.1.49.jar",
"driver_class" = "com.mysql.jdbc.Driver"
);
- Schedule a one-time full data import to trigger at a specific time:
CREATE JOB one_time_load_job
ON SCHEDULE
AT '2024-12-10 03:00:00'
DO
INSERT INTO user_activity FROM SELECT * FROM activity.user.activity;
- Schedule a daily job to synchronize incremental data:
CREATE JOB schedule_load
ON SCHEDULE EVERY 1 DAY
DO
INSERT INTO user_activity FROM SELECT * FROM activity.user.activity
WHERE create_time >= days_add(now(), -1);
02 Layered Modeling in Data Warehousing
Enterprises often use a data lake to store raw data and then process it in layers (e.g., DWD, DWS), exposing different layers to different business units. Doris's materialized view feature supports creating views on external sources and even creating views on top of other views. This simplifies the complexity of data modeling and improves processing efficiency.
Here’s how to use materialized views for data layering with the TPC-H dataset from a Hive source.
- First, create the Hive Catalog (if not already created):
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.0.0.1:9083'
);
- Build the DWD (Data Warehouse Detail) layer by creating a detailed wide table for orders:
CREATE MATERIALIZED VIEW dwd_order_detail
BUILD IMMEDIATE REFRESH AUTO ON COMMIT
DISTRIBUTED BY RANDOM BUCKETS 16
PROPERTIES ('replication_num' = '1')
AS
select
o.o_orderkey,
o.o_custkey,
o.o_orderstatus,
o.o_totalprice,
o.o_orderdate,
c.c_name,
c.c_nationkey,
n.n_name as nation_name,
r.r_name as region_name,
l.l_partkey,
l.l_quantity,
l.l_extendedprice,
l.l_discount,
l.l_tax
from hive.tpch.orders o
join hive.tpch.customer c on o.o_custkey = c.c_custkey
join hive.tpch.nation n on c.c_nationkey = n.n_nationkey
join hive.tpch.region r on n.n_regionkey = r.r_regionkey
join hive.tpch.lineitem l on o.o_orderkey = l.l_orderkey;
- Based on the DWD layer, build the DWS ( Data Warehouse Summary) layer for daily sales aggregation:
CREATE MATERIALIZED VIEW dws_daily_sales
BUILD IMMEDIATE REFRESH AUTO ON COMMIT
DISTRIBUTED BY RANDOM BUCKETS 16
PROPERTIES ('replication_num' = '1')
ASSELECT
date_trunc(o_orderdate, 'month') AS month,
nation_name,
region_name,
bitmap_union(to_bitmap(o_orderkey)) AS order_count,
sum(l_extendedprice * (1 - l_discount)) AS net_revenue
FROM dwd_order_detail
GROUP BY
date_trunc(o_orderdate, 'month'),
nation_name,
region_name;
- Users can now query the aggregated data in the DWS layer for fast analytics:
SELECT
nation_name,
month,
bitmap_union_count(order_count) AS num_orders,
sum(net_revenue) AS revenue
FROM dws_daily_sales
GROUP BY nation_name, month;
03 Managed Iceberg / Hive Table
Users can directly manage Iceberg and Hive table through Doris. In addition to querying, Doris supports creating, deleting, and writing to Iceberg and Hive tables. With this capability, users can fully manage tables within Doris without relying on external systems. This is currently supported for JDBC, Hive, and Iceberg catalogs, with more sources planned.
Here is a simple example of writing data back to Iceberg.
- First, create an Iceberg Catalog:
CREATE CATALOG iceberg PROPERTIES (
"type" = "iceberg",
"iceberg.catalog.type" = "hms",
"hive.metastore.uris" = "thrift://172.21.16.47:7004",
"warehouse" = "hdfs://172.21.16.47:4007/user/hive/warehouse/",
"fs.defaultFS" = "hdfs://172.21.16.47:4007"
);
- Create a database and table in Iceberg using Doris:
SWITCH iceberg;
CREATE DATABASE ice_db;
CREATE TABLE ice_tbl (
`ts` DATETIME,
`col1` INT,
`col2` DECIMAL(9,4),
`col3` STRING,
`pt1` STRING,
`pt2` STRING
) ENGINE=iceberg
PARTITION BY LIST (DAY(ts), pt1, pt2) ()
PROPERTIES (
'write-format'='orc',
'compression-codec'='zlib'
);
- Process data from an internal table and insert it into the Iceberg table:
INSERT INTO iceberg.ice_db.ice_tbl
SELECT * FROM
internal.db.fact_tbl f JOIN internal.db.dim_tbl d
ON f.id = d.id
AND f.dt > "2024-12-10";
Conclusion
This concludes our look at typical application scenarios for the Apache Doris Lakehouse. As these two articles have shown, Apache Doris—with its ability to integrate heterogeneous data sources, its high-performance processing, modern architecture, rich data management capabilities, and openess—perfectly embodies the philosophy of "Boundless Data, Seamless Lakehouse." It provides enterprises with a low-cost, highly elastic, and strongly consistent next-generation data foundation.
We invite you to try Apache Doris and look forward to your feedback and suggestions! In the future, Apache Doris will continue to enhance its lakehouse capabilities, empowering enterprises to break through data boundaries.
If you are interested in building with the Apache Doris Lakehouse, please join the Apache Doris Slack community to engage in discussions.