Data lakehouses are everywhere in today’s conversations about modern data architecture. But before we get swept up in the buzz, it’s worth stepping back to understand how the industry got here — and what we truly need from a lakehouse. Then I’ll introduce Apache Doris as a next-generation lakehouse solution and show how it delivers on those expectations.
The evolution towards lakehouse
01 Traditional data warehouse
In the early days of enterprise digital transformation, the growing complexity of business data gave rise to traditional data warehouses. These systems were designed to empower business intelligence (BI) by consolidating structured data from diverse sources through ETL pipelines.
With features like well-defined schemas, columnar storage, and tightly coupled compute-storage architecture, data warehouses enabled fast, reliable analysis and reporting using standard SQL. They also ensured data consistency through centralized management and strict transactional controls.
However, as the digital landscape expanded—driven by the rise of the internet, IoT, and an explosion of unstructured data formats like logs, images, and documents—traditional warehouses struggled to scale efficiently or support flexible, exploratory analytics.
This gap sparked the emergence of data lakes, offering a more cost-effective, schema-flexible approach better suited for big data and machine learning workloads.
02 Data lake
Google’s pioneering contributions to big data—Google File System (GFS), MapReduce, and BigTable—ignited a global wave of innovation and laid the foundation for the Hadoop ecosystem. Hadoop revolutionized large-scale data processing by enabling cost-efficient computation on commodity hardware. Data lakes, built on this foundation, became instrumental for handling complex and massive datasets across a variety of use cases:
- Massive-scale data processing: By leveraging distributed storage and parallel computing, data lakes support high-throughput processing on standard computing nodes, eliminating the need for expensive proprietary hardware.
- Multi-modal data support & low-cost storage: Unlike traditional data warehouses, data lakes store raw, unstructured, or semi-structured data without rigid schema definitions. With a schema-on-read approach, structure is applied at query time, preserving the full value of diverse data types such as images, videos, logs, and more. Object storage further reduces costs while enabling massive scalability.
- Multi-modal computing: A single dataset in a data lake can be accessed by various engines for different tasks—SQL querying, machine learning, AI model training—delivering a highly flexible and unified analytics environment.
The term "data lake" vividly captures the essence: vast pools of raw data stored in a unified layer, ready for various downstream processing. As the architecture evolved, a three-tier design emerged, paving the way for lakehouse-style analytics:
- Storage layer: It is backed by distributed file systems or cloud object storage services like HDFS, AWS S3, and Azure Blob. These platforms offer near-infinite scalability, high availability, and cost-efficiency. Data is retained in its original form to provide flexibility for various analytical use cases.
- Compute layer: Data stored in lakes can be accessed by multiple compute engines based on workload needs. Hive enables batch ETL via HiveQL, Spark handles batch, streaming, and ML tasks, while Presto excels at interactive, ad-hoc querying.
- Metadata layer: Services like Hive Metastore manage schema definitions, partitions, and data locations to provide a shared metadata foundation across engines. This layer is crucial for consistent interpretation, collaboration, and discoverability of data within the lake.
03 New challenges in modern data processing
Over the years, both data warehouses and data lakes have evolved to serve vital roles in enterprise data architecture.
However, as modern businesses demand real-time insights, greater flexibility, and open ecosystem integration, both architectures are facing growing limitations. Here’s a snapshot of the key challenges confronting each:
For traditional data warehouses:
- Lack of real-time capabilities: In high-stakes scenarios like flash sales or real-time monitoring, businesses expect sub-second analytics. Traditional warehouses rely on static ETL processes and struggle to handle continuously changing data, making real-time decision-making difficult. For instance, tracking dynamic shipment routes in logistics is a challenge without true real-time data handling.
- Inflexibility with semi-structured and unstructured data: With the rise of data from social media, medical imaging, and IoT, rigid schema management in warehouses leads to inefficiencies in storage, indexing, and querying. Handling massive volumes of clinical text and images in healthcare research is one such area where traditional warehouses fall short.
For data lakes:
- Performance bottlenecks: While great for batch processing, engines like Spark and Hive lag behind in interactive, low-latency analytics. Business users and analysts often face sluggish query response times, which can hinder timely decision-making in areas like real-time fraud detection or financial risk assessment.
- Lack of transactional integrity: To maximize flexibility and scalability, data lakes often sacrifice transactional guarantees. This tradeoff can lead to data inconsistency or even loss during complex data operations, posing risks for accuracy-critical applications.
- Data governance pitfalls: Open-write access in data lakes can lead to data quality issues and inconsistency. Without robust governance, the "data lake" can quickly become a "data swamp", making it difficult to extract reliable insights, especially when integrating diverse data sources with inconsistent formats or semantics.
To meet the needs of both real-time analytics and flexible data processing, many organizations maintain both data warehouses and data lakes. However, this dual-system approach introduces its own challenges: data duplication, redundant pipelines, fragmented user experiences, and data silos. As a result, the industry is shifting toward a unified solution: merging the strengths of warehouses and lakes into a unified lakehouse architecture.
04 Data lakehouse
The lakehouse architecture unifies storage, computation, and metadata into a single cohesive platform—reducing redundancy, lowering costs, and ensuring data freshness. Over time, this architecture has crystallized into a multi-layered paradigm:
- Storage layer: the solid foundation Building on the distributed storage capabilities pioneered by data lakes, lakehouses typically rely on HDFS or cloud object stores (e.g., AWS S3, Azure Blob, GCS). Data is stored in raw or open columnar formats like Parquet and ORC, which offer high compression and efficient columnar access. This setup drastically reduces I/O overhead and provides a performant backbone for downstream data processing.
- Open data formats: interoperability In addition to open file formats, like Parquet and ORC, which ensure interoperability across diverse compute engines, lakehouse systems also embrace open table formats like Apache Iceberg, Hudi, and Delta Lake, enabling features such as near real-time updates, ACID transactions, time travel, and snapshot isolation. These formats ensure seamless compatibility across SQL engines and unify the flexibility of data lakes with the transactional guarantees of traditional warehouses, so the same dataset can be available for both real-time processing and historical analytics.
- Computation layer: diverse engines, unified power The computation layer combines various engines to leverage their respective strengths. Spark powers large-scale batch jobs and machine learning with its rich APIs. Flink handles real-time stream processing. Presto and Apache Doris excel at ultra-fast, interactive queries. By leveraging a shared storage layer and integrated resource management, these engines can collaboratively execute complex workflows, serving use cases from real-time dashboards to in-depth analytics.
- Metadata layer: the intelligent control plane Evolving from tools like Hive Metastore to modern systems such as Unity Catalog and Apache Gravitino, metadata management in lakehouses provides a unified namespace and centralized data catalog across multi-cloud and multi-cluster environments. This allows users to easily discover, govern, and interact with data, regardless of where it resides or which engine is querying it. Enhanced features like access control, audit logging, and lineage tracking ensure enterprise-grade data governance.
In essence, the lakehouse unites the best of both worlds—retaining the cost-efficiency and scalability of lakes while integrating the performance and reliability of warehouses. By standardizing data formats, centralizing metadata, and supporting hybrid processing (real-time + batch), it’s quickly becoming the gold standard for modern big data architectures.
Apache Doris: the lakehouse solution
To respond to the trend and provide better analytics services, Apache Doris has extensively enhanced its data lakehousing capabilities since version 2.1.
As enterprises push forward with building a lakehouse architecture, they often face complex challenges—from selecting new systems and integrating legacy platforms to managing data format conversions, adapting to new APIs, ensuring seamless system transitions, and coordinating teams across departments for permissions and compliance. To help companies navigate this complexity, Apache Doris introduces two core concepts: "Boundless Data" and "Boundless Lakehouse". These ideas aim to accelerate the lakehouse transformation while minimizing risks and costs.
01 Boundless Data
Boundless Data focuses on breaking down data silos. Apache Doris offers unified query acceleration and simplifies system architecture.
Easy data access
Apache Doris supports a wide range of data systems and formats through its flexible extensible connector framework, enabling users to run cross-platform SQL analytics without overhauling their existing data infrastructure.

-
Apache Doris offers powerful data source connectors that make it easy to connect to and efficiently extract data from a wide range of systems—whether it's Hive, Iceberg, Hudi, Paimon, or any database that supports the JDBC protocol. For lakehouse systems, Doris can seamlessly retrieve table schemas and distribution information from the underlying metadata services, enabling smart query planning. Thanks to its MPP (Massively Parallel Processing) architecture, Doris can scan and process distributed data at scale with high performance. Below is a list of the supported data sources along with their corresponding metadata and storage systems.

-
Apache Doris features an extensible connector framework that makes it easy for developers to integrate custom enterprise data sources and achieve seamless data interoperability:
- Doris defines a standardized three-level structure—Catalog, Database, and Table, so developers can easily map to the appropriate layers of their target data systems. Doris also provides standard interfaces for metadata services and data access, allowing developers to integrate new data sources simply by implementing the defined APIs.
- Additionally, Doris is compatible with Trino connectors, enabling teams to directly deploy Trino plugin packages into a Doris cluster with minimal configuration. Doris already supports integrations with sources like Kudu, BigQuery, Delta Lake, Kafka, and Redis.
-
Beyond integration, Doris also enables convenient cross-source data processing. It allows users to create multiple connectors at runtime, so they can perform federated queries across different data sources using standard SQL. For example, users can easily join a fact table from Hive with a dimension table from MySQL:
SELECT h.id, m.name
FROM hive.db.hive_table h JOIN mysql.db.mysql_table m
ON h.id = m.id;
Combined with Doris’ built-in job scheduling capabilities, users can automate such queries. For example, they can set it as an hourly job and write the query results into an Iceberg table:
CREATE JOB schedule_load
ON SCHEDULE EVERY 1 HOUR DO
INSERT INTO iceberg.db.ice_table
SELECT h.id, m.name
FROM hive.db.hive_table h JOIN mysql.db.mysql_table m
ON h.id = m.id;
High-performance data processing
High-performance data analytics is a fundamental driver behind the transition from data lakes to unified lakehouse architectures. Apache Doris has extensively optimized data processing and offers a rich set of query acceleration features:
- Execution engine: Doris is built on an MPP (Massively Parallel Processing) framework combined with a pipeline-based execution model. This design enables it to process massive datasets quickly in a multi-machine, multi-core distributed environment. With fully vectorized operators, Doris delivers leading performance on industry-standard benchmarks like TPC-DS.
- Query optimizer: Doris features an intelligent query optimizer that automatically handles complex SQL requests. It deeply optimizes operations such as multi-table joins, aggregations, sorting, and pagination. Specifically, it uses advanced cost models and relational algebra transformations to generate highly efficient execution plans, making SQL writing much simpler for users while boosting performance.
- Caching and I/O optimization: Accessing external data sources often involves high-latency, unstable network communication. Doris addresses this with a comprehensive caching system. It has optimized cache types, freshness, and strategies to maximize the use of memory and local high-speed disks. It also fine-tunes network I/O to deal with high throughput, low IOPS, and high latency, offering near-local performance even when accessing remote data sources.
- Materialized views and transparent acceleration: Doris supports flexible refresh strategies for materialized view, including full refresh and partition-based incremental refresh, in order to reduce maintenance costs and improving data freshness. In addition to manual refresh, it also supports scheduled and data-triggered refreshes for greater automation. Transparent acceleration is when the query optimizer can automatically route queries to the best available materialized view. Featuring columnar storage, efficient compression, and intelligent indexing, the materialized views of Doris can greatly improve query efficiency and can even replace traditional caching layers.
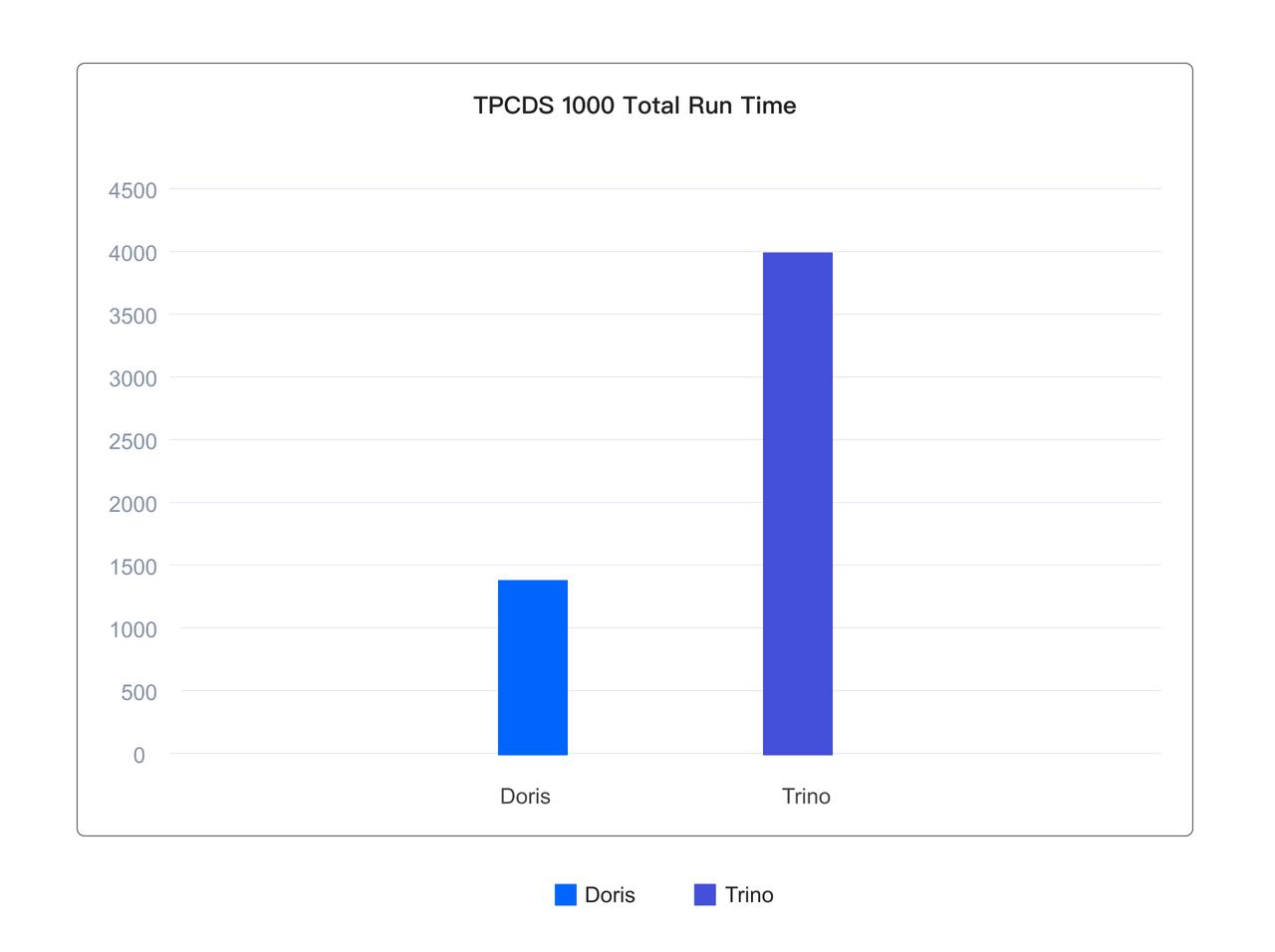
As a result, in benchmark tests on a 1TB TPC-DS dataset using the Iceberg table format, Apache Doris completed 99 queries in just one-third of the total time taken by Trino.
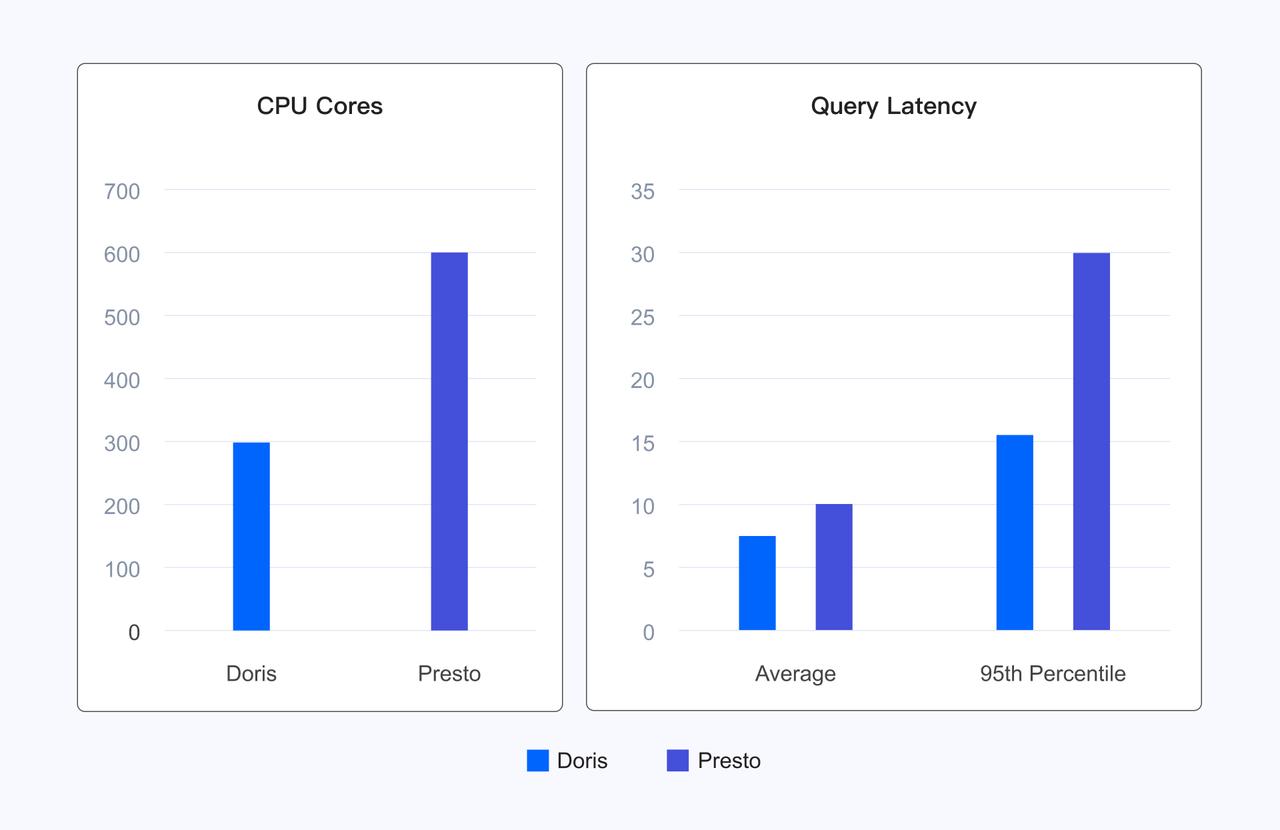
In real-world user scenarios, Apache Doris delivers performance gains over Presto while using only half the computing resources. On average, Doris reduces query latency by 20%, and achieves a 50% reduction in 95th percentile latency.
Seamless migration
When integrating multiple data sources into a unified lakehouse, migrating SQL queries is often one of the biggest hurdles. Different SQL dialects across systems can create major compatibility challenges, leading to costly and time-consuming rewrites.
To simplify this process, Apache Doris offers a SQL Converter. It allows users to directly query data using SQL dialects from other engines because it automatically translates queries into Doris SQL (standard SQL). Currently, Doris supports SQL dialects from Presto/Trino, Hive, PostgreSQL, and ClickHouse, achieving over 99% compatibility in some production environments.
02 Boundless Lakehouse
Beyond query migration, Doris also addresses the need for architectural streamlining.
Modern deployment architecture
Since version 3.0, Doris has supported a cloud-native, compute-storage decoupled architecture. This modern deployment model maximizes resource efficiency because it enables independent scaling of compute and storage resources. This is important for enterprises because it provides flexible resource mangement for large-scale analytics workloads.
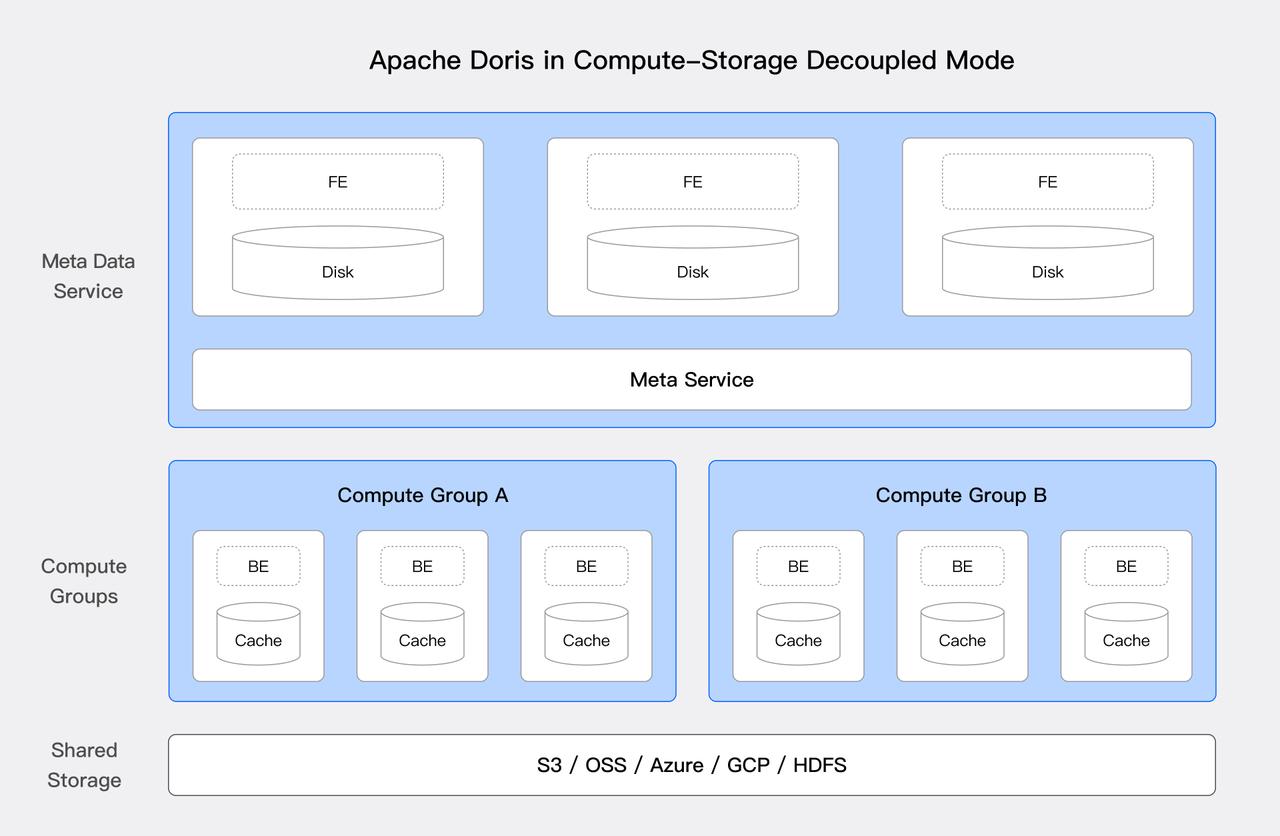
As illustrated above, in the compute-storage decoupled mode of Apache Doris, the compute nodes no longer store the primary data. Instead, HDFS or object storage serves as a unified, shared storage layer. This architecture powers a reliable and cost-efficient lakehouse in the following ways:
- Cost-efficient storage: Storage and compute resources scale separately, allowing enterprises to expand storage without incurring additional compute costs. Meanwhile, organizations benefit from low-cost cloud object storage and higher availability. For the frequently accessed hot data, users can still cache it on local high-speed disks for better performance.
- Single source of truth: All data is centralized in the shared storage layer, making it accessible across multiple compute clusters. This ensures data consistency, eliminates duplication, and simplifies data management.
- Workload flexibility: Users can dynamically adjust their compute resources to match different workloads. For example, batch processing, real-time analytics, and machine learning use cases vary in resource requirements. With storage and compute decoupled, enterprises can fine-tune resource usage for maximum efficiency across diverse operational demands.
Data storage and management
Apache Doris offers a rich set of data storage and management capabilities, supporting both mainstream lakehouse table formats like Iceberg and Hudi as well as its own highly optimized storage format. Beyond simply accommodating industry standards, Doris brings even greater flexibility and performance to the table.
- Semi-structured data support: Apache Doris natively supports semi-structured data types such as JSON and VARIANT to provide a schemaless experience that eliminates the overhead of manual data transformation and cleansing. Users can directly ingest raw JSON data, which Doris stores in a high-performance columnar format for complex analytics.
- Data updates: Doris enables near real-time data updates and efficient change data capture (CDC). Also, the partial column update capability allows users to easily merge multiple data streams into wide tables inside Doris, simplifying data pipelines.
- Data indexing: Doris offers various indexing options, such as prefix indexes, inverted indexes, skiplist indexes, and BloomFilter index to speed up query performance and minimize both local and network IO, especially in compute-storage decoupled environments.
- Stream and batch writing: Doris supports both bulk batch loading and high-frequency writes through micro-batching. It leverages MVCC (Multi-Version Concurrency Control) to seamlessly manage both real-time and historical data within the same dataset.
Openness
The openness of a data lakehouse is key to data integration and management efficiency. As discussed earlier, Apache Doris offers strong support for open table formats and file formats. Beyond that, Doris ensures the same level of openness for its own storage. It provides an open storage API based on the Arrow Flight SQL protocol, combining the high performance of Arrow Flight with the usability of JDBC/ODBC. Through this interface, users can easily access data stored in Doris using ABDC clients for Python, Java, Spark, and Flink.
Instead of relying solely on open file formats, Doris' open storage API abstracts away the underlying file format complexities, allowing it to fully exploit its advanced storage features like indexing for faster data retrieval. Meanwhile, the compute engine does not need to adapt to storage-level changes. This means that any engine supporting the protocol can seamlessly benefit from the Doris capabilities without additional integration work.
The end
The data lakehouse represents the future of unified analytics, but its success depends on overcoming performance and complexity barriers. Apache Doris combines the scalability of a data lake with the speed and reliability of a warehouse. It stays true to the idea of open data lakehouse with boundless data and architecture, and empowers it with its real-time querying capability, elastic scalability, and open-source flexibility.
Stay tuned for more real-world use cases, or join our discussion the Apache Doris community.