



In the world of information retrieval, Sparse Search (also known as Lexical Search or Keyword Search) stands as the foundational technology that powers traditional search engines. It is a highly efficient and accurate method for finding relevant documents based on exact keyword matching.
While modern techniques like vector search focus on semantic meaning, Sparse Search remains indispensable due to its speed, precision, and ability to handle critical, specialized vocabulary.
What is Sparse Search?
Sparse Search is a retrieval paradigm that represents both the user query and the documents in the corpus as a special kind of numerical structure: Sparse Vectors.
-
The Sparse Vector Representation
Imagine a massive dictionary (the vocabulary) where every unique word corresponds to a dimension in a vector.
- High Dimensionality: The total number of dimensions is equal to the size of the entire vocabulary (potentially tens or hundreds of thousands).
- Sparsity: Any given document or query only contains a tiny fraction of the total vocabulary. Therefore, the vast majority of the vector's elements are zero.
- Non-Zero Values (Weights): The few non-zero values correspond to the words that are present. These values are weights that represent the importance of that specific word to the document.
This "sparse" nature—where most entries are zero—is why the method is named Sparse Search.
-
The Core Mechanism: Keyword Matching
Unlike semantic search, which tries to understand the meaning of a query, Sparse Search focuses on the literal presence of terms. The search process calculates the similarity between the query's sparse vector and a document's sparse vector.
The higher the sum of the products of the non-zero weights for matching terms (often a dot product or a variation of it), the more relevant the document is considered.
How Sparse Search Works
The efficiency and effectiveness of Sparse Search are built upon two critical components: the weighting function and the indexing structure.
A. The Ranking Function (Weighting)
The most famous algorithms used to calculate the non-zero weights are:
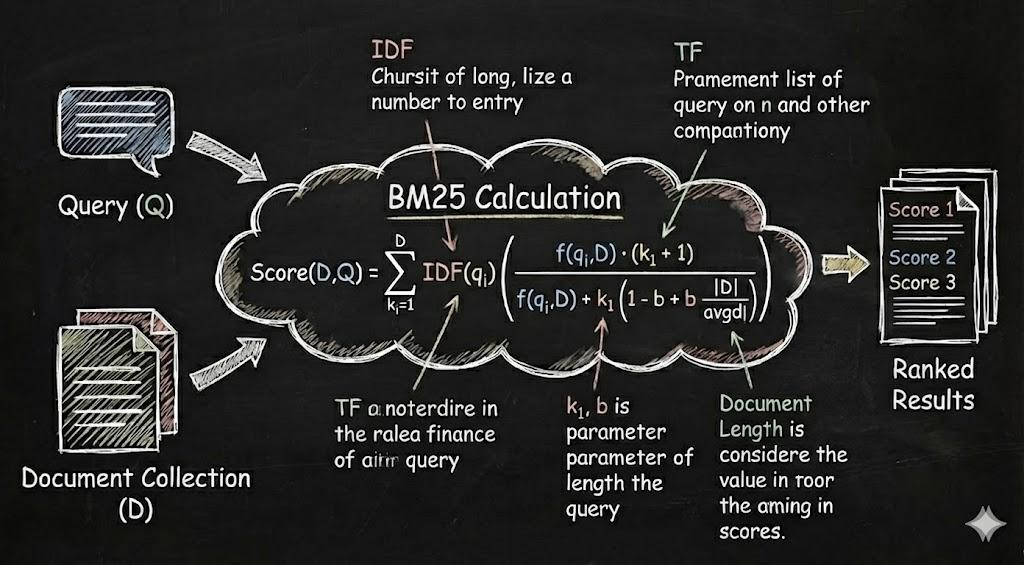
- TF-IDF (Term Frequency–Inverse Document Frequency): This traditional model balances how often a word appears in a document (Term Frequency, TF) against how rare it is across the entire corpus (Inverse Document Frequency, IDF).
- BM25 (Best Match 25): The industry standard for lexical search, BM25 is an evolution of TF-IDF. It improves relevance by accounting for term saturation (the idea that a word's importance doesn't infinitely increase with frequency) and document length normalization.
B. The Inverted Index (Indexing)
The Inverted Index is the data structure that makes Sparse Search incredibly fast. Instead of looking at a document and listing its words, the inverted index lists a word and shows all the documents that contain it.
When a user submits a query, the system quickly looks up each query term in the inverted index, immediately retrieving the set of matching documents. This eliminates the need to scan every document, allowing for near-instantaneous retrieval, even on massive datasets.
Key Advantages of Sparse Search
Despite the rise of Neural Networks, Sparse Search retains significant advantages:
| Advantage | Description |
|---|---|
| High Precision | Excels in scenarios requiring exact matches, such as searching for product IDs, specific legal terms, proper nouns, or error codes. |
| Speed and Efficiency | The underlying Inverted Index structure allows for incredibly fast lookups, making it ideal for real-time applications and massive log/text analysis. |
| Interpretability | The results are easily explainable: a document ranks highly because the query keywords were present with high weights. |
| Low Barrier to Entry | Traditional methods like BM25 require no complex model training and can be applied immediately to any text corpus. |
The Modern Approach: Hybrid Search
The main limitation of Sparse Search is its inability to understand semantic meaning or handle synonyms and paraphrasing. For example, a search for "auto maintenance" might miss a document about "car repair" if it relies solely on keywords.
To overcome this, modern vector databases and search platforms (like VeloDB) increasingly adopt Hybrid Search:
- Sparse Search ensures high recall of exact terms and critical entities.
- Dense Search (using Dense Vectors from models like BERT) ensures semantic understanding and captures conceptual similarity.
By combining the keyword-based precision of Sparse Search with the semantic flexibility of Dense Search, Hybrid Search delivers a retrieval experience that is both fast, comprehensive, and highly relevant.
Hybrid Search in VeloDB
VeloDB implements efficient sparse search capabilities through inverted index technology and provides flexible query functions to meet diverse retrieval needs.
Sparse Search Support
VeloDB has built-in inverted indexes based on the BM25 algorithm, supporting the following query types:
- MATCH_ANY: Matches any keyword (OR semantics)
- MATCH_ALL: Matches all keywords (AND semantics)
- MATCH_PHRASE: Exact phrase matching
- MATCH_PHRASE_PREFIX: Prefix phrase matching
Quick Start Examples
- Create a Table with Inverted Index
CREATE TABLE documents (
id INT,
title VARCHAR(200),
content TEXT,
INDEX idx_title (title) USING INVERTED,
INDEX idx_content (content) USING INVERTED PROPERTIES("parser" = "english")
) ENGINE=OLAP;
- Using Sparse Search Queries
-- Keyword search (OR): Match documents containing "database" or "search"
SELECT * FROM documents
WHERE MATCH_ANY(content, 'database search');
-- Phrase search: Exact match for "vector database" phrase
SELECT * FROM documents
WHERE MATCH_PHRASE(content, 'vector database');
-- Composite search: Combined with BM25 scoring and ranking
SELECT id, title, score() as score
FROM documents
WHERE MATCH_ANY(content, 'distributed query')
ORDER BY score DESC
LIMIT 10;
- Advanced Hybrid Retrieval
-- Hybrid search: Precise terms + semantic extension
SELECT * FROM documents
WHERE MATCH_ALL(title, 'Apache Doris') -- Sparse search: Exact entity matching
AND category = 'technology' -- Structured filtering
ORDER BY publish_date DESC;
Performance Advantages
- Inverted Index: Millisecond-level full-text retrieval, even at billion-document scale
- BM25 Scoring: Intelligent relevance ranking with automatic term frequency saturation handling
- Flexible Combination: Seamlessly integrates with structured queries and aggregation analysis
By combining the precision of sparse search with traditional SQL analytical capabilities, VeloDB provides enterprises with a unified retrieval and analysis platform.
