



-
Keyword Search, at its core, is an information retrieval technique that locates relevant data based on specific words or phrases (i.e., keywords) entered by the user. It stands as the most foundational and widely used method across search engines, databases, and various digital information systems globally.
I. Core Principles and Mechanism
The fundamental process of keyword search relies on matching the user's input with the content within documents. While complex optimizations exist, the basic workflow includes:
-
Indexing: Building the Inverted Index
Before searching, all documents must be processed to build an Inverted Index. This index maps words to the documents in which they appear, ensuring rapid lookups.
- Example:
Word A->Doc 1, Doc 5, Doc 10
-
Text Preprocessing
Both the documents and the user query undergo normalization to ensure consistency and accuracy:
- Tokenization: Breaking text into individual word units.
- Normalization: Unifying case (e.g., lowercase).
- Stop Word Removal: Eliminating common, low-value words (e.g., "the," "is," "a").
- Stemming/Lemmatization: Reducing words to their base or root form (e.g.,
running->run).
-
Retrieval and Ranking
After matching keywords against the index, documents are scored to determine relevance. The classic ranking algorithm is TF-IDF (Term Frequency-Inverse Document Frequency):
- Term Frequency (TF): How often the keyword appears in the current document.
- Inverse Document Frequency (IDF): The rarity of the keyword across all documents. Rarer words receive higher weight.
II. Advantages and Limitations
Feature Advantages (Pros) Limitations (Cons) Speed Extremely fast retrieval due to the inverted index structure, ideal for massive datasets. Lacks Semantic Understanding Simplicity Easy to implement and use; requires no complex query language from the user. Synonym Problem Versatility Applicable across text, code, and structured data. Ambiguity (Polysemy) III. Evolution: Modern Search and Hybrid Retrieval
To overcome the semantic limitations of traditional keyword matching, modern search systems have adopted advanced techniques:
- Query Expansion: Automatically adding synonyms, related terms, and spelling variations to the user's query to increase recall.
- Vector Search (Semantic Search): Transforming both queries and documents into high-dimensional numerical embeddings (vectors) that capture their meaning. Relevance is determined by the similarity (e.g., Cosine Similarity) between these vectors, allowing the system to understand intent rather than just literal word matches.
- Hybrid Search****: Combining the speed of traditional Keyword Search (exact matching) with the accuracy of Vector Search (semantic matching) to achieve the best of both worlds.
VeloDB****, a specialized database for search, supports Hybrid Retrieval, seamlessly integrating both keyword-based and vector-based search methods to deliver more relevant and comprehensive results.
VeloDB Keyword Search
Principle
Inverted Index: Maps terms to document ID lists, enabling fast keyword queries.
"Machine Learning" → Tokenization → ["Machine", "Learning"] → Inverted Index → [doc1, doc2, ...]Two Modes:
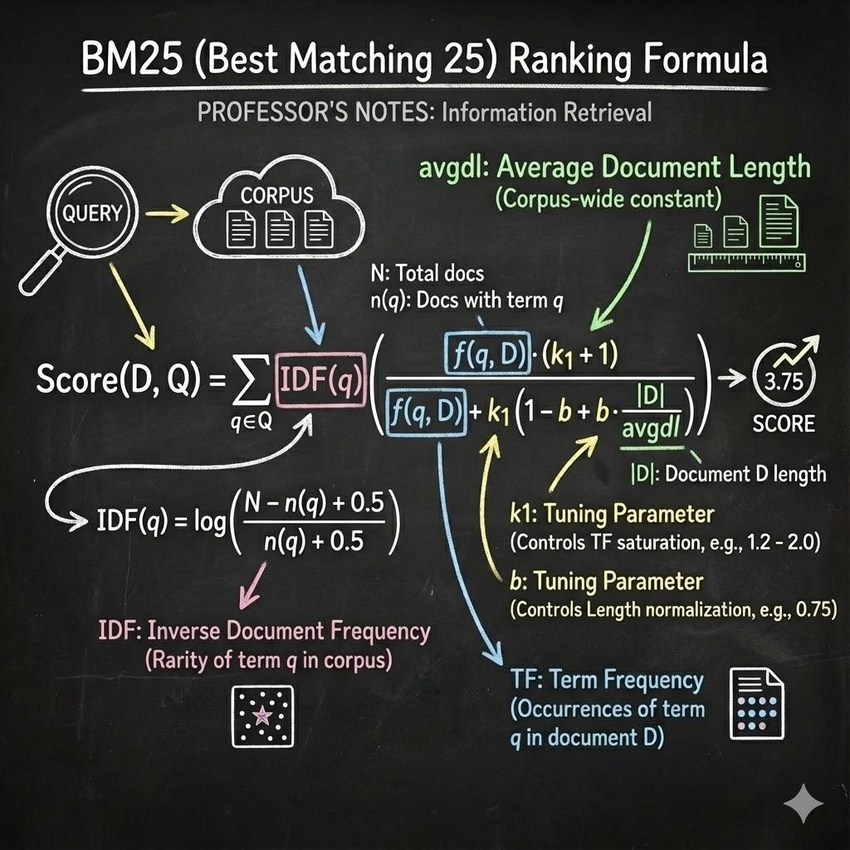
- Tokenized Index: Text tokenized before indexing, supports fuzzy matching + BM25 scoring
- Untokenized Index: Whole-value indexing, exact matching
Usage
-- 1. Create Index CREATE TABLE docs ( id INT, content TEXT, status VARCHAR(20), INDEX idx_content (content) USING INVERTED PROPERTIES("parser"="standard"), -- Tokenized INDEX idx_status (status) USING INVERTED -- Untokenized (default) ) DUPLICATE KEY(id) DISTRIBUTED BY HASH(id) BUCKETS 3; -- 2. Exact Query (Untokenized Index) SELECT * FROM docs WHERE status = 'ACTIVE'; -- 3. Full-Text Search (Tokenized Index) SELECT * FROM docs WHERE content MATCH_ALL 'machine learning'; -- 4. BM25 Scoring & Ranking (Tokenized Index Only) SELECT id, content, BM25() as score FROM docs WHERE content MATCH_ALL 'deep learning' ORDER BY score DESC;Comparison
Untokenized Index Tokenized Index Parser None standard, english, chinese Query status = 'ACTIVE' content MATCH 'learning' BM25 No Yes Use Case Status, Tags, IDs Articles, Comments Summary: VeloDB Inverted Index supports both tokenized and untokenized modes with BM25 relevance scoring.
-
- Products
- Solutions
Real-Time Analytics
Real-time database for real-time data warehousing, customer-facing and agent-facing analytics
Lakehouse Analytics
The fastest lakehouse SQL engine, replacing Trino/Presto, SparkSQL
Observability and Log Analytics
The most cost-effective alternative to Elasticsearch observability
VeloDB for AI
The AI-Ready analytics database for the AI era
- Docs
- Resources
- Pricing
- Contact us
Back
Keyword Search: The Cornerstone of Information Retrieval
Keywords:
