



When it comes to ingesting data in a lakehouse, two methods are top of mind: Merge on Read vs Copy on Write. Following the typical trade-off in data management, one method requires the user to pay for the heavy lift upfront, resulting in faster reads. At the same time, the other defers the heavy lift until the data is queried, resulting in faster writes. What if you can have the best of both worlds with Merge on Write
What is Merge on Write?
Merge on Write (MoW) is a primary-key table model in VeloDB designed for low-latency analytics and real-time reporting. Compared with Merge on Read (MoR), MoW pushes more work to the write path so the read path stays fast and predictable.
How MoW works (at a glance)
- New row arrives with a duplicate primary key.
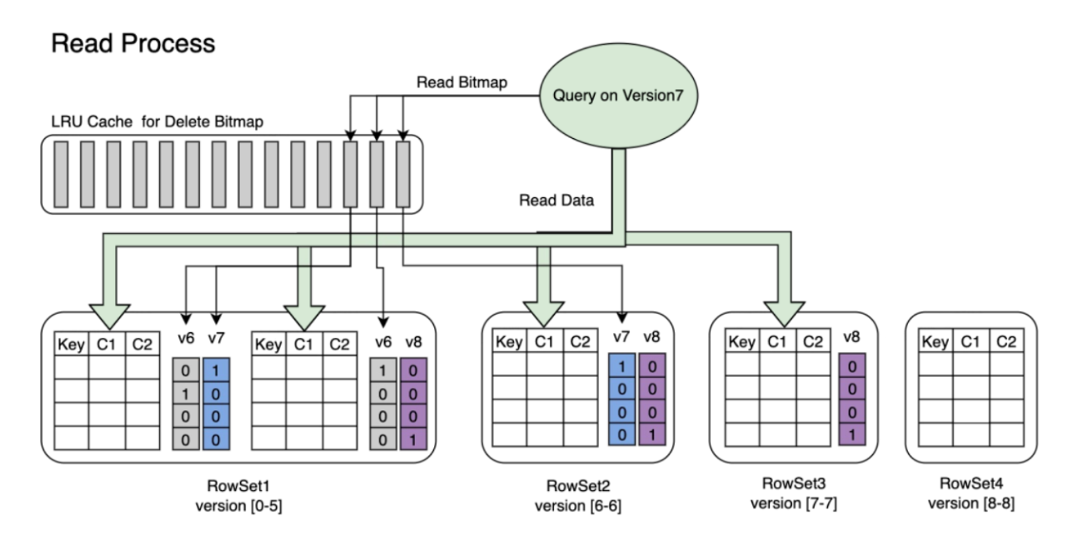
- VeloDB marks the old row as deleted by writing a Delete Bitmap during ingestion.
- At query time, the engine performs vectorized scans, skipping dead/deleted rows, avoiding CPU-intensive, runtime merges. no on-the-fly merge required.
Result: Lighter scans, lower CPU, sub-second queries under heavy analytical workloads, and stable latency as data volume grows
Why not just Copy-on-Write (CoW)?
People often search for “copy-on-write vs merge-on-read”. CoW is a file-level strategy (rewrite on update) often used in lake/warehouse formats. It rebuilt files on modification, which can be expensive for high-velocity analytical updates. MoW is a table/engine-level primary-key model that specifically optimizes deduplication and point updates without full file rewrites.
MoW vs MoR vs CoW (quick comparison)
| Criterion | Merge on Write (MoW) | Merge on Read (MoR) | Copy-on-Write (CoW) |
|---|---|---|---|
| Where work happens | Write path (dedup markers) | Read path (dedup on scan) | File rewrite on update |
| Query latency | Lowest (sub-second) | Higher (runtime merge) | Varies; can be good but costly on update-heavy data |
| Ingest cost | Slightly higher | Lower | High for frequent updates |
| Freshness under load | Consistent | Can degrade as duplicates accumulate | Consistent but at rewrite cost |
| Best for | Read-intensive, PK-update streams, real-time analytics | Cheaper ingest, less frequent reads | Slowly changing data, batchy updates |
Typical MoW use cases
- Real-time reporting that targets
<1squery latency. - Web3 analytics combining on-chain + off-chain events.
- User behavior analysis for e-commerce/gaming (high-velocity updates).
- Monitoring & alerting where instant visibility matters.
When to choose each model
- Choose MoW if: you want sub-second reads on fresh data, steady high QPS, and predictable latency under streaming upserts.
- Choose MoR if: your priority is faster ingest and queries are less frequent or tolerant of higher latency.
- Choose CoW if: updates are batchy/infrequent and you prefer simpler file semantics over streaming upserts.
Example: How MoW keeps queries fast
- A session event updates a user’s latest balance 20 times in a minute.
- With MoR, that minute produces N duplicates that are merged at query time.
- With MoW, each new balance marks the previous one deleted at write time; the query only touches live rows.
Implementation tips (production)
- Primary keys: define PKs that match your update semantics (e.g.,
user_id,event_ts). - Batching: micro-batch ingestion balances throughput and delete-bitmap granularity.
- Compaction cadence: compact periodically to co-locate live rows and reduce data files.
- Partitioning: partition by time or entity to localize reads.
- Monitoring: track “deleted-row ratio” and compaction backlog.
FAQs
What’s the trade-off of MoW vs MoR? MoW makes reads faster by doing more work on writes (maintaining delete bitmaps). Expect slightly slower ingestion than MoR, but significantly faster queries.
Does MoW increase storage? Usually, modestly deleting bitmaps and intermediate segments adds overhead, but compaction controls long-term growth.
Can I switch models later? Yes—migrations are possible. Many teams start MoR, then adopt MoW once latency targets tighten.
Is MoW the same as copy-on-write? No. CoW rewrites files on updates; MoW manages PK conflicts with write-time metadata so reads skip stale rows.
Summary
Merge on Write in VeloDB is purpose-built for real-time analytics. By generating a Delete Bitmap at write time, MoW dramatically boosts query performance and keeps latency sub-second, even at scale. If your workloads are read-intensive and freshness-sensitive, MoW is the right default
