


In modern data analytics, speed, flexibility, and accuracy go hand in hand. That's why we built a bridge between Apache Flink and Apache Doris, helping users turn constant streams of data into real-time insights.
Apache Flink is a popular streaming data processing engine, widely used to process data from diverse sources such as operational databases, message queues, and more. Apache Doris is a real-time data warehouse, known for delivering fast analytics on large-scale datasets.
To bring them together, we built the Flink Doris Connector. The Flink Doris Connector is far more than a data replication tool. It offers:
- Reading data from Doris with support for parallel reading from Doris backend nodes for high throughput.
- Writing data to Doris using Flink's batching and Doris's Stream Load for efficient bulk imports.
- Joining streaming data and dimension tables in Doris with Lookup Join, using batch and asynchronous queries to accelerate the process.
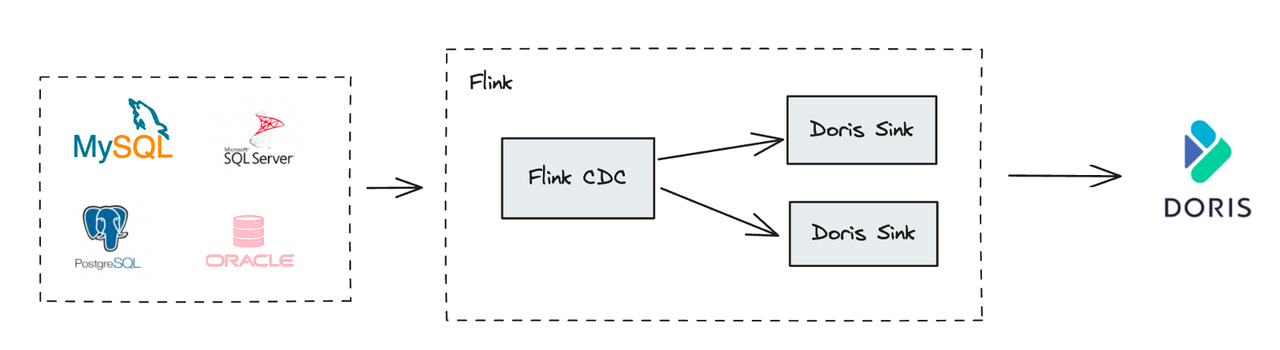
In addition, Apache Flink also built Flink CDC (Change Data Capture) to help sync data from operational databases (such as MySQL, Oracle, and PostgreSQL) to analytical databases like Apache Doris. The Flink CDC supports both full database synchronization and incremental synchronization, as well as automatic table creation and DDL operations (schema changes).
In this article, we'll discuss the main technical use cases of Flink Doris Connector and Flink CDC, showing a complete playbook to combine Flink's real-time processing with Doris's fast analytics.
Apache Doris and Flink Doris Connector
Apache Doris is a high-performance, real-time analytical database based on the MPP architecture (Massively Parallel Processing). Its overall architecture is streamlined, with only two system modules: FE (Frontend) and BE (Backend). The FE mainly handles request routing, query parsing, metadata management, and task scheduling, while the BE is responsible for query execution and data storage. Doris supports standard SQL and is fully compatible with the MySQL protocol, allowing users to access Doris using any MySQL-compatible client tools and BI software.
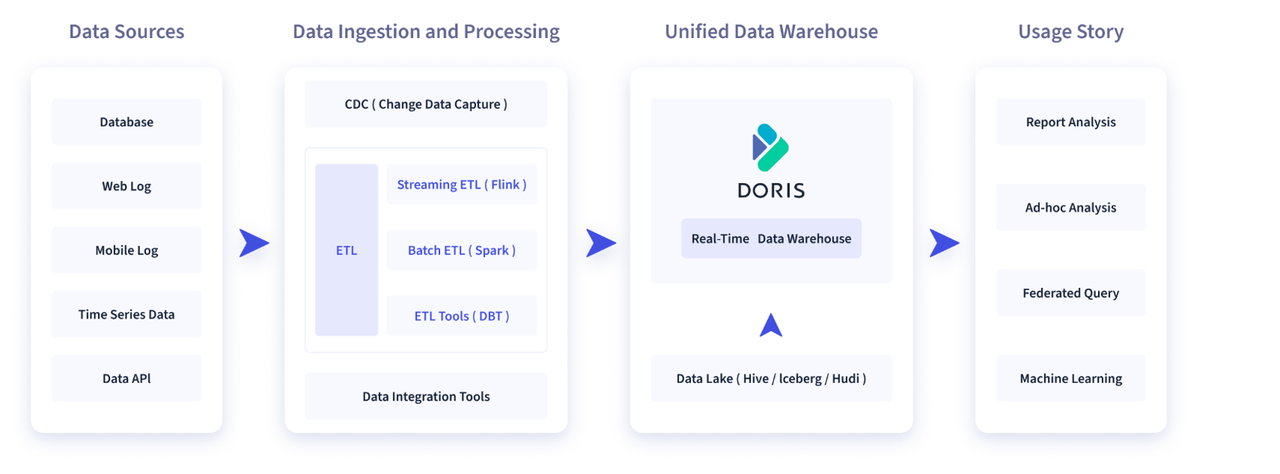
A typical data integration and processing pipeline looks like this: Data Collection → Data Processing → Data Storage → Data Application.
- Data Collection: Data is collected from many sources, including operational databases, user behavior logs, time-series streams, local files, and more.
- Data Processing: These datasets are then processed through data integration or ETL tools (Extract, Transform, Load).
- Data Storage: The processed data is being written into Apache Doris, the real-time data warehouse.
- Data Application: Doris powers downstream applications, including BI dashboards, OLAP multidimensional analysis, ad-hoc queries, and log search. Doris then serves as the query and analytics engine for downstream applications, powering common use cases such as BI report analysis, OLAP multidimensional analysis, ad-hoc queries, log search and analysis, and more.
The Flink Doris Connector integrates Apache Doris and Apache Flink for real-time data processing ETL, leveraging Flink's real-time computing capabilities to build an efficient data processing and analytics pipeline. It supports three primary use cases:
- Scan from Doris: Typically used for data synchronization or joint analysis with Apache Doris.
- Lookup Join: Joins data from real-time streams with dimension tables in Doris.
- Real-time ETL: Uses Flink to extract and transform data and write it into Doris in real time.
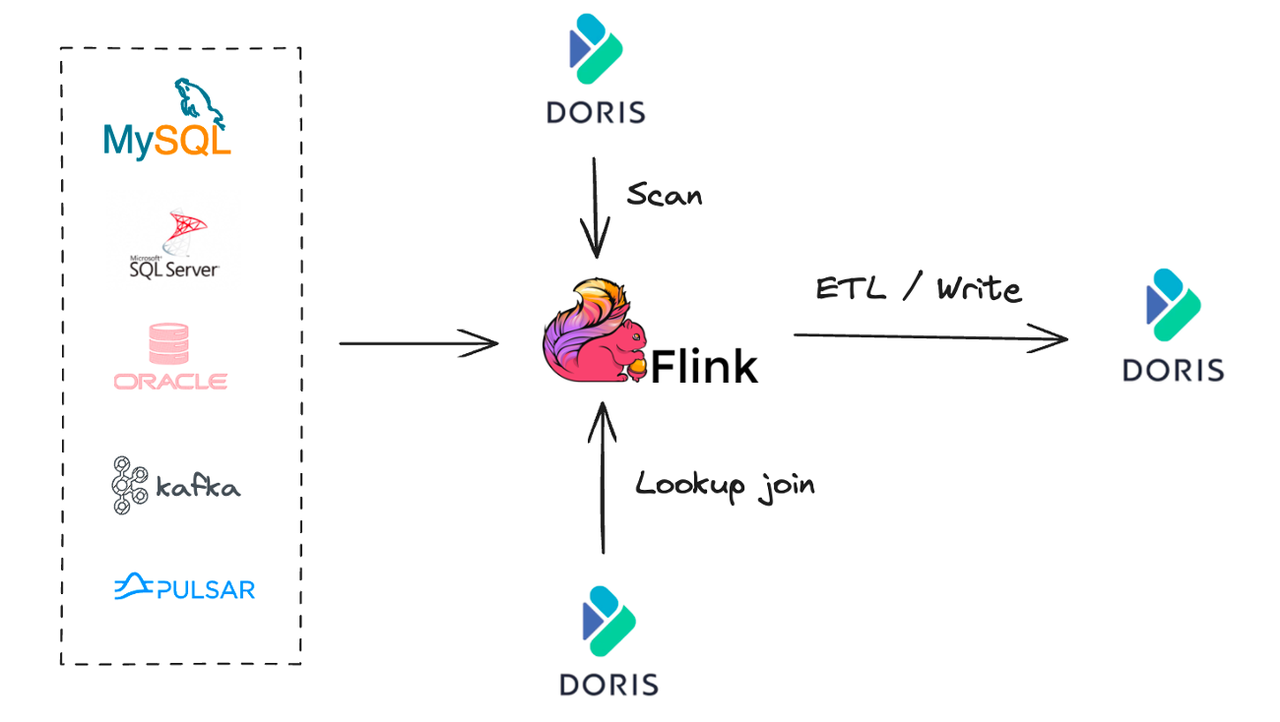
Common Use Cases of Flink Doris Connector: Scan, Lookup Join, and Write
This section introduces the design and implementation of the Flink Doris Connector, and looks into details of the three main use cases: Scan, Lookup Join, and Write.
1. Scan
The Scan scenario refers to quickly extracting existing data from Doris. Traditional JDBC methods may face performance bottlenecks when reading large amounts of data from Doris. The Flink Doris Connector addresses this with Doris Source, which takes advantage of Doris's distributed architecture and Flink's parallel processing to speed up data synchronization.
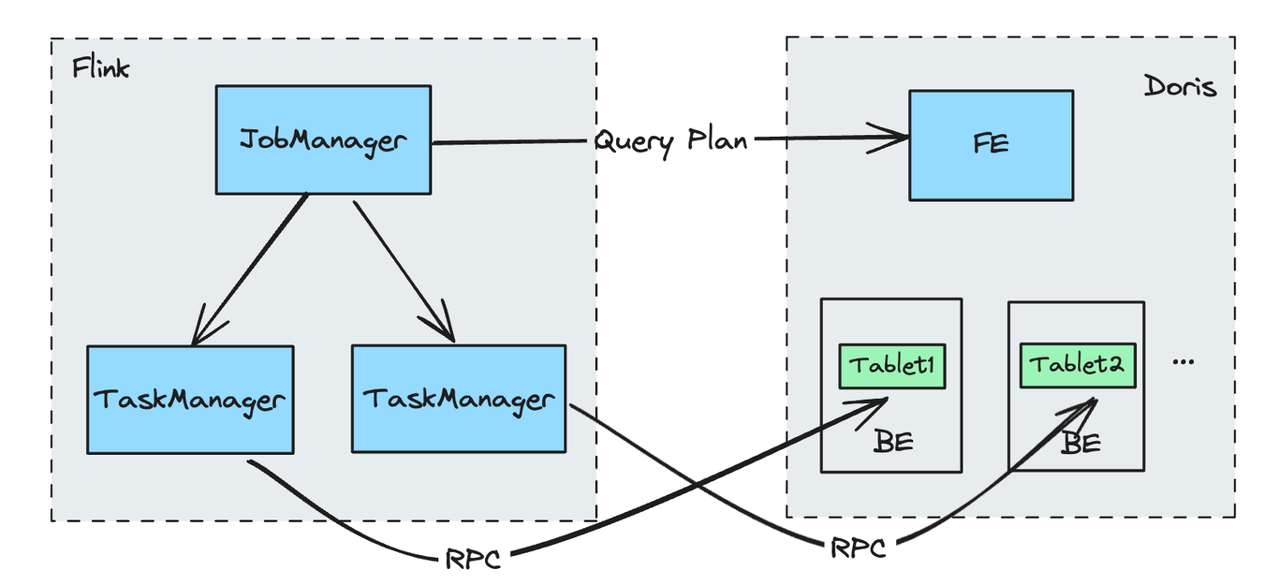
Doris Source Reading Process:
- The Job Manager requests a query plan from the Doris FE (Frontend), which returns the corresponding BE (Backend) nodes and Tablet for the data to be queried.
- Requests are distributed to different Task Managers based on the different BEs.
- Each Task Manager reads data from the assigned Tablets directly and in parallel from the corresponding BE, enabling scalable and concurrent data retrieval.
Using this method, we can leverage Flink's distributed processing capabilities to improve the efficiency of the entire data synchronization process.
2. Lookup Join
Users can use the Lookup Join feature in the Flink Doris Connector to do a join query, joining data from real-time streams in Flink and dimension tables in Doris.
JDBC Connector:
Doris supports the MySQL protocol so that a standard JDBC Connector can also perform Lookup Joins. However, this approach has limitations:
- The Lookup Join in the JDBC Connector performs synchronous queries, which means each data in the real-time stream must wait for Doris' query result, increasing latency.
- It only supports querying one record at a time. High upstream throughput can easily cause bottlenecks and backpressure.
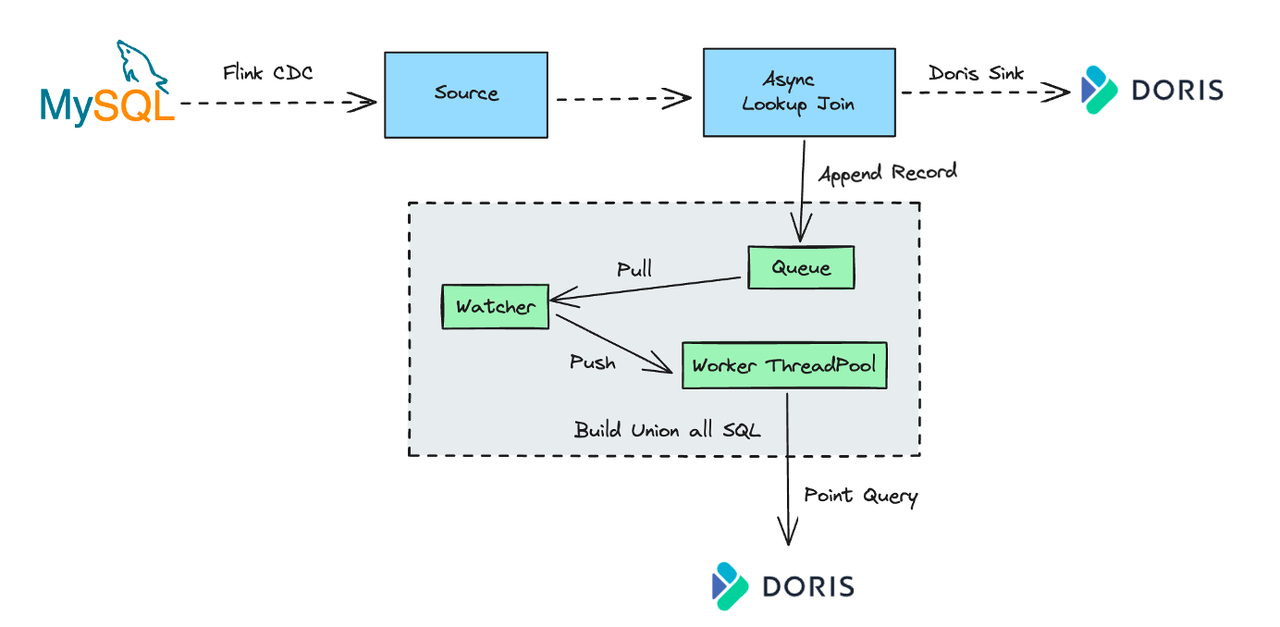
Optimization in Flink Doris Connector:
To address the above limitations in the Lookup Join scenario, the Flink Doris Connector achieved asynchronous and batch optimizations:
This means that data in the real-time stream does not need to wait for each query result, significantly reducing latency. Incoming real-time events are appended to a queue. A background listener thread (Watcher) retrieves data and pushes it to a query execution worker thread pool (Worker). The worker threads would combine the received data batch into a single Union All query and send this query to Doris.
These optimizations improve dimension table join throughput under heavy load, ensuring efficient data reads and processing.
3. Real-time ETL
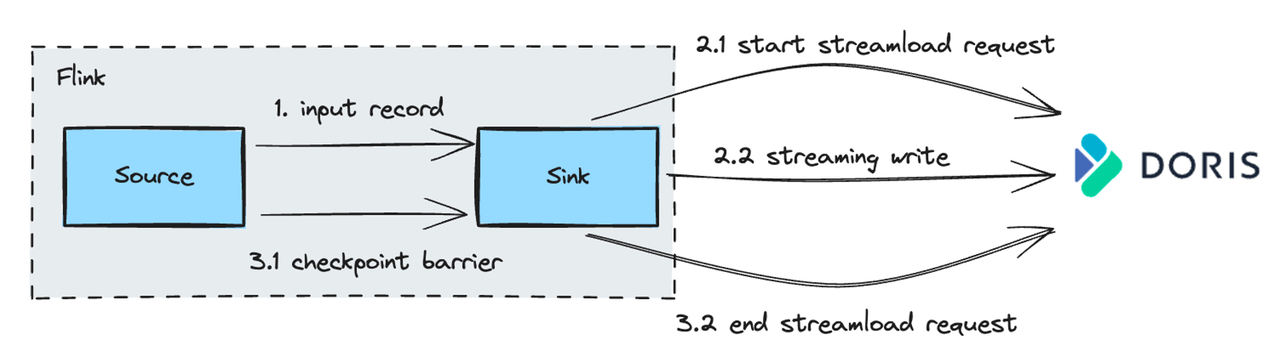
For writing data into Apache Doris in real-time, Sink uses the Stream Load method, one of the most common data ingestion methods in Apache Doris. Stream Load supports loading data into Doris via HTTP from local files or data streams.
Stream Load process:
- After receiving the data, the Sink will initiate a long-lived Stream Load request to Doris. During the Checkpoint interval in Flink, it continuously sends the received data to Doris in chunks.
- At Checkpoint, only after the previously initiated Stream Load request is committed to Doris does the data become visible.
Ensuring Exactly-Once Semantics for Data Writing:
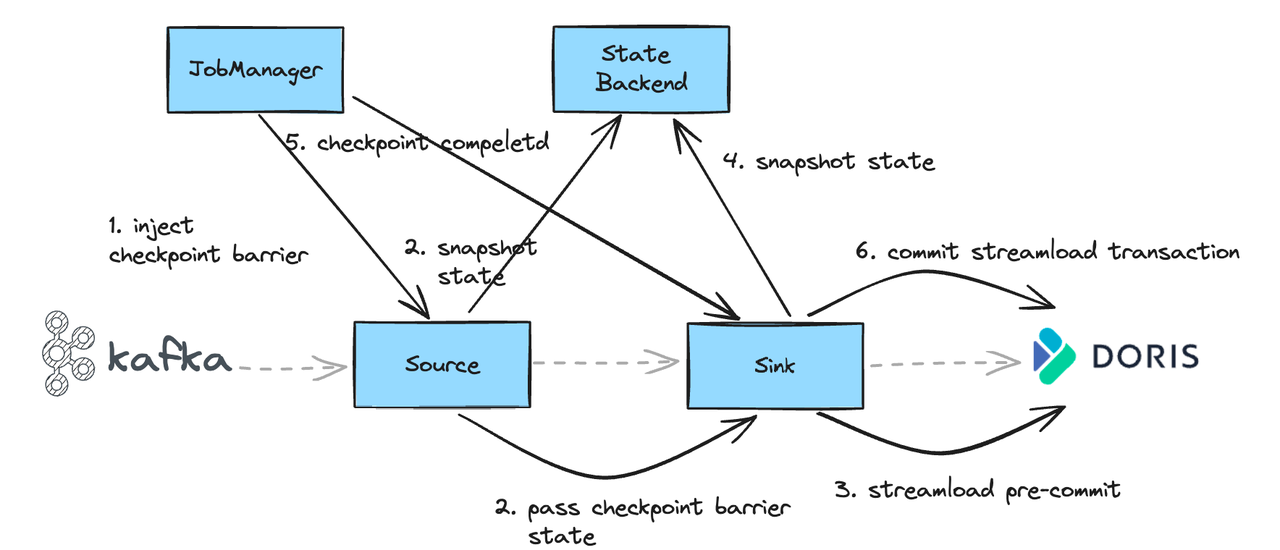
To guarantee exactly-once semantics for end-to-end data writing, Sink uses a two-phase commit process. For example, when syncing from Kafka to Doris:
- At Checkpoint, Source will receive a Checkpoint Barrier.
- After receiving the Barrier, Source snapshots its state and forwards the Checkpoint Barrier down to the Sink.
- Upon receiving the Barrier, Sink performs a pre-commit operation. If successful, the data is fully written to Doris but remains invisible to users.
- The transaction ID of the successfully pre-committed operation is saved in the state.
- Once all task checkpoints are completed, the JobManager notifies that the current Checkpoint has been completed.
- Sink then commits the previously pre-committed transaction, making the data visible.
Balancing Real-Time and Exactly-Once:
Since Doris Sink commits are tied to Checkpoints, the writing operation latency depends on the Checkpoint interval. Some users require real-time, low-latency writes but can't afford very frequent Checkpoints, as these can be resource-intensive.
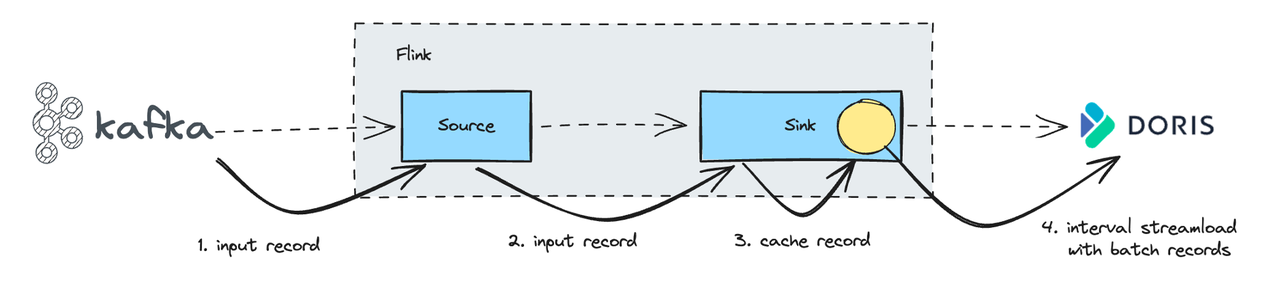
To address this, the Flink Doris Connector introduced a batch mechanism:
- Incoming data is temporarily cached in memory rather than written into Doris individually.
- Then, using specific configuration parameters, the cached data is committed to Doris.
- By combining batch writes with Doris's primary key model, this process ensures idempotent data insertion, ensuring each record is written only once.
This mechanism balances the need for real-time ingestion with efficient resource usage, improving both performance and cost-effectiveness.
Flink CDC: Full Database Synchronization and Incremental Synchronization
Now let's see how Flink CDC can be used to synchronize an entire operational database to Apache Doris, as well as synchronize incremental ongoing data changes to Doris.
1. Challenges in Full Database Synchronization
When migrating data, users often want to move data into Doris as quickly as possible. However, syncing an entire operational database often runs into the following challenges:
- Automatic creation and sync for new tables after the synchronization task is started: To keep data complete and up to date, the sync tool must monitor data changes in operational databases in real time and automatically create and sync them in Doris.
- Metadata mapping: Easy mapping of field metadata between upstream and downstream, including field type conversions, corresponding field name modification, and others.
- Automatic DDL synchronization: Schema changes (such as adding or dropping columns) can affect sync processes. The sync tool needs to capture DDL changes in real time and update Doris tables accordingly to keep data accurate and consistent.
- Ready to use: The sync tool should be low-code with simple configuration, easy for users to set up, and start to migrate and synchronize data.
2. Full Database Sync with Flink CDC
Flink CDC offers robust capabilities:
- Incremental snapshot reading:
- Lock-free and parallel reading: Regardless of dataset size, sync speed can be significantly boosted by increasing Flink's parallelism.
- Resumable synchronization: If a large sync job is interrupted, CDC can resume the task from where it left off.
- Rich data source support: Flink CDC supports various databases, including MySQL, Oracle, SQL Server, and more.
One-Click Table Creation & Automatic Metadata Mapping
With Flink CDC integrated, the Flink Doris Connector lets users perform a full database sync with a single operation. The core principle is that the Flink CDC Source, after receiving data from upstream sources, performs stream splitting by routing different tables to different sinks. In the latest versions of the Connector, a single Sink can also handle multiple tables and automatically create and sync new tables.
Additionally, with Flink CDC integration, users only need to submit tasks through Flink Doris Connector to automatically create the required tables in Doris, without configuring explicit associations between upstream and downstream tables, getting faster data synchronization.
When a Flink job starts, the Doris Flink Connector will automatically check whether the corresponding Doris table exists:
- If it doesn't, the Connector will automatically create it and perform stream splitting based on table name, so the downstream can handle multiple table sinks.
- If it does, the sync starts immediately.
This improvement simplifies configuration, makes new table creation and synchronization much easier, and ultimately boosts overall data processing efficiency.
Light Schema Change and Automatic DDL Synchronization
Apache Doris has introduced the Light Schema Change mechanism, which enables schema changes (like adding or dropping columns) in milliseconds, so users no longer need to pause the data sync job to wait for schema changes.
Test results show that compared to earlier Schema Change methods, Light Schema Change delivers up to 200 times faster performance in data synchronization. For example, in adding columns, Light Schema Change managed to cut down the time from 1 second and 310 milliseconds down to 7 milliseconds, and in dropping columns, from 1 second and 438 milliseconds down to 3 milliseconds.
Light Schema Change in Doris enables automatic DDL synchronization (Data Definition Language) through Flink CDC. The specific steps are:
- The Source side captures upstream Schema Change information and initiates DDL synchronization
- The Doris Sink side identifies and parses DDL operations (such as adding or dropping columns)
- Table validation is performed to determine whether a Light Schema Change can be applied
- Initiate the Schema Change operation
Thanks to this mechanism, Doris can automatically detect DDL statements and complete the Schema Change operation within milliseconds. This means that even when there are table structure changes in the upstream operational database, the data synchronization task can continue to run.
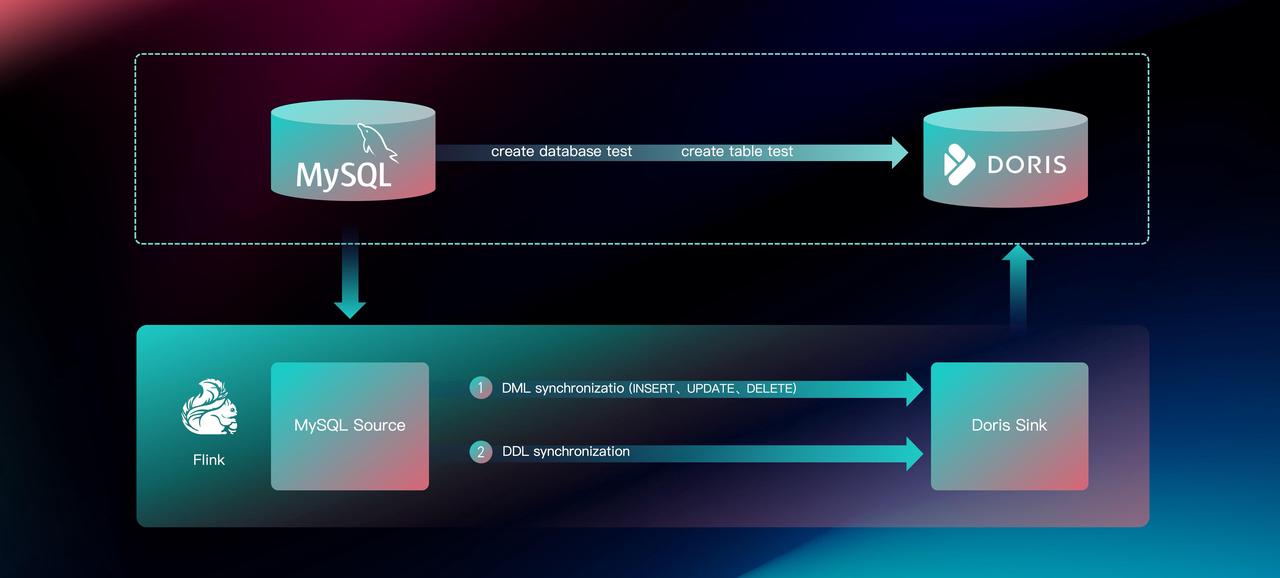
Ready-to-use: Full MySQL Database Synchronization Example

Users can submit a full database synchronization job via the Flink client with the steps shown above. The job supports passing in Flink configurations such as parallelism settings and checkpoint intervals. It also allows using regular expressions to specify which tables to synchronize. Additionally, configurations for both the Flink CDC Source and Doris Sink can be directly passed through to the specific connector. This streamlined approach makes it easy and convenient for users to submit full database synchronization jobs.
Core Advantages of Flink Doris Connector
- Automatic Table Creation: Both existing and incremental tables are created automatically, so users don't need to predefine table schemas in Doris.
- Automatic Field Mapping: Upstream and downstream field mappings are handled automatically without the need to write manual matching rules, saving significant effort.
- Schema Change with No Downtime: Column additions or deletions are synchronized seamlessly by capturing upstream DDL statements and applying millisecond-level schema changes in Doris, with no service interruptions and ensuring smooth data sync tasks.
- Plug-and-Play: Easy to use out of the box, freeing users to focus more on business logic.
Future Plans
Here are our future development plans for the Flink Doris Connector:
- Multi-table Sinks per Stream Load Connection: Currently, the Flink Doris Connector supports syncing multiple tables in a single Sink, but Stream Load only allows importing one table per connection. This means that when syncing a large number of tables, users must maintain a large number of Stream Load connections. In the future, we aim to support writing multiple tables in a single Stream Load connection.
- Broader Data Source Support: To accommodate more diverse data synchronization scenarios, we will add support for more upstream data sources.
Learn more about the Flink Doris Connector in our documentation. You are more than welcome to join the Apache Doris community on Slack, where you can connect with Doris experts and other users. If you're exploring fully-managed, cloud-native options, contact the VeloDB team.