TL;DR:
A major music streaming platform successfully migrated its massive log analytics infrastructure from ClickHouse to Apache Doris. Handling over a trillion new log entries daily (ingesting at 6GB/s peak) across 50 servers and 2PB of data, Apache Doris delivered:
- 3-7x faster full-text search queries (MATCH with inverted index vs. LIKE)
- 30% reduction in P99 query latency
- 2.5x higher query concurrency (500+ vs. less than 200)
- Significant operational cost reduction and improved stability
The Challenge: Drowning in Logs, Striving for Stability and Speed
For a leading music streaming service, logs are the lifeblood – tracking user behavior, business operations, and system health. With a daily influx of over a trillion log entries (hundreds of TBs), their existing ClickHouse-based log warehouse was buckling under the pressure. The core issues were:
- High operational costs: Managing ClickHouse clusters was a significant burden. Manual intervention was often required for disk failures, node outages, and scaling, sometimes even necessitating write-task restarts.
- Steep learning curve: ClickHouse's variety of table engines (MergeTree, ReplacingMergeTree, Replicated variants) made it complex for new team members.
- Insufficient query concurrency: Performance degraded sharply under high concurrent query loads, failing to meet business demands.
- Unstable write performance: Single node failures or bad disks could trigger write task failovers, often requiring manual restarts.
These challenges hampered their ability to efficiently track anomalies, resolve customer issues, monitor system status, and optimize performance.
The Search for a Solution: Why Apache Doris?
The team sought a more robust, scalable, and cost-effective solution. Apache Doris emerged as the clear winner, aligning perfectly with their needs for easy operations, high concurrency, stable large-scale writes, and future-proofing with its data lake capabilities and tiered storage. Key attractions included:
- Simplicity and ease of use: Familiar SQL interface meant a low learning curve. Doris’s robust distributed cluster management and horizontal scalability simplified operations.
- High-throughput, low-latency writes: Proven ability to handle hundreds of TBs daily at GB/s speeds with sub-second latency.
- Inverted index and high-performance full-text search: Support for inverted indexes and full-text search enables second-level responses for common log queries.
- Cost-effective massive storage: PB-scale storage capacity with options to offload cold data to S3/HDFS for further cost savings.
- Open and rich ecosystem: Easy integration with common log collection systems (Logstash, Filebeat, Kafka via Stream Load) and visualization tools (Grafana, Kibana, VeloDB Discover).
The Results: A New Era of Log Analytics with Apache Doris
The migration from ClickHouse to Apache Doris was relatively smooth due to both systems using a relational model and SQL. The primary changes involved adapting the upstream Flink write programs and updating downstream query SQL. After a two-week parallel run validating data consistency, Doris fully replaced ClickHouse.
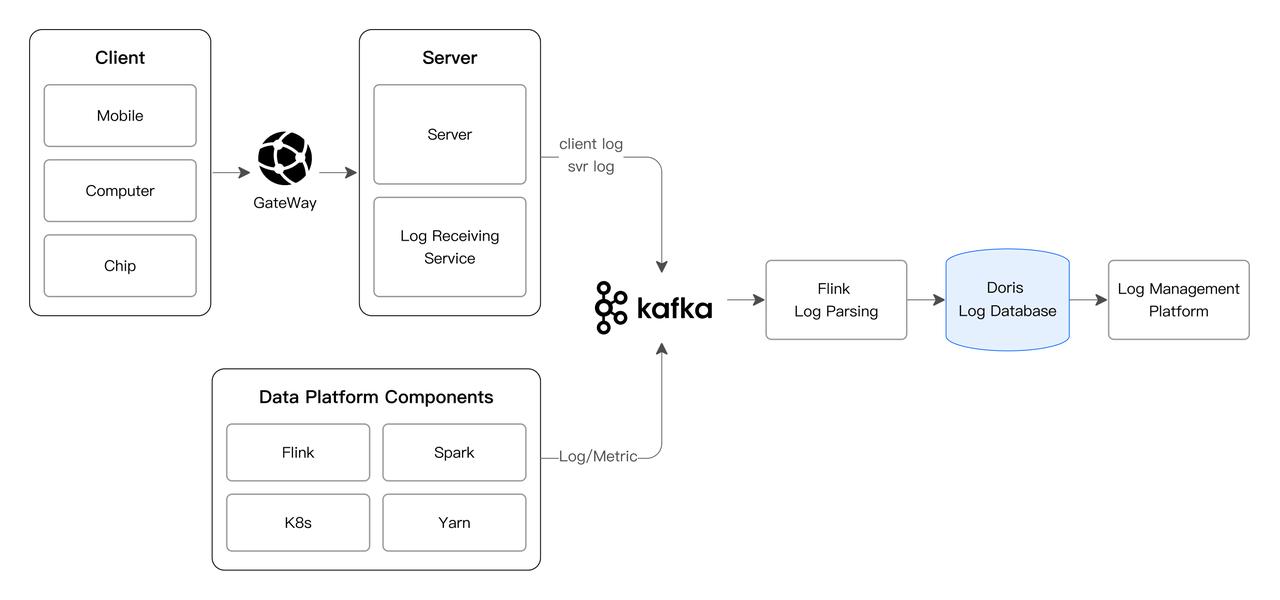
The new Apache Doris-based platform, now stable for three quarters with 50 servers, 2PB of data, and handling over a trillion new logs daily (peak 6GB/s ingest), delivered significant improvements:
- Massively Improved Query Performance & Concurrency:
- Overall P99 query latency reduced by 30%.
- Full-text search (MATCH) 3-7x faster than ClickHouse's LIKE (e.g., querying 6TB, MATCH took 1-3s vs. LIKE's 7-9s). Doris's inverted index also improves search recall by text normalization like case insensitive.
- Query concurrency boosted to 500+ compared to ClickHouse's ~200 limit before errors.
- Enhanced Write Stability & Throughput:
- Achieved peak ingestion of 6GB/s.
- Automatic failover and recovery for FE/BE node failures ensure high service availability.
- Significant Operational Cost Reduction & Efficiency:
- Storage savings of over 30% compared to ClickHouse by using ZSTD compression in Doris.
- Doris’s self-healing capabilities and automated recovery drastically reduced manual intervention for disk/node failures.
- Automatic data balancing during scaling or maintenance streamlined operations.
- Optimized table design (time-based partitioning, random bucketing, sort keys aligned with common query patterns, inverted indexes for text fields, and time_series compaction) played a crucial role.
- Simplified Management & Robustness:
- Automated partition balancing and disk balancing strategies ensure stable cluster performance.
- Comprehensive observability via Grafana, automated alerting, and self-healing mechanisms further reduce operational burden.
This leading music streaming service now runs over 100 Doris nodes (for logs and other analytics) and plans to expand its use, leveraging features like tiered storage, workload groups for resource isolation, and its data lake capabilities to build a "One-SQL" data architecture.
Talk to us
If you want to bring similar (or even higher) performance improvements and benefits to your data platform, or just explore further on Apache Doris, you are more than welcome to join the Apache Doris community, where you can connect with other users facing similar challenges and get access to professional technical advice and support.
If you're exploring fully-managed, cloud-native options, you can reach out to the VeloDB team!