Who is using VeloDB?
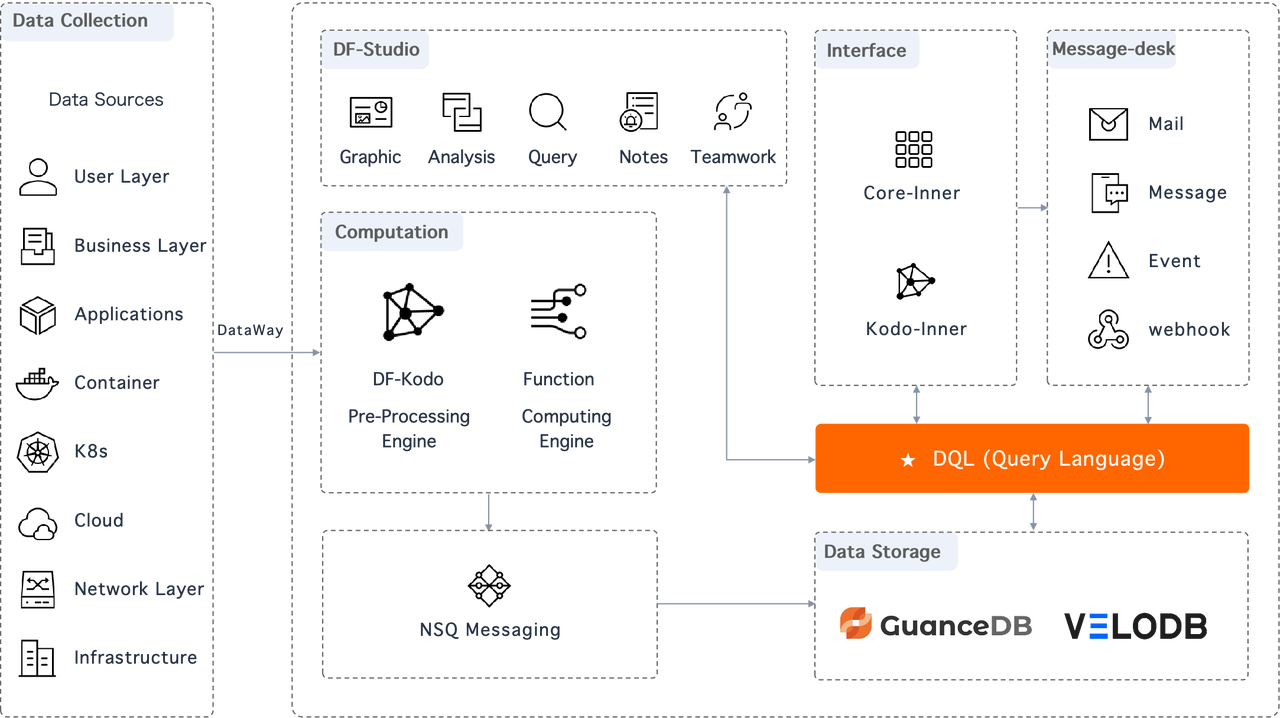
Guance is a real-time data monitoring and observability platform. The idea of observability is to monitor systems from all dimensions and perspectives to offer actionable insights for system troubleshooting and business analysis. For an observability platform, the client side collects data from all kinds of environments, middlewares, and systems, while the backend should be able to communicate with various programming languages. In terms of data storage, it is better to have as less components as possible to avoid compatibility issues and inconsistent query interface.
After evolutions and upgrades, Guance decided to use VeloDB together with its self-developed GuanceDB to support its data analysis and storage.
What does an observability platform need?
Data access for an observability platform is faced with some unique challenges:
- High data diversity: For the sake of monitoring, all data should be collected to provide a 360-degree perspective. That means a wider range of data writing operations and query workloads. The platform should be able to undertake data updates at various scale and frequency, and support almost all common query types, such as point queries, range queries, and aggregated queries.
- High writing throughput: Guance requires a writing throughput of almost a million rows per second for a single availability zone, with a peak writing throughput measured in GB/s. For monitoring and alerting reasons, it should be available for queries immediately after being ingested.
- Large amount of historical data: For a single availability zone, the size of historical data can be as large as a hundred TB or a trillion rows. Of this huge volume, different data types require different retention duration, so the ability to set an expiration date for different batches is important.
- Schemaless data: To adapt to different observed objects, the data field properties should be able to change dynamically, and engineers should be able to relate the fields to various types of data flexibly.
Why did they choose VeloDB?
Considering the above requirements, Guance put its two major workloads into separate systems: metric data was stored in their self-developed metric engine: GuanceDB, while logs and other records were stored in Elasticsearch. Problems included:
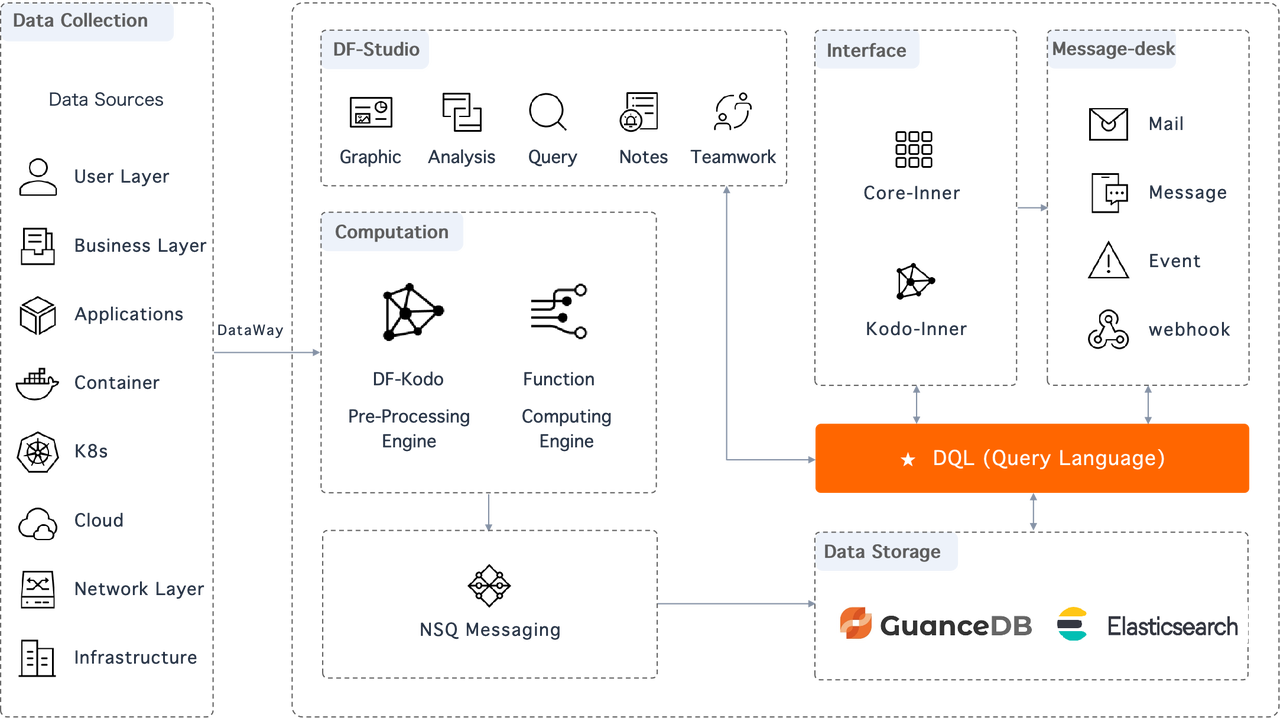
- Elasticsearch produced high CPU and memory overheads, and it was costly just to keep the huge bulk of historical data around. With the current storage design in Elasticsearch, they often encountered accuracy issues in queries.
- Engineers needed to spend extra efforts in maintaining cluster stability under high cluster loads. Due to the limit on shard numbers, engineers often had to step in and make adjustments.
- Mapping was a headache. Fields had their own lifecycles, but the Elasticsearch limit on the total number of fields made it hard to add new fields. Plus, the data type of a field was immutable once the field was created, which often results in conflicts.
With VeloDB, all these problems become a thing of the past.